

什么格式是保存Pandas数据的最好格式
描述
在数据分析相关项目工作时,我通常使用Jupyter笔记本和pandas库来处理和传递我的数据。对于中等大小的数据集来说,这是一个非常直接的过程,你甚至可以将其存储为纯文本文件而没有太多的开销。
然而,当你的数据集中的观测数据数量较多时,保存和加载数据回内存的过程就会变慢,现在程序的重新启动都会迫使你等待数据重新加载。所以最终,CSV文件或任何其他纯文本格式都会失去吸引力。
我们可以做得更好。有很多二进制格式可以用来将数据存储到磁盘上,其中有很多格式pandas都支持。我们怎么能知道哪一种更适合我们的目的呢?
来吧,我们尝试其中的几个,然后进行对比!这就是我决定在这篇文章中要做的:通过几种方法将 pandas.DataFrame 保存到磁盘上,看看哪一种在I/O速度、内存消耗和磁盘空间方面做的更好。
在这篇文章中,我将展示我的测试结果。
1.要比较的格式
我们将考虑采用以下格式来存储我们的数据:
- CSV -- 数据科学家的一个好朋友
- Pickle -- 一种Python的方式来序列化事物
- MessagePack -- 它就像JSON,但又快又小
- HDF5 -- 一种设计用于存储和组织大量数据的文件格式
- Feather -- 一种快速、轻量级、易于使用的二进制文件格式,用于存储数据框架
- Parquet -- Apache Hadoop的柱状存储格式
所有这些格式都是被广泛使用的,而且(也许除了MessagePack)在你做一些数据分析的事情时非常经常遇到。
为了追求找到最好的缓冲格式来存储程序会话之间的数据,我选择了以下指标进行比较。
- size_mb - 文件大小(Mb)。
- save_time - 将数据帧保存到磁盘上所需的时间量。
- load_time - 将之前转储的数据帧加载到内存中所需要的时间量。
- save_ram_delta_mb - 数据帧保存过程中最大的内存消耗增长量。
- load_ram_delta_mb - 数据帧加载过程中的最大内存消耗增长量。
请注意,当我们使用高效压缩的二进制数据格式,如 Parquet 时,最后两个指标变得非常重要。它们可以帮助我们估计加载序列化数据所需的内存量,此外还有数据大小本身。我们将在接下来的章节中更详细地讨论这个问题。
2.测试及结果
我决定使用一个合成数据集进行测试,以便更好地控制序列化的数据结构和属性。
另外,我在我的基准中使用了两种不同的方法:
(a) 将生成的分类变量保留为字符串。
(b) 在执行任何I/O之前将它们转换为 pandas.Categorical 数据类型。
函数generate_dataset显示了我在基准中是如何生成数据集的:
def generate_dataset(n_rows, num_count, cat_count, max_nan=0.1, max_cat_size=100):
"""
随机生成具有数字和分类特征的数据集。
数字特征取自正态分布X ~ N(0, 1)。
分类特征则被生成为随机的uuid4字符串。
