

Kubernetes 集群及其生态搭建
描述
上一次接触到kubernetes集群的时候已经是一年以前了,那个时候官方的版本还只是v1.10,而现在过去一年的时间了,官方版本已经快速的迭代到了v1.17了,社区也越来越成熟、相关的生态组件也越来越丰富,可见在过去的K8S元年,它发展是多么迅猛。最近想把自己写的一些小东西封装成开放API暴露出来,于是想把自己的几台机器搞成个kubernetes集群,所以这里想重温下集群构建的流程。以下的所有文件都可以在Githubhttps://github.com/lateautumn4lin/KubernetesResearch的ClusterEcology目录中寻找到
kubernetes集群搭建实战
首先要做的是搭建一个最基本的Kubernetes集群。
准备阶段
准备阶段主要包括两个方面,一是准备好至少两台机器,做master-worker的集群架构,二是了解我们需要安装好哪些软件才能构建最基本的集群。
- 机器配置
这次实验我选用的是腾讯云的云服务器CVM,由于我是通过不同的账号购买的,所以我选用的机器之间是通过外网来进行互通,配置方面的话选择官方默认的最低配置2核4GB。
| 服务器IP | CPU | 内存 | 硬盘 | 系统版本 | Hostname |
|---|---|---|---|---|---|
| 192.144.152.23 | 2核 | 4GB | 50GB | Cent OS 7.6 | master1 |
| 49.233.81.20 | 2核 | 4GB | 50GB | Cent OS 7.6 | worker1 |
- 软件配置
| 需要安装的软件 | 版本 |
|---|---|
| Kubernetes | v1.17.x |
| Docker | 18.09.7 |
基本的软件我们需要安装Kubernetes与Docker,安装Kubernetes我们需要使用到其中的Kubeadm与Kubectl工具,Kubeadm是官方推荐的初始化工具,并且在v1.13版本中已经正式GA(General Availability)了,也就是说可以在生产环境中使用。而需要Docker是因为Kubernetes中的Pod需要使用到CRI(Container Runtime),也就是容器运行时,Docker是非常标准且通用的CRI,其他的例如Containerd、CRI-O并且在v1.14版本之后如果你的机器中有多种CRI,那么Kubernetes也会默认使用Docker的,所以我们这里就选择Docker。
检查与配置阶段
这个阶段我们主要是检查我们的服务器配置以及把我们几个服务器给串联起来。
- 修改Hostname,配置Host文件
使用hostnamectl分别对worker1和master1进行hostname的永久性修改,并且配置host,之所以这么做是因为我们要统一给各个机器标记,这样我们在之后的集群管理中能够更好的通过hostname了解每台机器的作用。
hostnamectl set-hostname master1
echo "127.0.0.1 $(hostname)" > > /etc/hosts
echo "192.144.152.23 master1" > > /etc/hosts
echo "49.233.81.20 worker1" > > /etc/hosts
- 检查CPU核数与内存
这一步我们使用lscpu命令来查看我们的服务器的架构以及我们系统的内核数,因为我们要搭建一个Kubernetes集群,master节点不能低于2核,这点是必须要保证的,如果内核数过低会导致整个集群的不稳定和高延迟。
lscpu
# 请使用 lscpu 命令,核对 CPU 信息
# Architecture: x86_64 本安装文档不支持 arm 架构
# CPU(s): 2 CPU 内核数量不能低于 2
- 检查网络
在所有节点执行命令
[root@master1 ~]# ip route show
default via 172.21.0.1 dev eth0
169.254.0.0/16 dev eth0 scope link metric 1002
172.21.0.0/20 dev eth0 proto kernel scope link src 172.21.0.11
[root@master1 ~]# ip address
