

如何将Kafka使用到我们的后端设计中
描述
本文介绍了以下内容:
1.什么是Kafka?
2.为什么我们需要使用Kafka这样的消息系统及使用它的好处
3.如何将Kafka使用到我们的后端设计中。
译自timber.io:《hello-world-in-kafka-using-python》,有部分删改。
1.Kafka是什么、为什么我们需要它?
简而言之,Kafka是一个分布式消息系统。这是什么意思呢?
想象一下,你现在有一个简单的Web应用,其包含了网页前端客户端(Client)、服务端和数据库:
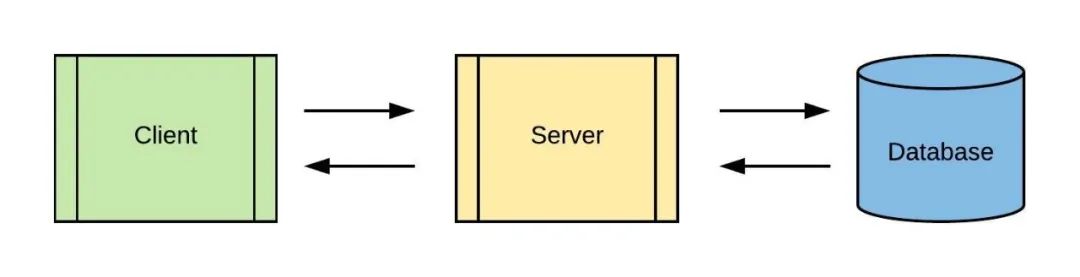
你需要记录所有发生在你的Web应用的事件,比如点击、请求、搜索等,以便后续进行计算和运营分析。
假设每个事件都由单独的APP完成,那么一个简单的解决方案就是将数据存储在数据库中,所有APP连接到数据库进行存储:

这看起来简单,但是其中还会出现许多问题:
1.点击、请求、搜索等事件会产生大量的数据到数据库中,这可能会导致插入事件存在延迟。
2.如果选择将高频数据存储在SQL或MongoDB等数据库中,很难再原有历史数据的基础上扩展数据库。
3.如果你需要用这些数据进行数据分析,你可能无法直接对数据库进行高频率的读取操作。
4.每个APP可以遵循自己的数据格式,这就意味着当你需要在不同的APP进行数据交换时,你需要进行数据格式的转换。
通过使用像Kafka这样的消息流系统,可以很好地解决这些问题,因为他们可以执行以下操作:
1.存储的大量数据可以被持久化、校验和复制,具备容错能力。
2.支持跨系统实时处理连续的数据流。
3.允许APP独立发布数据或数据流,并与使用它的APP无关。
那么它和传统数据库有何不同?
尽管Kafka可以持久化地存储数据,但它不是数据库。
Kafka不仅允许APP存储或提取连续的数据流,还支持实时处理。这与对被动数据执行CRUD操作或对传统数据库执行查询的方式不同。
听起来不错,那么Kafka是如何解决以上挑战的?
Kafka是一个分布式平台,是为规模而构建的,这意味着它可以处理高频率的读写和存储大量数据。它确保数据始终可靠。它还支持从故障中恢复的强大机制。
以下是为什么应该使用Kafka的一些关键因素:
1.1 简化后端架构
在Kafka的帮助下,我们前面的结构会变得简单一些:

