

基于主观知识的任务型对话建模
描述
1 引言
对话系统技术挑战赛 DSTC(The Dialog System Technology Challenge)是对话技术领域的顶级赛事,到 2023 年已举办至第 11 届。
DSTC11 共设有 5 个赛道,其中刚刚结束的 track5 的主题是基于主观知识的任务型对话建模。本赛道包括三个子任务:
Turn Detection:判断当前的对话是否需要外部知识
Knowledge Selection:在非结构化主观知识文档中选出相关的知识候选
Response Generation:根据第二步的知识候选生成回复
我们参加了 DSTC11-track5 并在所有 14 个参赛队伍中排名第三(客观指标),其中 Turn Detection 子任务排名第一。本文将介绍 track 5 相关内容以及我们在竞赛中尝试的方法。
2 赛题介绍
我们在本章中详细介绍具有主观知识的任务型对话 (SK-TOD) 建模任务的数据集、子任务、竞赛评价指标以及进行的前期相关调研。
2.1 数据集介绍
下图[1]为对话数据集中的三个对话实例和与它们相关的知识数据中的主观知识条目示例:

对话实例与主观知识条目示例
对话数据集有两部分来源:
主办方标注的 19696 条需要主观知识的对话,这些对话既有包含单个实体,又有包含多个实体的(如图 1 的 Dialogue 2)。
从 MultiWOZ[2] 任务型对话数据集中抽取的 18383 条不需要主观知识的对话。
知识包括两种:review 类型的主观知识(由多个句子组成) 和 FAQs 类型的知识(问答对)。这些知识被被划分为两个域:hotel 和 restaurant,分别包含 33 个实体和 110 个实体。
例如,hotel 域中的 Hobsons House 实体,包含的 review 知识有:
"I was very please with my recent visit to Hobsons House." "I was on a business trip and needed a quiet place to stay and this place fit the bill!" "While I was not pleased with the slow wi-fi and small room, I was content with their awesome breakfast options, friendly and engaging staff members and the best part!" "Nice and quiet, just the way I like it!" "Would definitely recommend this place to friends and plan on staying here again on my next venture!" ...
包含的 FAQs 知识有:
question: "What do you offer for breakfast?", answer: "An Full English/Irish breakfast is available at the HOBSONS HOUSE" question: "What is the check-out time at your location?", answer: "Check-out time at the Hobsons House is between 7:30 am and 10 am." ...
2.2 问题定义
我们给出 DSTC11-track5 赛题的一般化定义。对于每一个对话实例 ,除最后一轮外,之前每一轮都有 agent 的回复 与用户查询 对应。整个对话实例 可能与一个或多个实体相关,我们将该实体集合定义为。
定义主观知识数据,其中,表示每一个实体包含的若干知识条目。