1: lo: < LOOPBACK,UP,LOWER_UP > mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: < BROADCAST,MULTICAST,UP,LOWER_UP > mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 52:54:00:2c:42:7d brd ff:ff:ff:ff:ff:ff
inet 172.21.0.11/20 brd 172.21.15.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe2c:427d/64 scope link
valid_lft forever preferred_lft forever
3.1 kubelet使用的IP地址
- ip route show 命令中,可以知道机器的默认网卡,通常是
eth0,如default via 172.21.0.1 dev eth0 - ip address 命令中,可显示默认网卡的 IP 地址,Kubernetes 将使用此 IP 地址与集群内的其他节点通信,如
172.21.0.11 - 所有节点上 Kubernetes 所使用的 IP 地址必须可以互通(无需 NAT 映射、无安全组或防火墙隔离)
如果两台机器是在共同的内网中可以使用内网IP进行直接通信,不过我们这次的机器是在两个不同的腾讯云账号之中,彼此内网隔离,所以我们直接使用机器的外网IP进行通信,不建议大家在生产环境中使用。
- 配置机器之间的免登录
这一步我们要通过配置各机器之间的免登录打通各个机器,把各个机器串联起来,这样方便于我们之后在各台机器之间的操作。
4.1 每台服务器生成公私钥
ssh-keygen –t rsa
4.2 将id_rsa.pub追加到授权的key里面去
cat id_rsa.pub > > authorized_keys
4.3 修改.ssh文件夹和其文件的权限,并重启SSH服务
chmod 700 ~/.ssh
chmod 600 ~/.ssh/*
service sshd restart
4.4 将.ssh文件夹中三个文件拷贝到目标服务器
scp ~/.ssh/authorized_keys root@192.144.152.23:~/.ssh/
scp ~/.ssh/id* root@192.144.152.23:~/.ssh/
上面是两台机器之间如何进行免登录配置,同理可以用于其他某两台机器。
正式安装阶段
准备好上面的机器并且检查、配置好各个参数之后我们就可以开始正式安装了。
- 安装Kubelet以及Docker
切换到ClusterEcology目录中,可以看到install_kubelet.sh脚本,使用如下命令快速安装。
cat install_kubelet.sh | sh -s 1.17.2
我们快速看看这个脚本中的代码,了解具体每一步的作用
#!/bin/bash
# 在 master 节点和 worker 节点都要执行
# 安装 docker
# 参考文档如下
# https://docs.docker.com/install/linux/docker-ce/centos/
# https://docs.docker.com/install/linux/linux-postinstall/
# 卸载旧版本
yum remove -y docker
docker-client
docker-client-latest
docker-common
docker-latest
docker-latest-logrotate
docker-logrotate
docker-selinux
docker-engine-selinux
docker-engine
# 设置 yum repository
yum install -y yum-utils
device-mapper-persistent-data
lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装并启动 docker
yum install -y docker-ce-18.09.7 docker-ce-cli-18.09.7 containerd.io
systemctl enable docker
systemctl start docker
# 安装 nfs-utils
# 必须先安装 nfs-utils 才能挂载 nfs 网络存储
yum install -y nfs-utils
yum install -y wget
