

torchpipe: Pytorch内的多线程计算并行库
电子说
描述
云端深度学习的服务的性能加速通常需要算法和工程的协同加速,需要模型推理和计算节点的融合,并保证整个“木桶”没有太明显的短板。
如何在满足时延前提下让算法工程师的服务的吞吐尽可能高,尽可能简便成了性能优化的关键一环。为了解决这些问题,TorchPipe通过深入PyTorch的C++计算后端和CUDA流管理,以及针对多节点的领域特定语言建模,对外提供面向PyTorch前端的线程安全函数接口,对内提供面向用户的细粒度后端扩展。
背景
深度学习的Serving面临多个难题:
一是GIL锁带来的多线程使用受限
二是cpu-gpu异构设备开销和复杂性
三是复杂流程
业界有一些实践,如triton inference server, 阿里妈妈high_service, 美团视觉GPU推理服务部署架构优化实践。总体上,有以下方向去做这些事情:
全流程gpu化
DAG的并行化
对于cpu计算后端,去克服GIL锁
通常用户对于trinton inference server的一个抱怨是,在多个节点交织的系统中,有大量业务逻辑在客户端完成,通过RPC调用服务端,很麻烦;而为了性能考虑,不得不考虑共享显存,ensemble,BLS[5]等非常规手段。
一. 问题定义
对于我们自己来说,面临的第一个问题是,pytorch 中如何并发调用resnet18模型。本项目开始于一个简单的需求,即我们需要求得一个 X,能够实现模型推理并满足:
前向接口需要是线程安全的。
在主要硬件平台(如 NVIDIA GPU)以及主要通用加速引擎(如 TensorRT/Libtorch)上实现了此 X。
import torch, X
resnet18 = X(model="resnet18_-1x3x224x224.onnx", # 动态尺度
precision="fp16",
max=4, # 动态batch模型的最大batch数目
instance_num=4, # 多个并行计算实例
batching_timeout=5) # 凑batch超时时间
data = torch.from_numpy(data)
net_output: torch.Tensor = resnet18(data=data) # 线程安全调用
以此为起点,我们扩展到了对以下场景的支持:
包含前处理在内的通用计算后端X的细粒度泛型扩展
多节点组成的有向无环图(DAG)的流水线并行,多级结构化
条件控制流
二. 背景知识
首先,我们介绍一些背景知识。您也可以跳过这一部分。
2.1 CUDA: 流和并发
CUDA提供了一致的抽象,来控制并发访问,以便用户最大化、完整地利用单块GPU设备的资源能力。为了最有效的使用GPU设备,我们希望:
- 单位硬件资源能承载更多的业务请求量
- GPU尽可能满载(前提:关联资源使用量小,时延达标)
为了达到此目的,我们简单分析下CUDA的编程模型。
硬件
Cuda Core是显卡主要的运算单元。 采用Pascal及以上架构的显卡拥有上千的CUDA核心,对应着多组SM(Streaming Multiprocessor),可共用于一个任务,也可承载不同的运算任务。从volta架构开始,NVIDIA引入了专为深度学习设计的Tensor Core. 在Turing架构的 Tesla T4中,一共有40个SM, 共享6MB的L2缓存。一个SM由64个FP32 算数单元,和8个Tensor Core组成。对于模型的算子级优化,需要关注较为底层的优化。而对于业务使用场景,既需要算子级优化(选取针对性的计算后端负责),也需要整体视角的分析。
参考链接: GPU Architecture.