我们的做法将整个任务进一步分解为如下图所示的四个阶段:
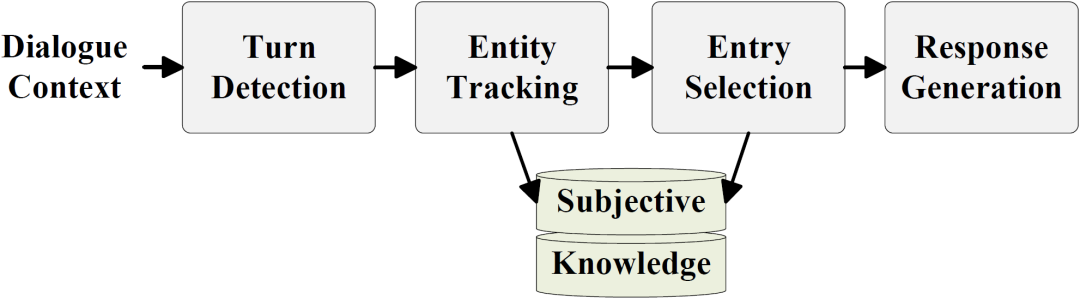
图2. 基于主观知识的任务型对话建模流程
Turn Detection:判断用户最后一轮查询 是否需要主观知识
Entity Tracking:如需要主观知识,则确定与之相关的实体集合 (本部分不在比赛评测中)
Entry Selection:从实体 包含的知识候选集合 中选出相关的主观知识条目
Response Generation:由对话上文 和相关的主观知识条目生成回复
本赛道的难点有三个:
当需要检索主观知识时,每个对话对应的知识条目是不确定数目的若干条;
验证集和测试集的分布与训练集有较大差异,有大量的 unseen 信息;
不同的主观知识有不同的情感倾向,回复中需要考虑多条主观知识中的不同情感倾向。
2.3 评价指标
三个子任务的评价指标分别为:
Turn Detection:Precision、Recall、F1
Knowledge Selection:Precision、Recall、F1、Exact Match
Response Generation:BLEU、METEOR、ROUGE-1、ROUGE-2、Rouge-L
客观评测的最终分数为每个评价指标排名的倒数和,即
其中 为第 个评测指标的结果在所有参赛结果中的排名。
2.4 相关调研
我们首先调研了 DSTC 的往届比赛,其中 DSTC9-track1 和 DSTC10-track2 均与本届赛题类似。
DSTC9-track1 的问题定义,数据集格式与本赛题完全相同,唯一的不同点在于每轮对话只需找出一条最相关的知识,问题要简单许多:
He[3]等人提出了图式引导的知识决策、否定强化的知识选择和基于知识及机器理解的回复生成以适应三个子任务。
Tang[4]等人提出了基于 API 关键字与对话上下文相关性学习的方法。
DSTC10-track2 将外部知识数据从书面语更改为口语,使得构建高泛化能力的模型更为重要。而且,由于该竞赛并未给出训练集,参赛队伍提出了很多有效的数据增广方法:
Yan[5]等人提出了一种基于域分类任务和实体选择任务来学习多级语义信息的方法,以及通过注入基于语音相似性的人工生成的扰动方法来扩充书面数据的思路。
Xu[6]等人首次尝试将掩码跨度语言建模应用于对话状态生成,该方法有效增强了模型的泛化能力。
Whang[7]等人使用了 Levenstein 距离进行后处理来避免模型预测失真问题。
Yu[8]等人在 baseline 中增加了卷积层,这一改动获得了更好的跨度预测性能,并使用了一种称为 multiple 的跟踪多值的自适应方法。
Cho[9]等人采用了实体检测以及域跟踪的方法缩小了候选知识的范围。
Tan[10]等人提出了基于指针网络的“知识复制”方法,有效减轻了 decoder 的压力,同时提出分段响应的方法:用不同的模型生成知识选取部分和问候应答部分。
除此外,我们还调研了一些使用 MultiWOZ 数据集做端到端对话生成的模型:
He[11]等人提出的 GALAXY 模型使用门控机制来给未标记数据打伪标签。
Lee[12]设计了一个巧妙的模型,用对话状态跟踪模块在考虑对话历史的情况下跟踪信念状态(用户目标),然后再通过信念状态作为查询获得数据库状态,最后生成回复。
3 竞赛方案
3.1 数据增强
我们基于原始数据集构造了两种增强数据集:
unseen 数据集:利用知识数据扩充对话。在对话数据集中,每一个对话实例都围绕一个实体展开,知识数据中会有很多与这个实体相关的问答型知识(FAQ)。我们将这些问答对随机拼接在原始的对话实例中,就得到了只涉及一个实体的新的对话实例。为了模拟真实场景中话题转移,我们在另一个实体下生成对话的另一部分,并以 80% 的概率将它们拼接在一起[13]。
