

图解Spring Bean生成流程,非常详尽
电子说
描述
很多人把spring的相关内容当作背八股文,认为只在面试时能用上,实际开发根本用不到。实际上早期的我也是这么想的,但随着开发年限的增长,解决了越来越多的难题后,不得不承认,这些基础知识的学习有着无法替代的作用。
就拿我实际遇到的一个例子来说:
有一个大型项目因为安全漏洞的原因要进行升级,需要从springboot1.0升级至springboot2.0,但发现springboot2的默认动态代理方式为CGLIB,而项目上很多地方利用的jdk代理对接口做了增强,切换至CGLIB导致了大量问题。根据百度的内容,设置了proxy-target-class=“false”,然而不起作用,最后发现是某一个三方包内设置了proxy-target-class=“true”,而这个属性只要在工程里任何地方设置过一次true,都会导致代理管理器的同名属性为true,最终采用CGLIB代理,那么有什么简单方式可以解决这个问题
先卖个关子,还是让我们一起学学Bean的生成吧
1引言
作为javaboy的必修课,spring一路伴随着开发者;同样的,也一路伴随着开发者面试,重要性不言而喻,我们经常遇见的问题比如:
代理对象是何时生成的?
循环依赖是怎么解决的?
能说说对Springr容器三级缓存的理解吗?
以上问题,都离不开对bean生成流程的熟悉与理解。但是不得不谈,目前网上文章鱼龙混杂,一些偏颇错误的分析四处流传,我们后面会提到一些常见谬传。至于现在,现在先和我们一起,深入的看下springBean的生成逻辑吧
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
2创建Bean的极简流程
我们开门见山,直接以单例对象为例子,说一个Bean的极简流程以及其目的
获取Bean定义
扫描工程内所有被标记的Bean,获取其类型,名称,属性,构造方法等信息,存在一个Map里
生成实例
这一步也很简单,遍历上述Map,利用Bean定义里的无参构造方法创建对象,和new 对象同理
属性装填
刚创建的对象所有属性都是默认值,需要我们给它装填上需要的内容
初始化
如果这个Bean实现了InitializingBean接口,则会调用你写在afterPropertiesSet方法里的内容。
到此,一个Bean就创建完毕了,是不是很简单?是的,很简单,逻辑也很清晰。
当然,上面四步是核心功能,Spring为了增强对这些Bean的修改能力,在2-生成实例 3-属性装填 4-初始化的前后都预留了处理点,Spring自己或用户都可以通过编写==Bean后置处理器(BeanPostProcessor)==来实现自己的目的,这些处理器会在对应的处理点被执行,从而完成对Bean的修改,下面会详细讲一下
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
3后置处理器(PostProcessor)
Spring中的后置处理器分为两大类:
一类是针对Bean工厂的BeanFactoryPostProcessor
一类是针对Bean的BeanPostProcessor
以上两者都是接口,Spring已经给定了一些实现类,用户也可以自己写一些实现类来实现全局的Bean相关的操作;顾名思义,BeanFactoryPostProcessor针对Bean工厂(它还有个子接口BeanDefinitionRegistryPostProcessor),调整Bean工厂的属性、影响Bean定义,注意此时还没有Bean进行实例化。BeanPostProcessor则更直接的作用于Bean实例生成过程中的修改。
BeanFactoryPostProcessor
很多人不知道在实际项目中这个处理器有什么用,好像我们不需要对Bean工厂或者Bean做什么改动吧?大部分项目确实不需要,但很多时候,我们需要添加一些自定义的Bean,或者出于项目需要,改动一些Spring原生Bean属性时就用的上了。
比如我们常用的myBatis组件,我们会在mapper层的接口上写@Mapper注解,最后就会在Spring中生成对应的Bean对象,然而这里有一个问题:
@Mapper注解不是Spring规定的Bean注解,怎么被扫描进容器的?
