

Cache和Write Buffer一般性介绍
电子说
描述
前言
Cache是位于CPU与主存储器即DRAM(Dynamic RAM,动态存储器)之间的少量超高速静态存储器SRAM(Static RAM),它是为了解决CPU与主存之间速度匹配问题而设置的,不能由用户直接寻址访问。
随着科技的发展和生产工艺水平的提高,高性能处理器中Cache的容量将越来越大,而且级数将越来越多,从而大大提高系统的性能。
1 Cache和Write Buffer一般性介绍
1.1 Cache工作原理
具有Cache的计算机,当CPU需要进行存储器存取时,首先检查所需数据是否在Cache中。如果存在,则可以直接存取其中的数据而不必插入任何等待状态,这是最佳情况,称为高速命中;
当CPU所需信息不在Cache中时,则需切换存取主储器,由于速度较慢,需要插入等待,这种情况称高速未命中;
在CPU存取主存储器的时候,按照最优化原则将存储信息同时写入到Cache中以保证下次可能的高速缓存命中。
因此 ,同一数据可能同时存储在主存储器和Cache中 。同样,按照优化算法, 可以淘汰Cache中一些不常使用的数据 。
传统的Socket架构通常采用两级缓冲结构,即在CPU中集成了一级缓存(L1Cache),在主板上装二级缓存(L2 Cache),而SlotⅠ架构下的L2 Cache则与CPU做在同一块电路板上,以内核速度或者内核速度的一半运行,速度比Socket下的以系统外频运行的L2 Cache更快,能够更大限度发挥高主频的优势,当然对Cache工艺要求也更高。
•CPU首先在L1 Cache中查找数据,如找不到,则在L2Cache中寻找。•若数据在L2 Cache中,控制器在传输数据的同时,修改L1Cache;•若数据既不在L1 Cache中,又不在L2 Cache中,Cache控制器则从主存中获取数据,将数据提供给CPU的同时修改两级Cache。•K6-Ⅲ则比较特殊,64KB L1 Cache,256KB Full Core Speed L2 Cache,原先主板上的缓存实际上就成了L3 Cache。
根据有关测试表明:
当512K2MB的三级缓存发挥作用时,系统性能还可以有2%10%的提高;
Tri-level成为PC系统出现以来提出的解决高速CPU与低速内存之间瓶颈最为细致复杂的方案;而且,今后Cache的发展方向也是大容。
在主存-Cache存储体系中, 所有的指令和数据都存在主存中 ,Cache只是存放主存中的一部分程序块和数据块的副本,只是一种以块为单位的存储方式。
Cache和主存被分为块,每块由多个字节组成。
由上述的程序局部性原理可知,Cache中的程序块和数据块会使CPU要访问的内容在大多数情况下已经在Cache中,CPU的读写操作主要在CPU和Cache之间进行。
CPU访问存储器时,送出访问单元的地址,由地址总线传送到Cache控制器中的主存地址寄存器MAR, 主存-Cache地址转换机构从MA获取地址并判断该单元内容是否已在Cache中存有副本 ,如果副本已存在于Cache中,即命中。当命中时,立即把访问地址变换成它在Cache中的地址,然后访问Cache。
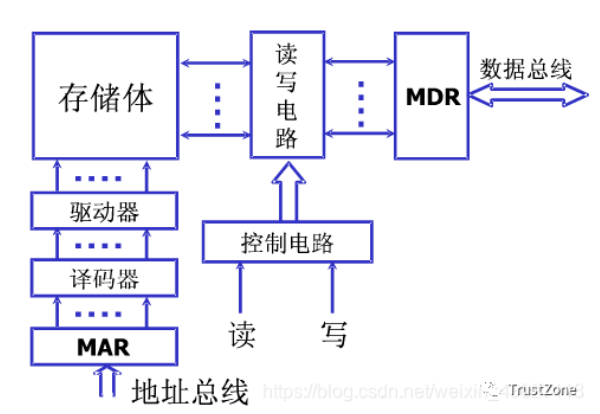
- 存储体由若跟个存储单元组成,存储单元由多个存储元件组成
- 存储体----存储单元(存储一串二进制串)----存储元件(存储一个0/1)
- 存储单元:存放一串二进制代码。
- 存储字:存储单元中的二进制代码
- 存储字长:存储单元中二进制代码位数。
- 存储单元按照地址进行寻址
- MAR:存储器地址寄存器,反应存储单元个数。保存了存储体的地址(存储单元的编号),反应了存储单元的个数。所以MAR的位数和存储单元的个数有关。
- MDR:存储器数据寄存器,反应存储字长(存储单元长度)。保存了要送入CPU中的数据或要保存到存储体中的数据或者刚刚从存储体中取出来来的数据。这个寄存器的长度和存储单元的长度相同。
如果CPU要访问的内容不在Cache中,即不命中,则CPU转去直接访问主存,并将包含此存储单元的整个数据块(包括该块数据的地址信息)传到Cache中,使得以后的若干次对内存的访问可转化为对Cache的访问。