# 关闭 防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭 SeLinux
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
# 关闭 swap
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak |grep -v swap > /etc/fstab
# 修改 /etc/sysctl.conf
# 如果有配置,则修改
sed -i "s#^net.ipv4.ip_forward.*#net.ipv4.ip_forward=1#g" /etc/sysctl.conf
sed -i "s#^net.bridge.bridge-nf-call-ip6tables.*#net.bridge.bridge-nf-call-ip6tables=1#g" /etc/sysctl.conf
sed -i "s#^net.bridge.bridge-nf-call-iptables.*#net.bridge.bridge-nf-call-iptables=1#g" /etc/sysctl.conf
# 可能没有,追加
echo "net.ipv4.ip_forward = 1" > > /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-ip6tables = 1" > > /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-iptables = 1" > > /etc/sysctl.conf
# 执行命令以应用
sysctl -p
# 配置K8S的yum源
cat <
执行如上的命令之后,如果执行正确的话我们会得到Docker的版本信息
Client:
Version: 18.09.7
API version: 1.39
Go version: go1.10.8
Git commit: 2d0083d
Built: Thu Jun 27 17:56:06 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 18.09.7
API version: 1.39 (minimum version 1.12)
Go version: go1.10.8
Git commit: 2d0083d
Built: Thu Jun 27 17:26:28 2019
OS/Arch: linux/amd64
Experimental: false
- 初始化 master 节点
切换到ClusterEcology目录中,可以看到init_master.sh脚本,我们首先配置好环境变量,然后使用执行脚本快速安装。
# 只在 master 节点执行
# 替换 x.x.x.x 为 master 节点实际 IP(生产请使用内网 IP)
# export 命令只在当前 shell 会话中有效,开启新的 shell 窗口后,如果要继续安装过程,请重新执行此处的 export 命令
export MASTER_IP=192.144.152.23
# 替换 apiserver.demo 为 您想要的 dnsName
export APISERVER_NAME=apiserver.demo
# Kubernetes 容器组所在的网段,该网段安装完成后,由 kubernetes 创建,事先并不存在于您的物理网络中
export POD_SUBNET=10.100.0.1/16
echo "${MASTER_IP} ${APISERVER_NAME}" > > /etc/hosts
cat init_master.sh | sh -s 1.17.2
- 检查 master 初始化结果
上一步安装好之后我们要检验Kubernetes集群的成果,按下面的命令进行执行。
# 只在 master 节点执行
# 执行如下命令,等待 3-10 分钟,直到所有的容器组处于 Running 状态
watch kubectl get pod -n kube-system -o wide
# 查看 master 节点初始化结果
kubectl get nodes -o wide
如果成功的话可以看到以下输出
[root@master1 dashboard]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master1 Ready master 7h26m v1.17.2 172.21.0.11 < none > CentOS Linux 7 (Core) 3.10.0-862.el7.x86_64 docker://18.9.7
