

AXI的控制和数据通道分离
描述
AXI的控制和数据通道分离,可以带来很多好处。地址和控制信息相对数据的相位独立,可以先发地址,然后再是数据,这样自然而然的支持显著操作,也就是outstanding 操作。
Master访问slave的时候,可以不等需要的操作完成,就发出下一个操作。这样,可以让slave在控制流的处理上流水起来,达到提速的作 用。
同时对于master,也许需要对不同的地址和slave就行访问,所以可以对不同的slave 连续操作。而这样的操作,由于slave返回数据的先后可能不按照master 发出控制的先后进行,导致出现了乱序操作(out of order )。
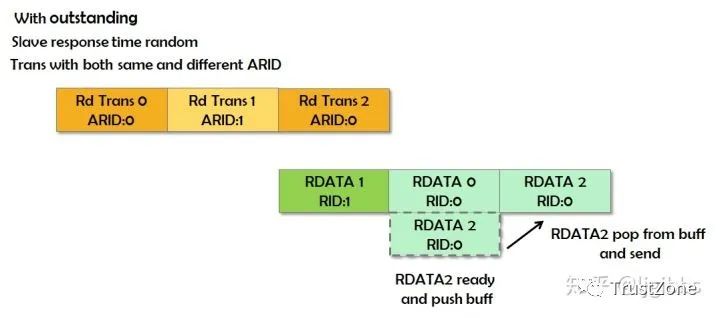
乱序传输需要依赖ARID来完成,乱序传输是针对transaction而言的,可以认为ARID是transaction的ID。
若支持乱序传输,当存在多个transaction时,从机可以不按照transaction的发起顺序进行返回数据,主机通过从机返回的BID(写)或RID(读)来判断返回的数据属于哪个transaction。
另外,拥有相同AWID与ARID的transaction,其返回数据需要按照transaction发起的顺序进行返回数据。乱序传输的数据传输过程如下图所示:
interleaving 交织
写交织使用WID来实现,interleaving用来实现不同transaction中的beat的交替传输,但同一transaction的beat是需要按照顺序进行传输的。
AXI4中已经取消了WID信号的使用,不再支持写交织。interleaving的输出传输过程如下:
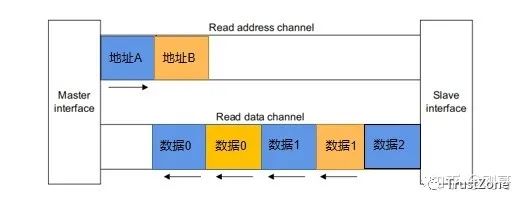
其中数据0与数据1属于同一transaction的不同beat,地址A与地址B表示两个transaction。
关于AXI4不支持写交织是一个非常自然地过程。为了提高效率,AXI总线的写数据通道并不依赖写地址通道,这就是说,写数据可以先于写地址发送,但是总线不知道写地址,没办法将数据发送出去,只能暂存在buffer中,等待写地址。比较理想的方案是总线为每个master预留一个写地址通道buffer和写数据通道buffer。
在这种方案下,若支持写交织,地址通道buffer和数据通道buffer的数据可能永远都对不上(AWID与WID),这会造成该master的所有数据都被堵塞。当然可以采用其他方案来解决这个问题,比如说为每个master分配多个buffer,但实现起来会比较复杂。
合理地设计可以减少写交织被取消带来的影响,master应该在某个transaction的数据准备好之后再向总线发起写请求,否则mater可能长时间占用总线,大大降低总线的效率。因此,设计人员本就应该避免写交织十分高效时的场景,设计合理的情况下,写交织的取消并不会给系统带来明显的效率影响。
-
NVMe协议简介之AXI总线2025-05-17 1912
-
NVMe IP之AXI4总线分析2025-06-02 6262
-
RDMA简介9之AXI 总线协议分析22025-06-24 1059
-
玩转Zynq连载3——AXI总线协议介绍12019-05-06 2825
-
AXI4协议的读写通道结构2021-01-08 2627
-
AXI总线的相关资料下载2022-02-09 897
-
看看Axi4写通道decoder的设计2022-08-03 2619
-
AMBA AXI协议指南2023-08-02 761
-
AXI 总线和引脚的介绍2018-01-05 11508
-
AXI4接口协议的基础知识2020-09-23 7345
-
AXI总线学习(AXI3&4)2021-12-05 1049
-
AXI通道定义及AXI总线信号描述2022-08-04 13047
-
关于AXI BRAM控制器的相关内容2022-11-16 6943
-
AXI总线通道定义2023-10-31 1673
-
ZYNQ基础---AXI DMA使用2025-01-06 4414
全部0条评论

快来发表一下你的评论吧 !