noise 数据集:采用谷歌翻译服务将英语翻译成其它四种语言(西班牙语/德语/日语/法语),然后再将其回译为英语。当回译句子与原句子相似度过高(这一现象在英法互译中较为普遍)时,我们使用 Wordnet 进行同义词替换以增加其多样性。最后,我们将对话数据集及知识数据扩充为原来的 5 倍,这些数据用于对模型预训练。进一步将 5 种对话数据集和知识数据两两组合,得到原来 25 倍大小的数据集。因为回译和同义词替换引入了词级和语义级的干扰,所以我们定义此数据为noise数据。
3.2 Turn Detection 阶段
本阶段的目标是判断当前对话用户的最后一轮查询是否需要主观知识,是一个二分类问题。
我们使用自编码预训练模型 DeBERTa-v3-base[14],将当前对话上文和最一轮查询 作为输入,取最后一个隐藏层的第一个 token 即 [CLS] 的向量作为对话表示,将其输入一个线性层中就求得分类概率:
为了在后面进行模型融合,提高整体的泛化能力,我们训练了三个模型,分别适用于三种场景:
Seen expert。使用 DSTC11-track5 提供的训练集微调 DeBERTA-v3-base 模型,得到在验证集上表现最好的模型。这个模型在见过的对话实例上有极好的表现。
Unseen expert。为增强模型在未见过的对话实例上的检测能力,我们使用 3.1 介绍的 unseen 数据集对 RoBERTa[15] 模型进行微调。
De-noise expert。为得到一个泛化能力较强的模型,我们考虑使用 3.1 介绍的 noise 数据集进行训练。首先,用回译的 5 倍数据集基于 word-masking[16]预训练方法对 DeBERTa 模型进行预训练,然后,使用两两组合的 25 倍含有噪音的数据集进行微调。
在后面,我们会使用基于差异感知的模型融合方法来融合这三种模型,让它们相得益彰。
3.3 Entity Track 阶段
本阶段的目标是确定与当前对话用户的最后一轮查询相关的实体。该阶段可以缩小后续知识选择的范围。
我们使用启发式方法为每个实体名称建立一个词典,然后基于 n-gram 匹配最后一轮对话中出现的实体。这种方法已经能达到较为不错的结果,验证集性能为 F1=0.9676,accuracy=0.9398。
3.4 Entry Selection 阶段
本阶段目标是选出与用户查询相关的知识条目。输入是对话上文,以及知识候选 ,输出为知识候选的子集 。我们使用同一个编码器获得两者的表示 ,。然后将 ,, 拼接在一起计算相关性:
在训练时,我们将与 ground-truth 同一实体的知识和其它实体的知识按 1 : 1 比例构造负例。在验证时,我们使用 Entity Track 阶段确定的实体中的知识作为知识候选。
与 Turn Detection 类似,我们同样训练了 Seen expert,Unseen expert 和 De-noise expert 这三种模型,之后也使用基于差异感知的模型融合方法来融合这三种模型。
3.5 Response Generation 阶段
本阶段目标是基于对话上下文 和相关知识片段 来创建响应用户请求的回复 。我们将 和 连接起来作为输入,并使用经预训练的生成模型来生成回复。
我们既考虑了 decoder-only 架构的模型(如 GPT-2[17])也考虑了 encoder-decoder 架构的模型(如 BART[18]和 T5[19])。
此外,为了降低 Entity Track 和 Entry Selection 阶段对本阶段的影响,我们在训练时使用了一些方法调整模型输入:
拼接对话时额外添加实体名字段强化实体信息;
随机丢弃 15% 的知识以让模型在 Entry Selection 阶段漏选知识时仍能取得良好的生成效果。
此外,我们还考虑了其他生成方式:
使用 KAT-TSLF 结构[20],考察将对话上下文和全部候选知识条目作为输入以及将对话上下文和 KS 阶段选取的知识条目作为输入,但是效果均不如 BART 模型;