若Cache存储器已满,则需在替换控制部件的控制下,根据某种替换算法/策略,用此块信息替换掉Cache中原来的某块信息。
之前记得当时面试的时候让我用golang手写缓存管理算法,哈哈哈。
所以,要想提高系统效率,必须提高Cache命中率 ,而Cache命中率的提高则 取决于Cache的映像方式和Cache刷新算法等一系列因素 ,同时Cache中内容应与主存中的部分保持一致,也就是说,如果主存中的内容在调入Cache之后发生了变化,那么它在Cache中的映像也应该随之发生相应改变,反之,当CPU修改了Cache中的内容后,主存中的相应内容也应作修改。
1.2 地址映像方式
所谓地址映像方式是指如何确定Cache中的内容是主存中的哪一部分的副本,即必须应用某种函数把主存地址映像到Cache中定位。
信息按某种方式装入Cache中后,执行程序时,应将主存地址变换为Cache地址,这个变换过程叫作地址变换。
地址映像方式通常采用直接映像、全相联映像、组相联映像三种:
1-直接映像
每个主存地址映像到Cache中的一个指定地址的方式,称为直接映像方式。在直接映像方式下,主存中存储单元的数据只可调入Cache中的一个位置,如果主存中另一个存储单元的数据也要调入该位置则将发生冲突。
地址映像的方法一般是将主存空间按Cache的尺寸分区,每区内相同的块号映像到Cache中相同的块位置。一般地,Cache被分为2N块,主存被分为大小为2MB的块,主存与Cache中块的对应关系可用如下映像函数表示:j = i mod 2N。式中,j是Cache中的块号;i是主存中的块号。
直接映像是一种最简单的地址映像方式,它的地址变换速度快,而且不涉及其他两种映像方式中的替换策略问题。但是这种方式的块冲突概率较高,当程序往返访问两个相互冲突的块中的数据时,Cache的命中率将急剧下降,因为这时即使Cache中有其他空闲块,也因为固定的地址映像关系而无法应用。
2-全相联映像
主存中的每一个字块可映像到Cache任何一个字块位置上,这种方式称为全相联映像。这种方式只有当Cache中的块全部装满后才会出现块冲突,所以块冲突的概率低,可达到很高的Cache命中率,但它实现很复杂。
当访问一个块中的数据时,块地址要与Cache块表中的所有地址标记进行比较已确定是否命中。在数据块调入时存在着一个比较复杂的替换问题,即决定将数据块调入Cache中什么位置,将Cache中哪一块数据调出主存。为了达到较高的速度,全部比较和替换都要用硬件实现。
3-组相联映像
组相联映像方式是直接映像和全相联映像的一种折中方案。这种方法将存储空间分为若干组,各组之间是直接映像,而组内各块之间则是全相联映像。
它是上述两种映像方式的一般形式,如果组的大小为1,即Cache空间分为2N组,就变为直接映像;如果组的大小为Cache整个的尺寸,就变为全相联映像。组相联方式在判断块命中及替换算法上都要比全相联方式简单,块冲突的概率比直接映像低,其命中率也介于直接映像和全相联映像方式之间。
1.3 Cache写入方式原理简介
提高高速缓存命中率的最好方法是尽量使Cache存放CPU最近一直在使用的指令与数据,当Cache装满后,可将相对长期不用的数据删除,提高Cache的使用效率。
为保持Cache中数据与主存储器中数据的一致性,避免CPU在读写过程中将Cache中的新数据遗失,造成错误地读数据,确保Cache中更新过程的数据不会因覆盖而消失,必须将Cache中的数据更新及时准确地反映到主存储器中,这是一个Cache写入过程,Cache写入的方式通常采用直写式、缓冲直写式与回写式三种,下面比较介绍这三种Cache写入方式。
1- 直写式(Write Through)系统
CPU对Cache写入时,将数据同时写入到主存储器中,这样可保证Cache中的内容与主存储器的内容完全一致。这种方式比较直观,而且简单、可靠,但由于每次对Cache更新时都要对主存储器进行写操作,而这必须通过系统总线来完成,因此总线工作频繁,系统运行速度就会受到影响。
2-缓冲直写式(Post Wirte)系统