表示我们的集群中master节点已经正式可用
- 获得 join命令参数
下面我们要将我们的其余worker节点加入集群,worker加入集群需要得到整个集群的token和ca证书,我们首先需要在master节点上面去获取,包括加入的token和ca证书。
kubeadm token create --print-join-command
# 我们会得到如下输出,这是我们加入集群的凭证
kubeadm join apiserver.demo:6443 --token mpfjma.4vjjg8flqihor4vt --discovery-token-ca-cert-hash sha256:6f7a8e40a810323672de5eee6f4d19aa2dbdb38411845a1bf5dd63485c43d303
- 初始化 worker节点
针对所有的 worker 节点执行
# 只在 master 节点执行
# 替换 x.x.x.x 为 master 节点实际 IP(生产请使用内网 IP)
# export 命令只在当前 shell 会话中有效,开启新的 shell 窗口后,如果要继续安装过程,请重新执行此处的 export 命令
export MASTER_IP=192.144.152.23
# 替换 apiserver.demo 为 您想要的 dnsName
export APISERVER_NAME=apiserver.demo
echo "${MASTER_IP} ${APISERVER_NAME}" > > /etc/hosts
# 替换为 master 节点上 kubeadm token create 命令的输出
kubeadm join apiserver.demo:6443 --token mpfjma.4vjjg8flqihor4vt --discovery-token-ca-cert-hash sha256:6f7a8e40a810323672de5eee6f4d19aa2dbdb38411845a1bf5dd63485c43d303
加入之后我们再使用下面的命令来查看worker是否正确加入集群
kubectl get nodes
- 查看集群整体的状况
查看集群整体状况只能在master节点执行如下命令
kubectl get nodes -o wide
可以看到如下的输出,集群都Ready就表示节点可用
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 5m3s v1.17.2
worker1 Ready < none > 2m26s v1.17.2
生态组件构建
安装好Kubernetes集群之后,我们得到的只是一个最基本的集群,还有很多问题我们没有解决,比如说我们想要通过可视化的方式通过页面点击的方式来操作整个集群,或者说我们想要一个类似于Python中的pip那样的包管理工具那样利用类似工具来管理我们部署在Kubernetes集群的应用,再或者我们想要让我们的集群和外网能够进行很方便的通信等等,所以这就需要我们利用其它的组件来不断完善我们的Kubernetes生态。
我们选用的是如下的软件
| 需要安装的软件 | 版本 |
|---|---|
| Kubernetes Dashboard | v2.0.3 |
| Helm | v3.0.3 |
| Traefik | xxx |
| metrics-server | xxx |
- Dashboard插件
安装Dashboard是因为它是一个综合性的管理平台,也是属于Kubernetes 的官方项目,具体可以在这个仓库去看https://github.com/kubernetes/dashboard,虽然之前Dashboard因为操作不人性化,界面丑而广泛被人诟病,但是经过Kubernetes Dashboard团队半年多闭关研发,Dashboardv2.0版本新鲜出炉,界面和操作性也有很大提升,也是官方推荐的管理界面之一。
1.1 Dashboard插件安装
具体的部署方案我根据官方的方案整理成了几个Yaml文件,项目都在目录ClusterEcology/InitDashboard下面
kubectl apply -f k8s-dashboard-rbac.yaml
kubectl apply -f k8s-dashboard-configmap-secret.yaml
kubectl apply -f k8s-dashboard-deploy.yaml