此外,数字和分类特征的max_nan比例被替换为NaN值。
"""
dataset, types = {}, {}
def generate_categories():
from uuid import uuid4
category_size = np.random.randint(2, max_cat_size)
return [str(uuid4()) for _ in range(category_size)]
for col in range(num_count):
name = f'n{col}'
values = np.random.normal(0, 1, n_rows)
nan_cnt = np.random.randint(1, int(max_nan*n_rows))
index = np.random.choice(n_rows, nan_cnt, replace=False)
values[index] = np.nan
dataset[name] = values
types[name] = 'float32'
for col in range(cat_count):
name = f'c{col}'
cats = generate_categories()
values = np.array(np.random.choice(cats, n_rows, replace=True), dtype=object)
nan_cnt = np.random.randint(1, int(max_nan*n_rows))
index = np.random.choice(n_rows, nan_cnt, replace=False)
values[index] = np.nan
dataset[name] = values
types[name] = 'object'
return pd.DataFrame(dataset), types
我们将CSV文件的保存和加载性能作为一个基准。
五个随机生成的具有一百万个观测值的数据集被转储到CSV中,并读回内存以获得平均指标。
每种二进制格式都针对20个随机生成的具有相同行数的数据集进行测试。
这些数据集包括15个数字特征和15个分类特征。你可以在这个资源库中找到带有基准测试功能和所需的完整源代码:
https://github.com/devforfu/pandas-formats-benchmark
或在Python实用宝典后台回复 **Pandas IO对比 **,下载完整代码。
(a) 数据为字符串特征时的性能
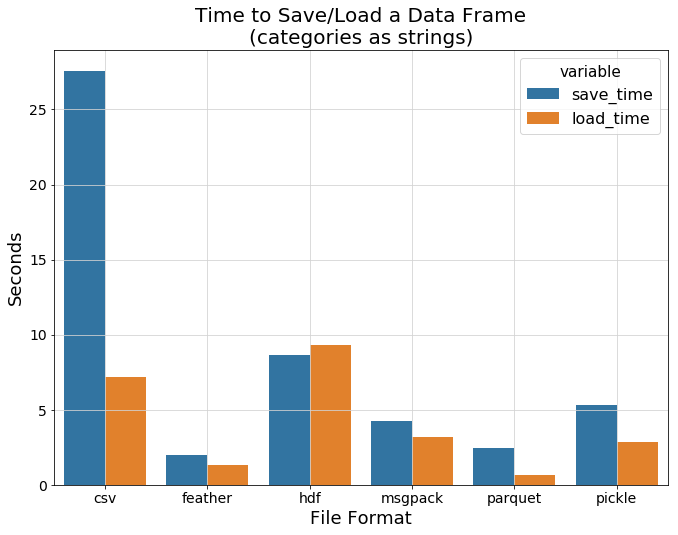
下图显示了每种数据格式的平均I/O时间。一个有趣的观察是,hdf显示出比csv更慢的加载速度,而其他二进制格式的表现明显更好。其中最令人印象深刻的是feather和parquet。
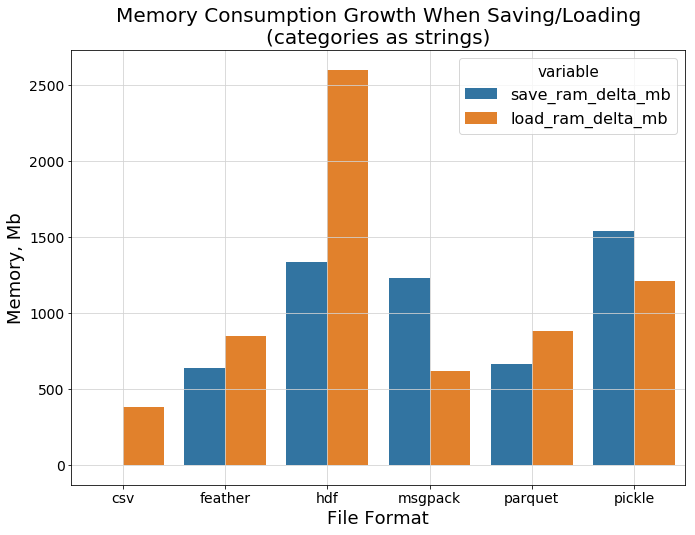
在保存数据和从磁盘上读取数据时,内存开销如何?