为解决直写式系统对总线速度的影响问题,在主存储器的数据写入时增加缓冲器区。当要写入主存储器的数据被缓冲器锁存后,CPU便可执行下一个周期的操作,不必等待数据写入主存储器。这相对于给主存储器增加了一个单向单次高速缓存。
比如,在写入周期之后可以紧接着一个数据已存在于Cache中的读取周期,这样就可避免直写式系统造成的操作延时,但这个缓冲器只能存储一次写入的数据,当连续两次写操作发生时,CPU仍需等待。
3-回写式(Write Back)系统
前面两种写入方式系统,都是在写Cache的同时对主存储器进行写操作。实际上这不仅是对总线带宽的占用,浪费了宝贵的执行时间,而且在有些情况下是不必要的,可以通过增加额外的标准来判断是否有必要更新数据。回写式系统就是通过在Cache中的每一数据块的标志字段中加入一更新位,解决主存储器不必要的写操作。
比如,若Cache中的数据曾被CPU更新过但还未更新主存储器,则该更新位被置1。每次CPU将一块新内容写入Cache时,首先检查Cache中该数据块的更新位,若更新位为0,则将数据直接写入Cache;反之,若更新位为1,则先将Cache中的该项内容写入到主存储器中相应的位置,再将新数据写回Cache中。
与直写式系统相比,回写式系统可省下一些不必要的立即回写操作,而在许多情况下这是很频繁出现的。即使一个Cache被更新,若未被新的数据所取代,则没有必要立刻进行主存储器的写操作。也就是说,实际写入主存储器的次数,可能少于CPU实际所执行写入周期的次数,但回写式系统的结构较复杂,Cache也必须用额外的容量来存储标志。由于回写系统的高效率,现代的Cache大多采取这种方式进行操作。
1.4 关于Write-through和Write-back
1-对于磁盘操作来说
write-through的意思是写操作根本不使用缓存,数据总是直接写入磁盘,关闭写缓存,可释放缓存用于读操作(缓存被读写操作共用)。
write-back的意思是数据不直接被写入磁盘,而是先写入缓存,再由控制器将缓存内未写入磁盘的数据写入磁盘,从应用程序的角度看,比等待完成磁盘写入操作要快得多,因此可以提高写性能。
但是write-back(write cache)方式通常在磁盘负荷较轻时速度更快。负荷重时,每当数据被写入缓存后,就要马上再写入磁盘以释放缓存来保存将要写入的新数据,这时如果数据直接写入磁盘,控制器会以更快的速度运行。因此,负荷重时,将数据先写入缓存反而会降低吞吐量。
2-对于CPU内部的cache缓冲模式来说
Write-Through和Write-Back,前者是按顺序来一个写一个,而后者则是先将资料按一定数量保存在缓冲区中,然后将相同位置的数据一次性写出。举例说明:有一部电梯,如果按先入先出的原则,即write through模式,第一个人去3楼,第二个去2楼,第三个也去3楼,那么这电梯就得先到3楼,然后到2楼,再去3楼。
但如果在write back模式下,电梯先到2楼把第二个人送出去,然后再到3楼把第一个人和第三个人送出去,效率显然高多了。早期的cache只有write through模式,但现在的cache都使用write back模式了。
3-其他的解释
- Write-Through:在write的时候,同步更新cache和memory中的数据。Write-Back:在write的时候更新cache,但是memory中的数据不一定同步更新,只有当cache到一定程度才会把cache中的数据刷到memory中,或者通过cache指令刷新,不会同步自动刷新。
- cache line的意思是假设你那条指令只要从memory中读4个字节,但是一般来说你接下来的指令很有可能要读这4个字节后面的数据,所以一般硬件会多读一些数据进入cache,比如64字节,那么这64字节就是一个cache line。而如果你这个cache line里的数据长时间不被CPU访问,那么这个cache line可能会被选中换出,这时候就必须把cache里被改过的信息写回memory了。
1.5 Cache替换策略
Cache和存储器一样具有两种基本操作,即读操作和写操作。当CPU发出读操作命令时,根据它产生的主存地址分为两种情形:一种是需要的数据已在Cache中,那么只需要直接访问Cache,从对应单元中读取信息到数据总线即可;
