

pandas中合并数据的5个函数
描述
今天借着这个机会,就为大家盘点一下pandas中合并数据的5个函数。
join
join是基于索引的横向拼接,如果索引一致,直接横向拼接。如果索引不一致,则会用Nan值填充。
索引一致
x = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=[0, 1, 2])
y = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=[0, 1, 2])
x.join(y)
结果如下:

索引不一致
x = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=[0, 1, 2])
y = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=[1, 2, 3])
x.join(y)
结果如下:

merge
merge是基于指定列的横向拼接,该函数类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
- 可以指定不同的how参数,表示连接方式,有inner内连、left左连、right右连、outer全连,默认为inner;
x = pd.DataFrame({'姓名': ['张三', '李四', '王五'],
'班级': ['一班', '二班', '三班']})
y = pd.DataFrame({'专业': ['统计学', '计算机', '绘画'],
'班级': ['一班', '三班', '四班']})
pd.merge(x,y,how="left")
结果如下:

concat
concat函数既可以用于横向拼接,也可以用于纵向拼接。
纵向拼接
x = pd.DataFrame([['Jack','M',40],['Tony','M',20]], columns=['name','gender','age'])
y = pd.DataFrame([['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
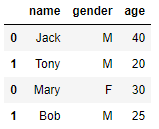
z = pd.concat([x,y],axis=0)
z
结果如下:
横向拼接
x = pd.DataFrame({'姓名': ['张三', '李四', '王五'],
'班级': ['一班', '二班', '三班']})
y = pd.DataFrame({'专业': ['统计学', '计算机', '绘画'],
'班级': ['一班', '三班', '四班']})
z = pd.concat([x,y],axis=1)
z
结果如下:

append
append主要用于纵向追加数据。
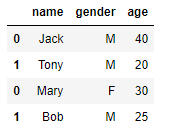
x = pd.DataFrame([['Jack','M',40],['Tony','M',20]], columns=['name','gender','age'])
y = pd.DataFrame([['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
x.append(y)
结果如下:
combine
conbine可以通过使用函数,把两个DataFrame按列进行组合。
x = pd.DataFrame({"A":[3,4],"B":[1,4]})
y = pd.DataFrame({"A":[1,2],"B":[5,6]})
x.combine(y,lambda a,b:np.where(a>b,a,b))
结果如下:

注:上述函数,用于返回对应位置上的最大值。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Pandas中的四种绘图函数2019-09-04 3650
-
从Excel到Python-最常用的36个Pandas函数2020-12-10 1345
-
Python工具pandas筛选数据的15个常用技巧2021-03-30 3929
-
盘点Pandas的100个常用函数2021-04-01 3786
-
数据处理中pandas的groupby小技巧2021-04-09 3203
-
分享pandas中超级好用的str矢量化字符串函数2021-04-13 3536
-
解读12 种 Numpy 和 Pandas 高效函数技巧2021-06-29 2216
-
5个必须知道的Pandas数据合并技巧2022-04-13 3262
-
Pandas中使用Merge、Join、Concat合并数据的效率对比2022-10-25 1607
-
Pandas 50个高级、高频操作2023-04-24 1454
-
超强图解Pandas,建议收藏2023-08-29 1711
-
如何使用Python和pandas库读取、写入文件2023-09-11 2367
-
盘点66个Pandas函数合集2023-10-30 2697
-
Pandas:Python中最好的数据分析工具2023-10-31 1492
-
Pandas函数的三个接口介绍2023-11-01 1394
全部0条评论

快来发表一下你的评论吧 !