自然是依托于BeanFactory后置处理器。mybatis中写有工厂后置处理器的实现
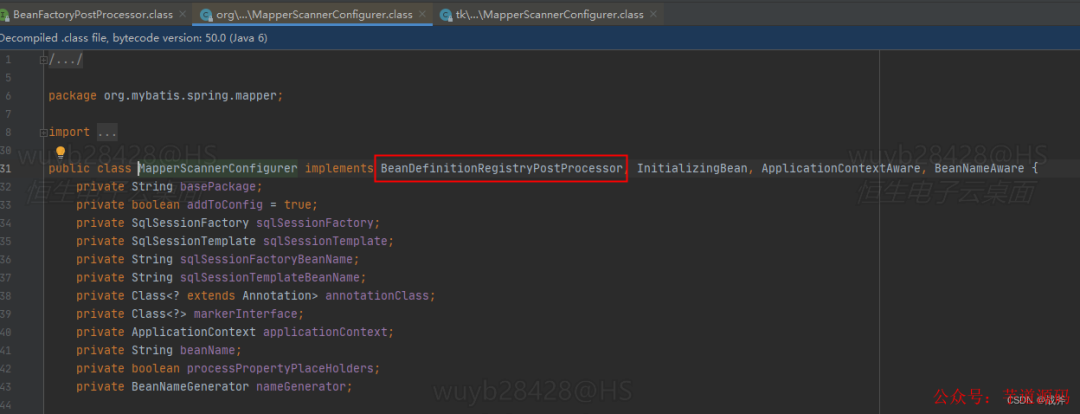
看名字也知道,这个处理器起了扫描的作用,找到了被我们标记的接口,并“捏造”一个Bean定义,并把Bean的类型设置为MapperFactoryBean.class,即工厂类,然后把它添加到Bean定义注册器中。
而在我们需要实例化这个Bean的时候,mybatis又会从这个工厂对象中使用getObject()为我们取出一个Bean实例,这个Bean实例是使用我们写的Mapper接口产生的代理,而后再把这个代理放入Spring容器
BeanPostProcessor
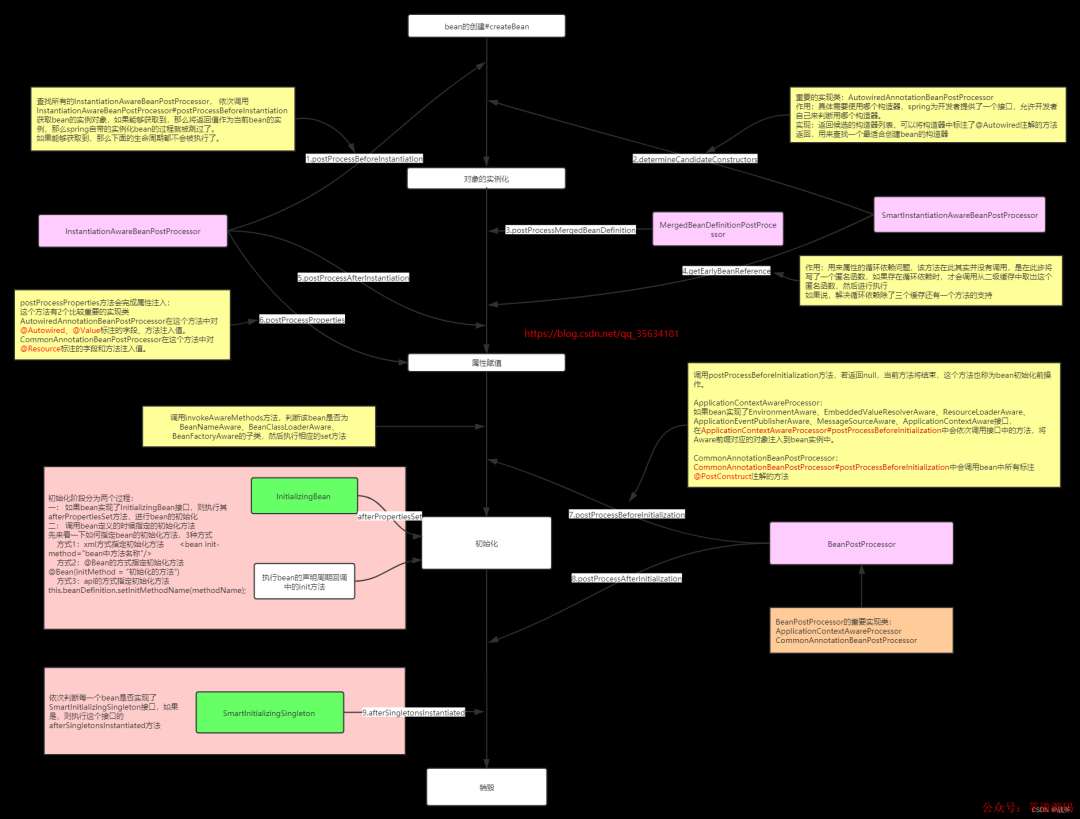
而Bean后置处理器则更加常见,种类也更丰富,他们的详细作用和工作时机都可以在下图中看到
契机问题的解决
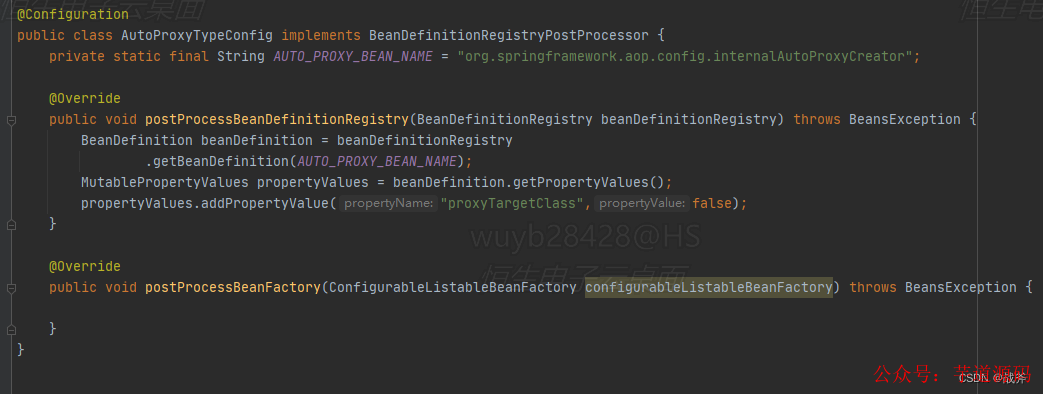
让我们回到契机里提到的那个问题,这个问题简化的讲,其实就是有这么一个Spring内部的Bean名字为org.springframework.aop.config.internalAutoProxyCreator,它有一个属性proxy-target-class,这个属性决定了Spring动态代理的生成用的jdk动态代理还是CGlib,然而在很多地方(三方包)已经给他赋值。
我们必须在它被其他三方包赋值后 ,把它的属性值改为false。这个问题最终怎么做到的呢?就是利用了后置处理器,此处使用工厂后置处理器找到该Bean定义,修改其Bean属性
4引用与缓存