使用在本任务上经过 alpaca 微调的 LLAMA-13B[21],结合专门设计的 instruction,输入对话上下文和所选的知识条目来生成回复。然而,正如近期研究显示,LLM 存在幻觉问题[22],不能很好地执行特定领域或知识密集型任务。因此该模型在本任务上其表现也不如 BART 模型。
3.6 基于差异感知的模型融合方法
为了融合 Seen expert,Unseen expert 和 De-noise expert 这三种模型,我们提出了一种基于差异感知的模型融合方法。
以 Entry Selection 阶段训练出来的三种模型为例。对于验证集的第 个对话实例,设 为 ground-truth 标签,它包含 条知识。我们用不同模型得到 条知识条目候选,并将它们按相关度降序排列。对于每个知识条目候选,我们为其设置权重为它的相关度排序加一的倒数。例如 Seen-expert 模型得到的知识候选的第 条 权重为 。同理, 和 分别为 Unseen expert 和 De-noise expert 得到的知识候选和权重。
由此得到知识候选集合,对于第 条知识,将它的融合权重定义为,其中,如果存在 使 ,则 ,否则, 是超参数,满足 。
此外,我们还对权重设置了一个阈值,得到的超过阈值的知识条目集合 即为最终输出。使用验证集的 Recall/Precision/F1/EM 等指标学习超参数 ,整体算法如下图所示:

算法流程图
该方法对于不同任务和不同数据集均可适用:
比如在 Entry Selection 阶段,为同时保证知识选择的准确率和召回率,我们使用权重阈值来决定该知识是否相关,而不是直接选择 Top-N 权重的知识。
对于不同测试集,我们可以根据其中 unseen 对话条数的比例相应调整验证集中 unseen 的比例来学习 。通过 的调整,测试集中 unseen 对话条数比例越高,我们的 Unseen expert 在最后权重占比也就越大。
4 结果分析
本章分析我们的方法在验证集及最终测试集上的表现。
4.1 Turn Detection 子任务
Turn Detection 子任务实验结果如表 1 所示:
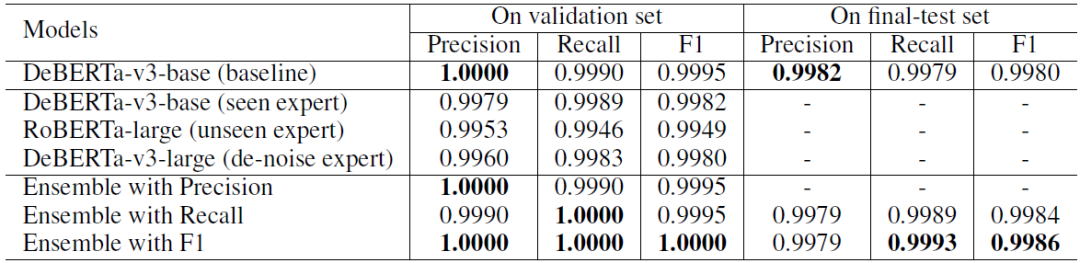
表1 Turn Detection 子任务实验结果
不难看出 baseline 在验证集上已经有了很高的性能。考虑到最终测试集中有 unseen 对话 ,于是我们使用基于差异感知的模型融合方法,力求在测试集的 unseen 对话上获得更好的性能。
我们分别使用 Precision、Recall 和 F1 作为指标来学习模型融合参数,因为更高的 Recall 对 unseen 对话更有效,所以我们选择 Recall 和 F1 训练的结果模型融合结果作为最终提交。
在最终测试集上,我们的方法在所有提交结果中 F1 指标排名第一,Recall 指标排名第二,三项总和排名第一。
4.2 Knowledge Selection 子任务
Knowledge Selection 子任务实验结果如表 2 所示:
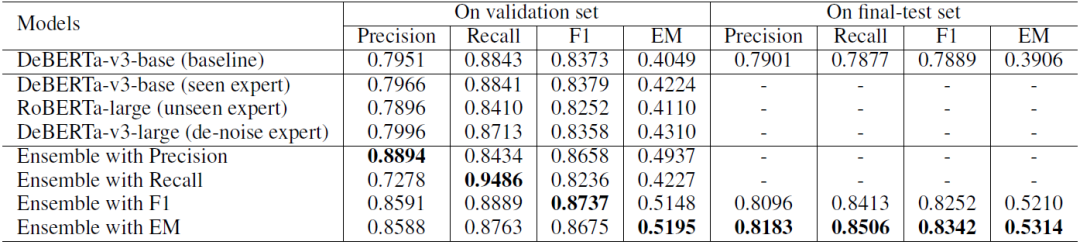
表2 knowledge selection 子任务实验结果
可以看到:
我们的单个模型表现都只略好于 baseline,然而使用我们的模型融合方法后,性能大幅提高,这说明我们的模型融合方法能结合不同 expert 的优势,使得模型综合性能大大提升;
分别使用不同的指标学习模型融合参数,就能得到相应指标下表现最好的模型。
我们依据 4 个指标的验证集结果总和选择最后两个结果(F1 和 EM)作为最终提交。在测试集上,我们的方法具有一致的性能,并且在很大程度上优于 baseline。尤其在 EM 指标上,我们的方法比 baseline 高出 14%。