下一张图片告诉我们,hdf 的表现就不是那么好了。可以肯定的是,csv在保存/加载纯文本字符串时不需要太多的额外内存,而Feather和parquet则相当接近:
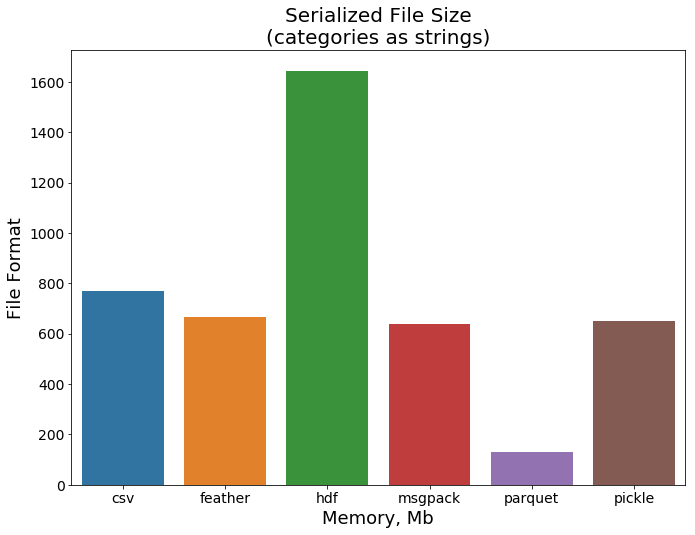
最后,让我们看看文件的大小。这次parquet显示了一个令人印象深刻的结果,考虑到这种格式是为有效存储大量数据而开发的,这并不令人惊讶。
(b) 字符串特征转换为数字时的性能
在上一节中,我们没有尝试有效地存储我们的分类特征而是使用普通的字符串。让我们来弥补这个遗漏吧! 这一次我们使用一个专门的 pandas.Categorical 类型,转字符串特征为数字特征。
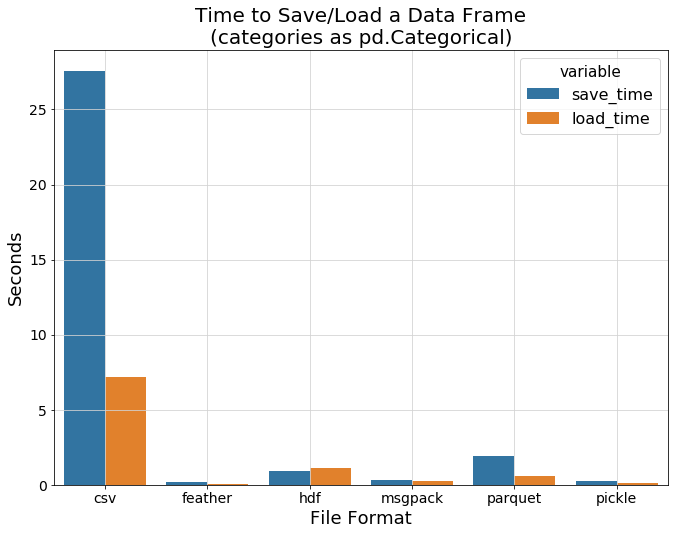
看看现在与纯文本的csv相比,它看起来如何!
现在所有的二进制格式都显示出它们的真正力量。Csv的基准结果已经远远落后了,所以让我们把它去掉,以便更清楚地看到各种二进制格式之间的差异:
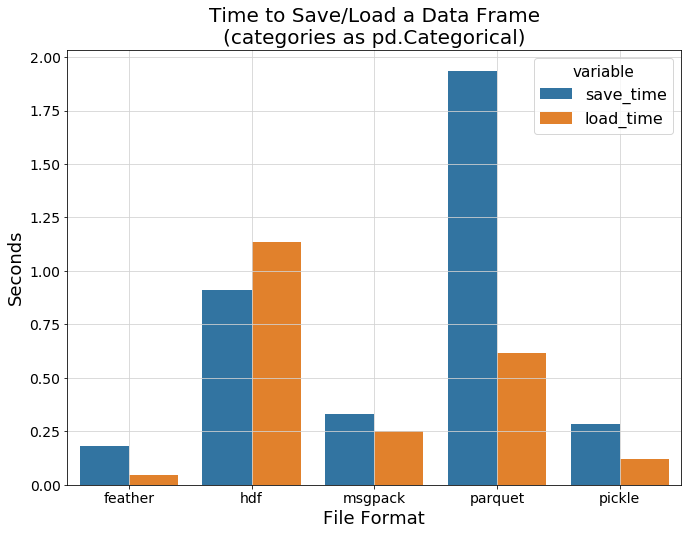
Feather 和 Pickle 显示了最好的 I/O 速度,而 hdf 仍然显示了明显的性能开销。
现在是时候比较数据进程加载时的内存消耗了。下面的柱状图显示了我们之前提到的关于parquet格式的一个重要事实。
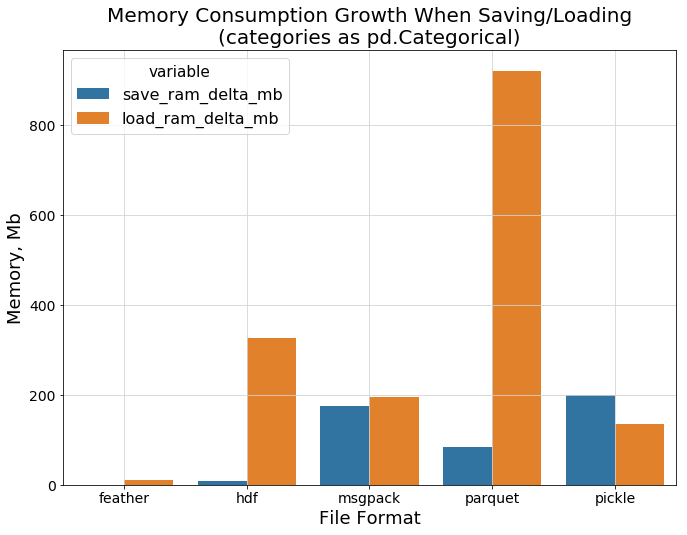
可以看到 parquet 读写时的内存空间差距有多大,你有可能你无法将比较大的 parquet 文件加载到内存中。
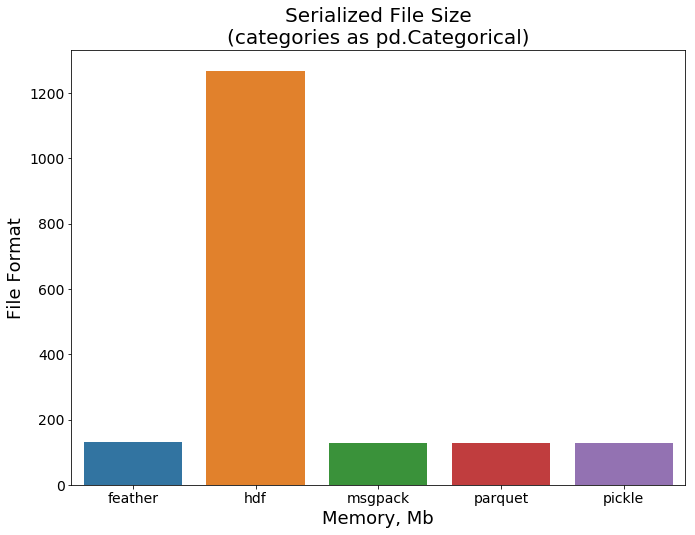
最后的图显示了各格式的文件大小。所有的格式都显示出良好的效果,除了hdf仍然需要比其他格式多得多的空间:
3.结论