从上面看,似乎创建一个Bean只需要四步(忽略后置处理器的步骤),十分简单。确实,如果我们的项目只需生成一个Bean,那只要按序完成这四步就可以了。
但实际上,Spring本身和我们的项目要生成的Bean数量远不止一个,复杂的项目一般会达到上千个Bean,Bean之间还有复杂的引用关系。我们不仅要存储这些Bean,还必须考虑到这些引用情形,从而引入缓存的机制。
引用已有的Bean
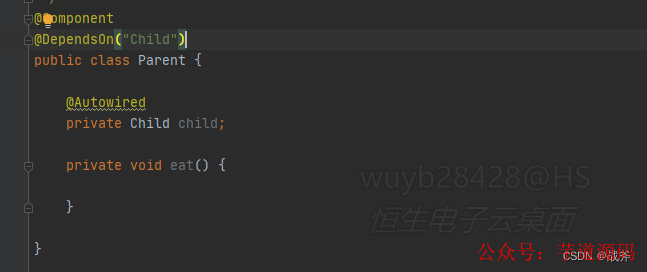
如图,上述是一种最简单的引用,Parent 里面引用了 Child ,。理想的情况下,我们先创建了Child并保存起来,那么在创建Parent的时候,直接引用现成的Child就好(此处用@DependsOn保证这种顺序)。那么这时我们可以说,容器只需要使用一级缓存,就像养鸡场里饲养着许多鸡,这个缓存里存的就是各个现成的Bean,直接取用即可。
引用未创建的Bean
上述的Parent 里面引用了 Child案例,只是一种理想情况,实际上,大部分的Bean之间加载顺序并不会特意指定,创建的先后顺序自然没了保障(spring会执行默认的加载顺序,如字母排序)。
比如这个案例,如果先创建的是Parent,那么当我们做到属性装填这一步的时候,就会发现Parent的属性里,引用了一个未知的Bean —— Child。
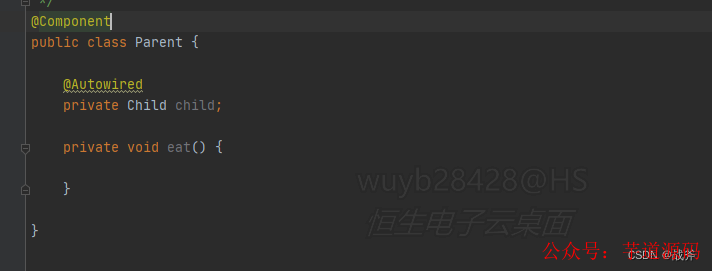
这个时候Spring就会去搜寻并创建Child,此时Parent的创建就停滞了。那么这个创建未半而中道崩殂的Parent也需要有一个地方存起来啊。你或许会说,还是存在上面的一级缓存里面不行吗?