kubectl apply -f k8s-dashboard-metrics.yaml
kubectl apply -f k8s-dashboard-token.yaml
执行好上面的命令之后Dashboard的服务以及用户基本已经创建好,下面我们需要获取用户token来登录我们的Dashboard
1.2 获取用户Token
kubectl describe secret/$(kubectl get secret -n kube-system |grep admin|awk '{print $1}') -n kube-system
1.3 检查服务是否可用
在之前的Yaml文件中设置了NodePort端口为31001和类型为NodePort方式访问 Dashboard,所以访问地址:https://192.144.152.23:31001/ 进入 Kubernetes Dashboard页面,然后输入上一步中创建的ServiceAccount的Token进入 Dashboard,可以看到新的Dashboard。
输入Token我们可以看到Dashboard的界面,如下所示是正常的Dashboard界面
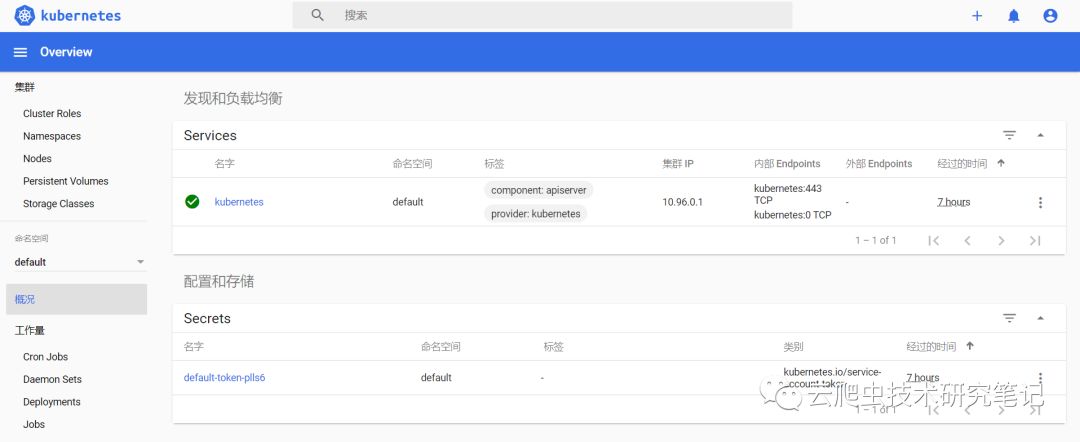
- Helm组件
Helm组件的产生也是源于一个关键痛点,就是我们虽然已经部署好Kubernetes集群环境,但是每个微服务也得维护一套Yaml文件,而且每个环境下的配置文件也不太一样,所以想要重新部署新的环境或者做环境移植的成本是真的很高。如果我们能使用类似于yum那样的工具来安装我们的应用的话岂不是会方便很多?基于这点,Helm就诞生了,从此让Kubernetes集群拥有一个正式的应用市场。
旧版本Helm整体分为两个部分,包括Helm Client和Tiller Server,Helm Client主要是用户命令行工具,负责管理用户自定义的包文件,而Tiller Server服务接受Client的请求并且解析请求之后与Kubernetes集群进行交互。
而新版本,也就是Helm3之后,Helm移除了Tiller组件,使用Helm命令会直接使用了kubeconfig来与Kubernetes集群通信,这样就可以做更细粒度的权限控制,这样方便了完成和使用,另一个好处是Release name范围缩小至Namespace,这样就能够保证不同的NameSpace可以使用相同的Release name。
2.1 Helm Client组件安装
我们首先要去官网https://github.com/kubernetes/helm/releases去下载Helm的压缩包。
解压后将可执行文件Helm拷贝到/usr/local/bin目录下即可,这样Helm客户端就在这台机器上安装完成了。
cp helm /usr/local/bin/
2.2 Helm使用
初始化Helm
helm init --client-only --stable-repo-url https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts/
helm repo add incubator https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/
helm repo add seldon https://storage.googleapis.com/seldon-charts
helm repo update
安装一个最简单的服务
helm install seldon-core seldon/seldon-core-operator
可以看到Helm已经和Kubernetes集群交互从而生成一个seldon-core的服务了
[root@master1 linux-amd64]# helm install seldon-core seldon/seldon-core-operator
NAME: seldon-core
LAST DEPLOYED: Tue Feb 4 22:43:58 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
[root@master1 linux-amd64]# helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
seldon-core default 1 2020-02-04 22:43:58.232906547 +0800 CST deployed seldon-core-operator-1.0.1