CUDA流
CUDA流表示一个GPU操作队列,所有提交给GPU的任务,均指定了执行流。存在一个默认流,也就是`stream 0`, 作为默认的队列。`提交任务`这个操作本身可以是异步的,对流进行同步化,则意味着需要阻塞cpu线程,直至所有已经提交至该队列中的任务执行完毕。不同流之间的任务可以借助硬件的不同单元并行执行或者时分并发执行。
CUDA上下文(CUDA Context)
CUDA-Stream/CUDA-Context可以类比于线程/进程:多线程分配调用的GPU资源同属一个CUDA Context下,有自己的隔离的地址空间,资源不能跨Context共享。 默认情况下,一个进程中,在初次调用CUDA runtime软件库中的任何一个API时,会自动初始化当前进程中唯一的一个CUDA上下文。GPU在同一时刻只能切换到一个context,而默认情况下一个进程有一个上下文,故多个进程使用GPU,无法同时利用硬件。
虚拟化
由于GPU无法同时执行跨CUDA context的任务,导致硬件利用率可能不高,此时可采用一些虚拟化手段。典型的如NVIDIA官方的MPS(Multi Process Service),它实际上启动了一个独立进程去转发所有的任务。采用此方法的坏处是隔离性收到了一定破坏:一旦此进程失效,所有关联任务都将受到影响。
为了充分利用GPU的性能,可以采取一些措施:
- GPU任务合理分配到多个流,并只在恰当时机同步;
- 将单个显卡的任务限制在单个进程中,去克服CUDA上下文分时特性带来的资源利用率可能不足的问题。
2.2 PyTorch CUDA 语义
PyTorch 以易用性为核心,按照一致的原则组织了对GPU资源的访问。
当前流
在PyTorch内,当前流(current stream)指的是当前线程绑定的CUDA流。PyTorch通过以下API提供了绑定CUDA流到当前线程,以及获取当前线程绑定的CUDA流的功能:
torch.cuda.set_stream(stream) torch.cuda.current_stream(device=None)默认情况下,所有线程都绑定到默认流(stream 0)上. PyTorch的GPU运算均提交到当前线程绑定的`当前流`上。PyTorch尽量让用户感知不到这点: - 通常来说,当前流是都是默认流,而在同一个流上提交的任务会按提交时间串行执行; - 对于涉及到将GPU数据拷贝到CPU或者另外一块GPU设备的操作, PyTorch默认地在操作中插入当前流的同步操作 . 为了在多线程环境使得PyTorch充分利用GPU资源,我们需要打破以上惯例:
计算后端线程绑定到独立的CUDA流;
在线程转换时进行流同步
三. 单节点的并行化
3.1 resnet18 计算加速
对于onnx格式的 resnet18的模型resnet18_-1x3x224x224.onnx, 通常有以下手段进行推理加速:
使用tensorrt等框架进行模型针对性加速
避免频繁显存申请
多实例,batching,分别用来提高资源使用量和使用效率
优化数据传输
线程安全的本地推理
为了方便,假设将tensorrt推理功能封装为名称为 TensorrtTensor 的计算后端。由于计算发生在gpu设备上,我们加上SyncTensor 表示gpu上的流同步操作。
| 配置项 | 参数 | 说明 |
| backend | "SyncTensor[TensorrtTensor]" | 计算后端和tensorrt推理本身一样,不是线程安全的。 |
| max | 4 | 模型支持的最大batchsize,用于模型转换(onnx->tensorrt) |
torchpipe默认会在此计算后端上包裹一层可扩展的单节点调度后端,实现以下三个基本能力:
前向接口线程安全性
多实例并行
| 配置项 | 默认值 | 说明 |
| instance_num | 1 | 多个模型实例并行执行推理任务。 |
Batching
对于resnet18, 模型本身输入为-1x3x224x224, batchsize越大,单位硬件资源所完成的任务越多。batchsize 从计算后端(TensorrtTensor)读取。
| 配置项 | 默认值 | 说明 |
| batching_timeout | 0 | 单位为毫秒,在此时间内如果没有接收到 batchsize 个数目的请求,则放弃等待。 |
性能调优技巧
汇总以上步骤,我们获得推理resnet18在torchpipe下的必要参数:
import torchpipe as tp
import torch
config = {
# 单节点调度器参数:
"instance_num":2,
"batching_timeout":5,
# 计算后端:
"backend":"SyncTensor[TensorrtTensor]",
# 计算后端参数:
"model":"resnet18_-1x3x224x224.onnx",
"max":4
}
# 初始化
models = tp.pipe(config)
data = torch.ones(1,3,224,224).cuda()
## 前向
input = {"data":data}
models(input) # <== 可多线程调用
result: torch.Tensor = input["result"] # 失败则 "result" 不存在
假设我们想要支持最多10路的客户端/并发请求, instance_num 一般设置2,以便最多有处理 instance_num*max = 8 路的能力。
性能取舍 请注意,我们的加速做了如下假设: 同设备上的数据拷贝(如cpu-cpu数据拷贝,gpu-gpu同一显卡内部显存拷贝)速度快,消耗资源少,整体上可忽略不计。 相对于cpu-gpu数据拷贝以及其他的计算,这条假设是没问题的。后面我们将看到,在一些特殊场景,这条假设可能不成立,需要相应的规避手段。
3.2 计算后端
在深度学习的服务中,如果仅支持模型加速远远不够。为此,我们内置了一些常用的细粒度后端。
内置后端举例:
| 名称 | 说明 |
| DecodeMat | jpg解码 |
| cvtColorMat | 颜色空间转换 |
| ResizeMat | resize |
| PillowResizeMat | 严格保持和pillow的结果一致的resize |
| 更多... |
| 名称 | 说明 |
| DecodeTensor | GPU上jpg解码 |
| cvtColorTensor | 颜色空间转换 |
| ResizeTensor | resize |
| PillowResizeTensor | 严格保持和pillow的结果一致的resize |
| 更多... |
3.3 Sequential
Sequential 能串联多个后端。也就是说,Sequential[DecodeTensor,ResizeTensor,cvtColorTensor,SyncTensor] 和 Sequential[DecodeMat,ResizeMat] 是有效后端。
在 Sequential[DecodeMat,ResizeMat] 的前向执行中,数据(dict)会依次经过下列流程:
执行 DecodeMat:DecodeMat读取data, 并将结果赋值给result和color
条件控制流:尝试将数据中的result的值赋值给data 并删除result
执行 ResizeMat :ResizeMat读取data, 并将结果赋值给result键值
Sequential可简写为S.