当然可以!但本着人以类聚物以群分的观念,对于这些创建了一半就中断的Bean,我们还是专门引入了三级缓存供其栖息。我们知道,此时Parent已经实例化了,但属性装填没完成,像个未孵化的蛋,而三级缓存就是个保温箱,是存放这些“蛋”的地方。实际上三级缓存里存的全是Bean工厂,可以通过Bean工厂的getEarlyBeanReference获取到这个未完成的Bean(蛋)。
循环引用(循环依赖)
如果不仅Parent里面引用了Child,Child里面也引用了Parent,那么显然,这就构成了循环引用。
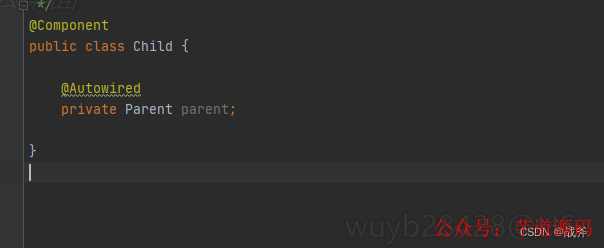
我们假定Spring先加载了Parent,后发现需要注入Child,又去加载Child,过程中又发现需要注入Parent,那么又去加载Parent…… 那Spring会这么无限的加载下去吗?
答案我们都知道,自然是不会的。实际上,每开始加载一个Bean,Spring都会把Bean名称记录在一个叫SingletonCurrentlyInCreation的Set集合里。
顾名思义,这个集合里都是正在创建中的Bean,这个集合在其他的文档中很少提及,但显然他的作用十分巨大。因为第二次加载Parent时,Spring就发现Parent已经在这个集合中了,才意识到进入循环引用了。
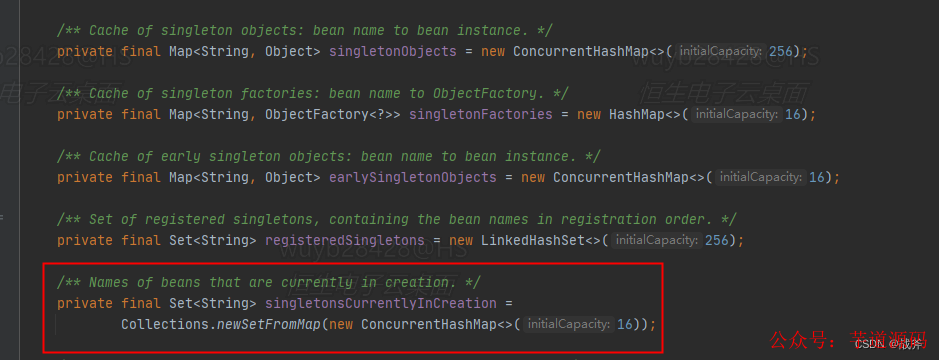
当发现进入循环引用后,自然Spring不会再傻乎乎的走再走一遍Parent的加载逻辑,而是从三级缓存中取出未完成的Bean,做一些处理后,然后将其放入二级缓存。
这一过程相当于从保温箱取出来未孵化的鸡蛋,孵化出小鸡后,放到专门的小鸡培养室中。而此时,只需要返回这只小鸡(Parent)就可以了,你或许会说,我要的是成品鸡,你给我小鸡有什么用,功能什么的能有保障吗?别急,我下面就为你解释这样的可行性。
循环引用中的代理
我们都知道Parent是创建了一半被放入缓存中的,此时它已经完成的步骤是生成实例正在卡着的步骤是属性装填和初始化,被从缓存中取出后,这两个步骤仍然是未完成的,但我们无需担心,因为此刻我们仅需完成引用,即我要引用Parent(成鸡),你现在给我返回半成品(小鸡)也没关系,因为我现在也不是要立刻就用你,只要你保证小鸡 成鸡在内存中的地址一样即可,即小鸡和成鸡是同一个对象。