1.2 通用数据管道
如上所示,Kafka充当多个APP和服务的通用数据管道,这给了我们两个好处:
1.数据是集成的,我们将来自不同系统的数据都存在一个地方,这使得Kafka成为真正的数据源。任何APP都可以将数据推送到该平台,然后由另一个APP提取数据。
2.Kafka使得应用程序之间交换数据变得容易。因为我们可以标准化数据格式,减少了数据格式的转换。
1.3 通用连接性
尽管Kafka允许你使用标准数据格式,但并不意味着你的APP就不需要数据转换了,它只是减少了我们转换数据的频率罢了。
此外,Kafka提供了一个叫 Kafka Connect 的框架允许我们维护遗留的老系统。
1.4 实时数据处理
类似于监控系统这样的实时APP,往往需要连续的数据流,这些数据需要被立即处理或尽量减少延迟处理。
Kafka的流式处理,使得处理引擎可以在很短的时间内(几毫米到几分钟)内取数、分析、以及响应。
2.Kafka入门
2.1 安装
安装Kafka是一个相当简单的过程。只需遵循以下给定步骤:
1.下载最新的1.1.0版本的Kafka
2.使用以下命令解压缩下载文件: tar -xzf kafka_2.11-1.1.0.tgz
3.cd到Kafka目录开始使用它: cd kafka_2.11-1.1.0
2.2 启动服务器
ZooKeeper是一个针对Kafka等分布式环境的集中管理工具,它为大型分布式系统提供配置服务、同步服务及命名注册表。
因此,我们需要先启动ZooKeeper服务器,然后再启动Kafka服务器。使用以下命令即可:
# Start ZooKeeper Server
bin/zookeeper-server-start.sh config/zookeeper.properties
# Start Kafka Server
bin/kafka-server-start.sh config/server.properties
2.3 Kafka 基本概念
我们快速介绍一下Kafka体系结构的核心概念:
1.Kafka在一个或多个服务器上作为集群运行。
2.Kafka将数据流存储在名为topics的类别中。每条数据均由键、值、时间戳组成。
3.Kafka使用发布-订阅模式。它允许某些APP充当producers(生产者),记录数据并将数据发布到Kafka topic中。
同样,它允许某些APP充当consumer(消费者)和订阅Kafka topic并处理由它产生的数据。
4.除了Prodcuer API 和 Consumer API,Kafka还为应用提供了一个 Streams API 作为流处理器。通过 Connector API 我们可以将Kafka连接到其他现有的应用程序和数据系统。
2.4 架构

如你所见,每个Kafka的 Topic 可以分为多个Partition(分区),可以使用broker(经纪人)在不同的计算机上复制这些 Topic,从而使消费者可以并行读取 Topic.
kafka的复制是针对分区的:

比如上图中有4个broker, 1个topic, 2个分区,复制因子是3。当producer发送一个消息的时候,它会选择一个分区,比如topic1-part1分区,将消息发送给这个分区的leader, broker2、broker3会拉取这个消息,一旦消息被拉取过来,slave会发送ack给master,这时候master才commit这个log。
因此,整个系统的容错级别极高。当系统正常运行时,对Topic的所有读取和写入都将通过leader,且leader会保证所有其他broker均被更新。
如果Broker失效了,系统会自动重新配置,此时副本也可以接管成为Leader.
2.5 创建Kafka Topic
让我们创建一个名为 sample,含有一个partition(分区)和一个replica(副本)的Kafka Topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic sample
列出所有的Kafka Topics,检查是否成功创建了sample Topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181
describe topics 命令还可以获得特定Topic的详细信息:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic sample
2.6 创建生产者与消费者
这里是本章的代码实战部分,利用Kafka-Python实现简单的生产者和消费者。
1.首先需要安装kafka-python:
pip install kafka-python
2.创建消费者(consumer.py)
from kafka import KafkaConsumer
consumer = KafkaConsumer('sample')
for message in consumer:
print (message)
3.创建生产者(producer.py)
有一个消费者正在订阅我们的消息流,因此我们要创建一个生产者,发布消息到Kafka:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('sample', b'Hello, World!')
producer.send('sample', key=b'message-two', value=b'This is Kafka-Python')
现在,你重新运行消费者(consumer.py),你就会接收到生产者发送过来的消息。
-
Standard cell是怎么应用到我们的后端设计中的呢?2023-12-04 2897
-
如何将1-Wire主机复用到多个通道?2023-10-29 1457
-
如何将大模型应用到效能评估系统中去2023-09-27 1312
-
如何将ESP32置于认证过程所需的模式中?2023-03-01 682
-
IDE如何将外围头文件包含在我的项目中并连接到我的项目?2023-02-07 546
-
如何将RAFL添加到我的项目的适当示例和/或文档?2023-01-10 696
-
如何将UDESTK的调试屏幕添加到我的SPC5上呢2022-12-20 608
-
请问如何将Swift语言应用到MCU开发中?2022-02-11 1026
-
如何将转换器设计指标应用到 Fly-Buck 电路设计中2022-01-28 2659
-
如何将物联网数据从设备连接到Kafka集群?2020-07-20 2487
-
如何将DRIVEDONE属性传播到我的mcs文件生成?2020-06-04 1949
-
探讨如何将机器学习应用到物联网中2018-05-23 10419
-
如何将MCU应用到FPGA中:关于FPGA(1)2018-05-08 4371
-
如何将LCD运用到低通滤波电路里2011-11-02 3656
全部0条评论

快来发表一下你的评论吧 !