正如我们的测试所显示的,似乎 feather 格式是存储Python会话数据的理想候选者。它显示了很快的I/O速度,在磁盘上不占用太多内存,并且在加载回RAM时不需要消耗太大的内存。
当然,这种比较并不意味着你应该在每个可能的情况下使用这种格式。例如,feather格式一般不会被用作长期文件存储的格式。
另外,某些特定情况下也无法使用 feather,这由你的整个程序架构决定。然而,就如本帖开头所述的目的,它在不被任何特殊事项限制的情况下是一个很好的选择。
-
RGB888格式的image怎么保存jpg格式?2025-04-25 396
-
Labview存储数据格式和怎么保存桌面2012-04-07 2956
-
输入并保存txt格式的文件2015-03-31 3254
-
数据格式,计算机中数据格式详细介绍2010-04-13 4071
-
gps数据格式含义说明2011-12-19 13898
-
格式化对硬盘有伤害吗_硬盘格式化后数据还能恢复吗2017-12-14 18310
-
java生成json格式数据 和 java遍历json格式数据2018-03-19 997
-
Apollo与GPS串口通信的数据格式2018-10-20 7478
-
更高效的利用Jupyter+pandas进行数据分析2021-03-12 2343
-
Cx51用户指南之数据存储格式数据存储格式2021-12-13 984
-
浅谈CAN错误帧格式2022-09-29 1716
-
WAV文件格式详解2023-10-21 16069
-
Pandas:Python中最好的数据分析工具2023-10-31 1481
-
Pandas DataFrame的存储格式性能对比2023-11-03 1390
-
态势数据有哪些格式2024-06-24 1179
全部0条评论

快来发表一下你的评论吧 !