你或许会问,小鸡长着长着,还能变了人不成?怎么可能小鸡和成鸡就不是同一个对象了呢?这就不得不谈代理模式了
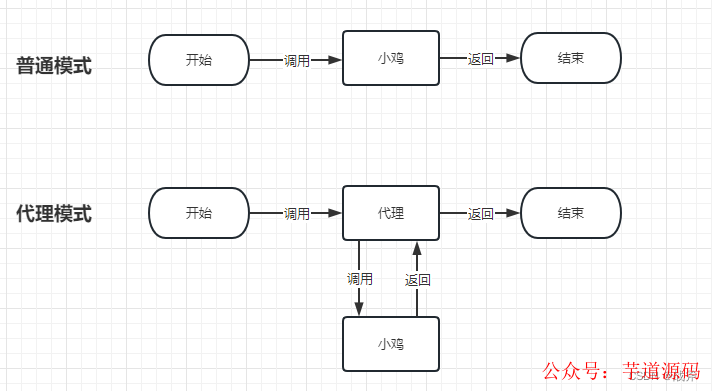
我们这里不去细谈代理流程,你只需要知道代理模式会产生一个新的对象,相当于一个霸道中介,原本你可以直接联系小鸡,现在小鸡的联系被中介切断了,你需要找小鸡就只能联系中介。所以,一旦成鸡后续需要代理,我们需要联系的就是成鸡的代理了,此时你给我小鸡的联系方式不顶用。
为避免这种情况,我们只能给小鸡生成中介。是的,原来中介是只给成鸡用的,但现在不得不提前到小鸡阶段了,生成中介后,返回给我们小鸡的-中介的-联系方式(即半成品Bean的-代理的-引用),事实上如果你看源码,对成品和半成品Bean生成代理用的是同一个方法wrapIfNecessary,因此生成代理的效果是一样的。当然你也许仍然有顾虑,对成品和半成品生成代理真的没差别吗?
的确,这里就不得不提Spring的代理的特殊点了,代理的基础就是大名鼎鼎的AOP 或者说 切面增强,然而Spring的增强仅针对方法。而半成品和成品,最大的差异是属性值,方法却是一样的,因此增强的效果肯定是一样的。如果哪天Spring的代理生成时会用到当前属性值,那不同阶段的代理功能才会有差异。
5三级缓存的解读
关于三级缓存,市面上有太多的解读文章,也是面试时经常问到的点,我们不妨解读一下三级缓存。
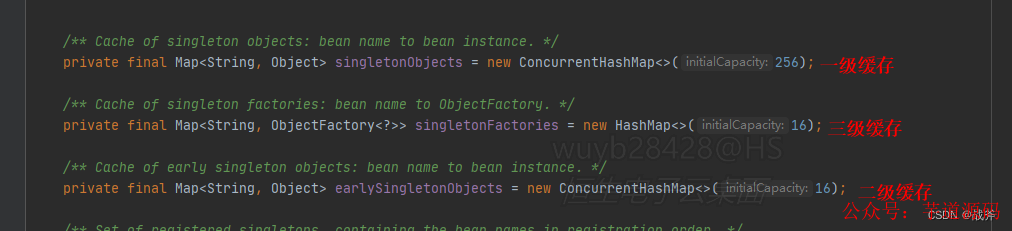
我们平常说的三级缓存,大多数人会想到CPU的三级缓存,硬件上之所以缓存分级,是对于成本与性能的考量,一级缓存最快,所以CPU优先从一级缓存取东西,但同样一级缓存最贵,存不了太多数据,所以需要二级缓存。
而这里,三级缓存并没有性能上的区别,所以划分三级缓存并非必须。实际上一个Bean,在同一时间只会出现在某一级缓存中,因此我们可以直接产出一个暴论:Spring可以不用所谓三级缓存,甚至说只需要一个集合就能存下全部
但为什么这里要这么做,因为这是逻辑分层而非必要分层,三级缓存存着不同状态的Bean罢了:一级缓存存成品鸡,二级缓存存小鸡,三级缓存存鸡蛋 一级比一级原始,你要非把成品鸡、小鸡、鸡蛋搁一个房子里也不是不行,所以这种分层是基于逻辑清晰而非逻辑必需。