另一种是需要的数据尚未装入Cache,CPU需要从主存中读取信息的同时,Cache替换部件把该地址所在的那块存储内容从主存复制到Cache中。若Cache中相应位置已被字块占满,就必须去掉旧的字块。常见的替换策略有以下两种:
1-先进先出策略(FIFO)
FIFO(First In First Out)策略总是把最先调入的Cache字块替换出去,它不需要随时记录各个字块的使用情况,较容易实现。缺点是经常使用的块,如一个包含循环程序的块也可能由于它是最早的块而被替换掉。
2-最近最少使用策略(LRU)
LRU(Least Recently Used)策略是把当前近期Cache中使用次数最少的信息块替换出去,这种替换算法需要随时记录Cache中字块的使用情况。LRU的平均命中率比FIFO高,在组相联映像方式中,当分组容量加大时,LRU的命中率也会提高。
1.6 使用Cache的必要性
所谓Cache即高速缓冲存储器,它位于CPU与主存即DRAM之间,是通常由SRAM构成的规模较小但存取速度很快的存储器。
目前计算机主要使用的内存为DRAM,它具有价格低、容量大等特点,但由于使用电容存储信息,存取速度难以提高,而CPU每执行一条指令都要访问一次或多次主存,DRAM的读写速度远低于CPU速度,因此为了实现速度上的匹配,只能在CPU指令周期中插入wait状态,高速CPU处于等待状态将大大降低系统的执行效率。
由于SRAM采用了与CPU相同的制作工艺,因此与DRAM相比,它的存取速度快,但体积大、功耗大、价格高,不可能也不必要将所有的内存都采用SRAM。
因此为了解决速度与成本的矛盾就产生了一种分级处理的方法,即在主存和CPU之间加装一个容量相对较小的SRAM作为高速缓冲存储器。
当采用Cache后,在Cache中保存着主存中部分内容的副本(称为存储器映像),CPU在读写数据时,首先访问Cache(由于Cache的速度与CPU相当,所以CPU可以在零等待状态下完成指令的执行),只有当Cache中无CPU所需的数据时(这称之“未命中”,否则称为“命中”),CPU才去访问主存。
而目前大容量Cache能使CPU访问Cache命中率高达90%~98%,从而大大提高了CPU访问数据的速度,提高了系统的性能。
1.7 使用Cache的可行性
对大量的典型程序的运行情况分析结果表明,在一个较短的时间内,由程序产生的地址往往集中在存储器逻辑地址空间的很小范围内。
在多数情况下,指令是顺序执行的,因此指令地址的分布就是连续的,再加上循环程序段和子程序段要重复执行多次,因此对这些地址的访问就自然具有时间上集中分布的趋向。
数据的这种集中倾向不如指令明显,但对数组的访问以及工作单元的选择都可以使存储器地址相对集中。这种对局部范围的存储器地址的频繁访问,而对此范围以外的地址则访问甚少的现象称为程序访问的局部性。
根据程序的局部性原理,在主存和CPU之间设置Cache,把正在执行的指令地址附近的一部分指令或数据从主存装入Cache中,供CPU在一段时间内使用,是完全可行的。
-
buffer和cache的区别2023-12-07 2362
-
华为云服务治理 | 服务治理的一般性原则2023-01-18 1184
-
Buffer和Cache的定义2022-05-13 3218
-
虚拟化技术的一般性描述资料下载2021-04-24 875
-
高速电路设计PCB布线的一般性原则分析2019-05-16 3982
-
任正非表示:公司停止对一般性岗位的社招2019-04-08 3833
-
基于时间分割代理加密的一般性构造方法2017-11-24 555
-
关于AD的工具一般性介绍2017-11-01 892
-
关于AD的一般性介绍2017-10-18 969
-
设备电磁兼容性故障的诊断和一般性处理意见(22页PPT)2015-09-01 4317
-
PCB设计的一般原则2012-06-05 1555
-
扫频仪一般性故障检修技巧2011-07-24 1266
-
设备电磁兼容性故障的诊断和一般性处理意见pdf2009-10-13 4871
-
一般性柔性线路板的性能与参数2006-06-30 1445
全部0条评论

快来发表一下你的评论吧 !