- Traefik组件
3.1 Traefik组件安装
Traefik是另一个Kubernetes集群中必备的组件,可以把它认为是Nginx的替代品,做一个统一网关的管理工具,它的优点也是有几个方面,比如有漂亮的dashboard 界面、可基于容器标签进行配置、新添服务简单,不用像 nginx 一样复杂配置,并且不用频繁重启等等,虽然性能方面和Nginx会有些许差距,但是作为个人使用的话,还是很让人爱不释手的。
- metrics-server插件
metrics-server是Kubernetes 官方的集群资源利用率信息收集器,是Heapster瘦身后的替代品。metrics-server收集的是集群内由各个节点上kubelet暴露出来的利用率信息,算是集群中基础的监控信息了,主要是提供给例如调度逻辑等核心系统使用。
git clone https://github.com/kubernetes-incubator/metrics-server.git
cd metrics-server/
kubectl create -f deploy/1.8+/
安装成功后,过一段时间我们就可以在Dashboard中看到具体的监控信息了
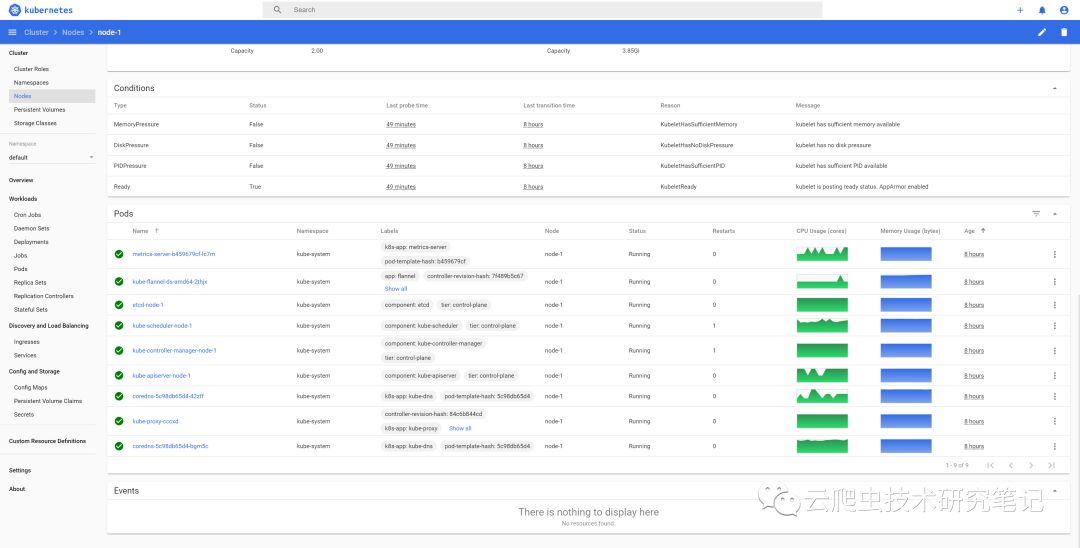
疑难故障分析
有关于Kubernetes集群的疑难故障主要分为几类:
(1)资源调度类
(2)网络通信类
(3)配置参数类
大多数问题都是围绕这三点来进行的(不全是,大佬勿喷),下面列举我这次安装中某些问题,有些问题在此次安装中没有涉及到,所以以后涉及到的话会讲解。
- 节点不允许被调度
我们在安装过程中会遇到下面这个问题
1 node(s) had taints that the pod didn't tolerate
这个表示某个节点被标记为不可调度,这个是K8S官方默认的,因为这个是确保Master节点不会被调度到额外的容器从而消耗资源,不过我们这个实验中可以设置所有节点允许调度来避免出现这个问题。
kubectl taint nodes --all node-role.kubernetes.io/master-
- 镜像问题
按照上面的安装步骤理论上是可以完全正确的部署好K8S集群的,不过安装速度会根据网速的情况有差异,我在安装的时候也安装了一个多小时,原因也是因为镜像下载的慢,当我们看到某些pod一直在pending的时候,我们可以通过如下命令查看具体的情况。
kubectl describe pod calico-node-ndwqv -n kube-system
使用到describe命令来查看具体组件的情况,虽然也可以使用logs命令来查看,不过不如describe方便。
- Chrome 您的连接不是私密连接
创建好Dashboard之后,第一次通过Chrome登录Dashboard我们会发现报出这个错误您的连接不是私密连接,这个是由于Chrome最新版本的错误导致,我们修改启动参数就可以了。
- 相关推荐
- 热点推荐
- 服务器
- 机器
- 容器
- kubernetes
-
KubePi:开源Kubernetes可视化管理面板,让集群管理如此简单2026-02-11 604
-
阿里云上Kubernetes集群联邦2018-03-12 2966
-
kubernetes集群配置2019-08-19 1519
-
请问鸿蒙系统上可以部署kubernetes集群吗?2022-06-08 1513
-
如何部署基于Mesos的Kubernetes集群2017-10-09 1071
-
浅谈Kubernetes集群的高可用方案2017-10-11 1186
-
从零开始搭建Kubernetes集群步骤2021-09-01 4511
-
在Kubernetes集群发生网络异常时如何排查2022-09-02 10441
-
Kubernetes 集群的功能2022-09-05 2055
-
Kubernetes集群的关闭与重启2022-11-07 11113
-
在树莓派上搭建Kubernetes智能边缘集群2022-12-09 814
-
Kubernetes的集群部署2023-02-15 2991
-
基于Kubernetes集群的typecho博客搭建方案2023-10-30 2440
-
使用Velero备份Kubernetes集群2024-08-05 1522
-
Kubernetes集群搭建容器云需要几台服务器?2024-10-21 1092
全部0条评论

快来发表一下你的评论吧 !