为下一节表述方便,我们将这两个结果表示为 KS-F1 和 KS-EM。
4.3 Response Generation 子任务
Response Generation 子任务实验结果如表 3 所示:

表3 knowledge selection 子任务实验结果
我们在生成回复过程中并没有使用模型融合方法。上述结果可以反映出知识选择子任务对生成任务的影响。
使用 KS-F1 的 BART-base 生成结果在所有指标上都优于 baseline。这一结果表明,KS-F1 提供了更高质量的知识条目,并再次证明了我们模型融合方法的有效性。
BART-large 和 T5 作为更大的模型,在大多数指标上都优于 BART-base。此外,BART-large (KS-F1) 的 BLEU 指标表现极好,在所有提交中排名第二。BART-large (KS-EM) 在 ROUGE 指标上表现更好,T5-3B (KS-EM) 在 METEOR 指标上更好。然而,T5 在测试集上的 BLEU 指标表现不佳,与 BART-large 相比没有明显的优势。
5 总结
我们在 DSTC11-track5 竞赛中提出了一种基于差异感知的模型融合方法。该方法很好的解决了竞赛的两大难点:
每个对话实例都与数量不定的若干条知识相关,如何让模型学习到这种分类能力。
训练集、验证集和测试集分布差异较大,如何让模型在 seen 对话和 unseen 对话上都能有不错的表现。
最后我们获得了客观指标排名第三的成绩,这一成绩证明了我们方法的有效性。
未来可以继续尝试的工作包括:
知识选择子任务:
可以将基于差异感知的模型融合方法同样运用在 Entity Track 阶段。
review 型的主观知识和 FAQ 型的主观知识具有不同的语义特性,比如 FAQ 的问句可能与用户查询有着较高的相似度,考虑如何分别对这两类知识进行选择。
回复生成子任务:
可以考虑分别用对话历史 encoder 和外部知识 encoder 对输入进行编码再对其加以融合,这可能有助于模型对于对话生成和知识整合两部分的单独学习。
可以考虑使用大模型对知识加以初步的理解,再用我们的回复生成模型根据被理解的信息进行回复,这可能有助于增强模型的泛化能力。
可以考虑用对话状态追踪技术分析输入的对话历史,这可能有助于增强模型抗干扰能力。
针对前文提到的第三个难点,不同的主观知识有不同的情感倾向。可以考虑使用特定的情感理解模型辅助生成的训练。
模型融合:
考虑进一步优化我们的基于差异感知的模型融合方法,让模型自动学习阈值。
-
基于CVR建模的多任务联合学习训练方法——ESMM2020-08-27 6701
-
【安富莱原创】【STemWin教程】第39章 对话框基础知识2015-04-29 5488
-
基于任务链的实时多任务软件可靠性建模2009-03-03 454
-
知识型员工任务评价信息系统的指标模型2009-04-11 477
-
四大维度讲述了一个较为完整的智能任务型对话全景2019-02-04 7856
-
强化学习应用中对话系统的用户模拟器2019-08-06 2381
-
强化学习在智能对话上的应用介绍2020-12-10 1528
-
将对话中的情感分类任务建模为序列标注 并对情感一致性进行建模2021-01-18 3842
-
口语语言理解在任务型对话系统中的探讨2021-03-31 2901
-
视觉问答与对话任务研究综述2021-04-08 985
-
NLP中基于联合知识的任务导向型对话系统HyKnow2021-09-08 4802
-
基于知识的对话生成任务2022-09-05 2486
-
NVIDIA NeMo 如何支持对话式 AI 任务的训练与推理?2023-05-11 2068
-
知识分享 | 轻松实现优质建模2024-09-12 1080
-
思必驰任务型对话算法通过国家备案2025-11-20 677
全部0条评论

快来发表一下你的评论吧 !