这里还有个误区,很多人说是因为代理的存在,导致需要三级缓存,如果没有代理,两级就够了。实际上三级缓存并不是因为代理导致的,不管有没有代理,都是三级缓存。
就像我说的一级缓存存成品鸡,二级缓存存小鸡,三级缓存存鸡蛋 ,这里面并不区分代理,成品鸡或者成品鸡的代理都在一级缓存;小鸡或者小鸡的代理都在二级缓存。
实际上我们看代码,只要发生了循环引用,都会导致Bean从三级缓存取出,并放入二级缓存。这个过程中执行wrapIfNecessary,不管生不生成代理都是一样的,只不过如果需要代理,放入二级缓存的是小鸡的代理;如果不需要代理,放入二级缓存的就是小鸡本鸡,因此我们可以说 不管有没有代理,三级缓存的模式都没有变化。
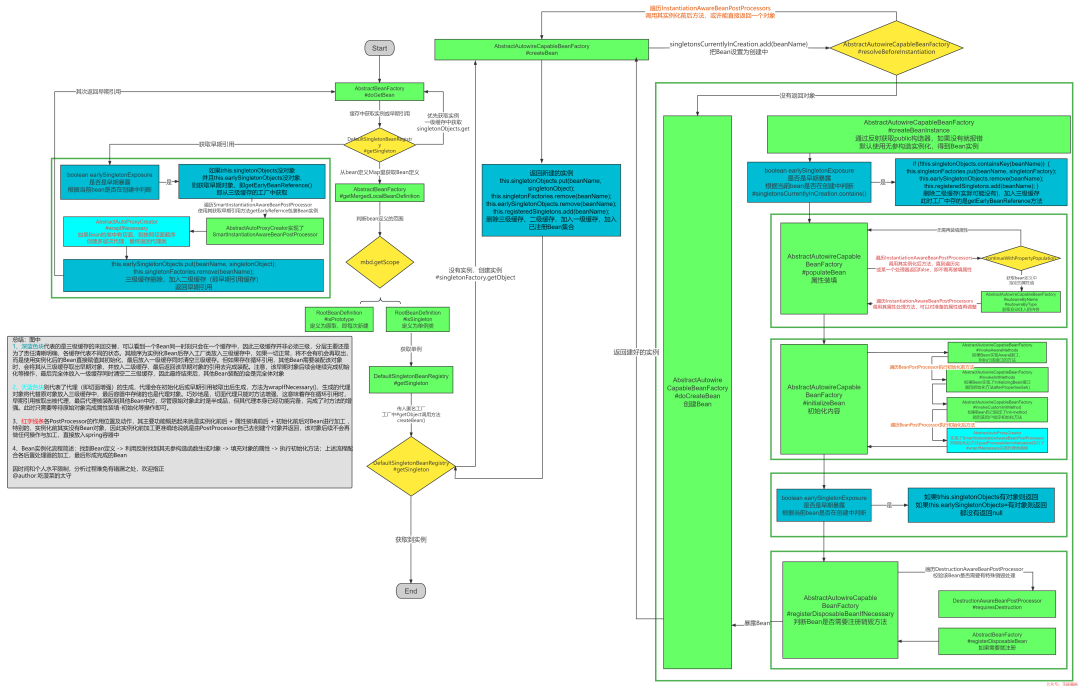
6创建Bean的极详细流程
多说无益,我根据Spring4的源码整理了一份详细的生成流程,这图说是全网最细也不为过,欢迎大家补充和指正
-
Spring容器原始Bean是如何创建的?Spring源码中方法的执行顺序2023-08-04 1369
-
27个非常经典的设备工作流程图解2023-06-02 3410
-
Spring依赖注入Bean类型的8种情况2023-05-11 1275
-
Spring Dependency Inject与Bean Scops注解2023-04-07 1294
-
Spring中Bean的生命周期是怎样的?2022-10-11 2291
-
将bean放入Spring容器中有哪些方式2022-09-19 1338
-
「Spring认证」Spring IoC 容器2022-06-28 1437
-
Spring Boot嵌入式Web容器原理是什么2021-12-16 1473
-
「Spring认证」Spring Hello World 项目示例2021-08-17 2332
-
解析加载及实例化Bean的顺序(零配置)2021-08-04 2123
-
Spring工作原理2019-07-10 2739
-
三大框架之Spring2019-05-27 1360
-
Spring应用 1 springXML配置说明2018-01-13 590
-
java spring教程2008-09-11 4851
全部0条评论

快来发表一下你的评论吧 !