3.4 单节点调度系统
输入数据经由默认的单节点调度系统BaselineSchedule分发给计算后端执行。在此过程中主要经历了凑batch和多实例的调度。
凑batch/多实例
对于TensorrtTensor等模型推理引擎,输入范围一般是[1, max_batch_size], 此时调度系统可将输入数据打包送入。BaselineSchedule单节点调度后端实现了如下的调度功能:
根据instance_num参数启动多个计算后端实例
从计算后端读取max_batch_size=max(), 如果大于1,启动凑batch功能
从输入队列获取数据,在batching_timeout的时间内,如果获得了max_batch_size个数据,那么将其送往Batch队列, 如果时间到了仍然没有获得足够数据,那么将已有数据送入Batch队列
将任务从Batch队列中分发到空闲的计算实例中。
以上是主干的大致流程,细节部分会有差别,如BaselineSchedule也实现了基础的自适应流量功能,根据多实例计算引擎的状态决定batch状态的功能,以及组合调度的功能。
单节点组合调度
有些计算后端的输入范围最小值大于1, 导致无法作为正常的后端进行调度(可能导致有些数据永远没有办法进行处理)。BaselineSchedule通过&符号提供了组合的能力。
举例来讲,对于TensorrtTensor后端,一些模型不方便转为动态模型, 此时可以用一个 batchsize=1 的模型和几个 batchsize=N 的模拟动态batch.
[model] model="batch1.onnx&batch4.onnx&batch8.onnx" backend="SyncTensor[TensorrtTensor]" # or 'SyncTensor[TensorrtTensor]&SyncTensor[TensorrtTensor]' instance_num = 2 # auto extend to '2&2&2' min="1&4&8" max="1&4&8"
此时,将共有6个实例,前两个实例输入范围均是[1, 1],中间两个均是[4, 4],最后两个均是[8, 8]。对BaselineSchedule来说,这六个实例组成了两个虚拟实例,每个虚拟实例占用了三个实例,虚拟实例的输入范围是[1, 8].
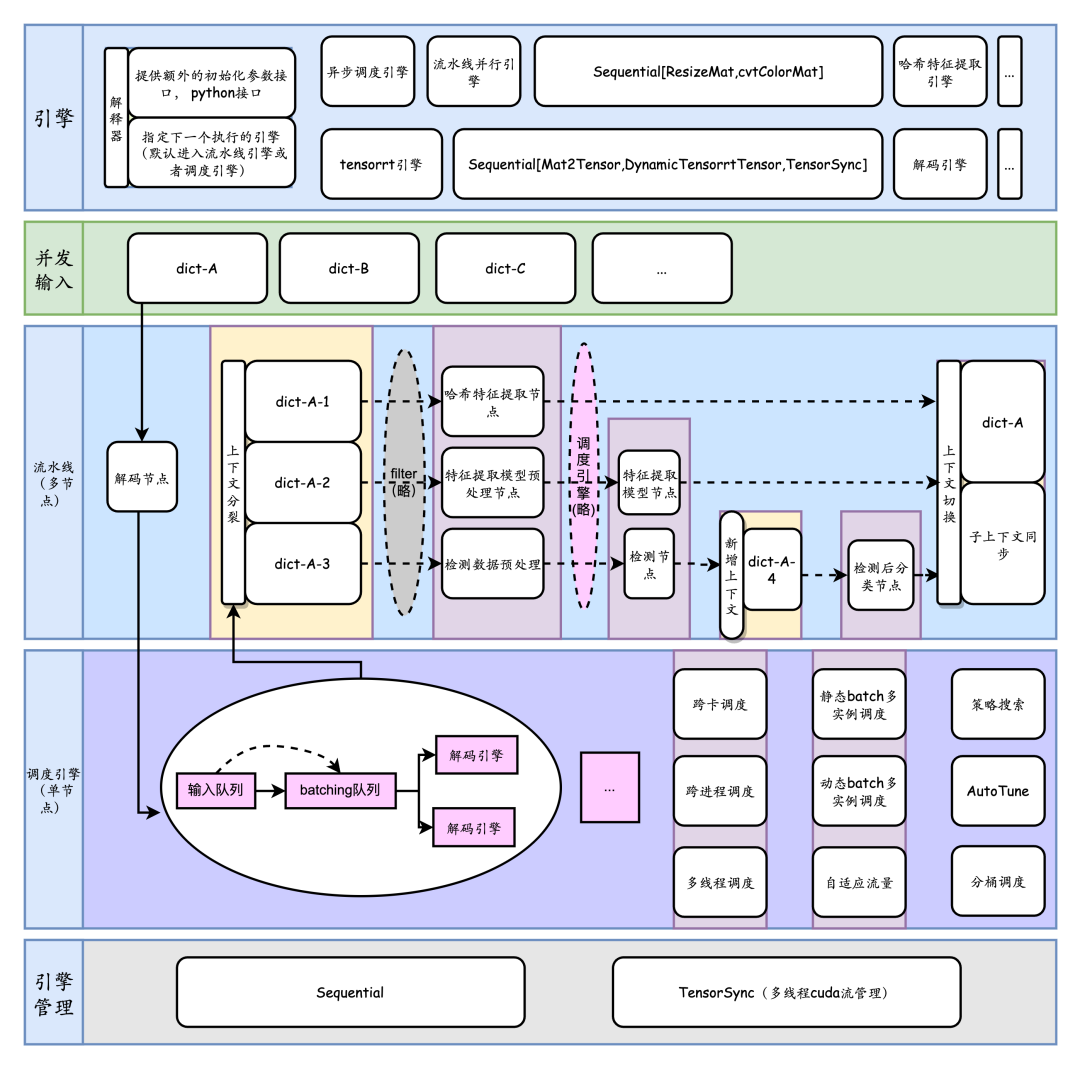
四. 多节点调度
针对多节点,主要考虑了:
多个节点的链接, filter: 有向无环图中的条件控制流, context: 自动map语法糖, 图的跳转, 逻辑节点。
五. RoadMap
torchpie目前处于一个快速迭代阶段,我们非常需要你的帮助。欢迎通过issues或者反馈等方式帮助我们。 我们的最终目标是让服务端高吞吐部署尽可能简单。为了实现这一目标,我们将积极自我迭代,也愿意参与有相近目标的其他项目。
2023年度和2024年度 RoadMap
大模型方面的示例
公开的基础镜像和pypi(manylinux)
优化编译系统,分为core,pplcv,model/tensorrt,opencv等模块
基础结构优化。包含python与c++交互,异常,日志系统,跨进程后端的优化;
技术报告
潜在未完成的研究方向
单节点调度和多节点调度后端,他们与计算后端无本质差异,需要更多面向用户进行解耦,我们想要将这部分优化为用户API的一部分;
针对多节点的调试工具。由于在多节点调度中,使用了模拟栈设计,比较容易设计节点级别的调试工具;
负载均衡
审核编辑:汤梓红
-
java实现多线程的几种方式2024-03-14 2255
-
多线程如何保证数据的同步2023-11-17 2698
-
Java多线程的用法2023-09-30 2258
-
什么是并行多线程实时处理器?MC3172开发环境开发实践2023-09-19 1653
-
labview AMC多线程2023-08-21 826
-
Python多线程的使用2023-03-17 1862
-
并行多线程处理器MC31722022-08-19 1922
-
大小核的OpenMP多线程并行计算测试2019-05-04 5760
-
多线程的并行实例恢复方法2017-12-20 961
-
多线程好还是单线程好?单线程和多线程的区别 优缺点分析2017-12-08 83600
-
MFC下的多线程编程2016-09-01 786
-
LabView的多线程语言2009-06-08 10751
全部0条评论

快来发表一下你的评论吧 !
