

第一个基于DETR的高质量通用目标检测方法
描述
概述
目标检测是具有广泛实际应用的计算机视觉任务,如自动驾驶和医学影像。随着DETR 的出现,基于Transformer的检测器的发展令人瞩目,并且在最新的DETR系列方法在COCO挑战中以明显的优势击败了基于CNN的检测器。
但是,现有DETR系列模型在非COCO数据集上表现较差,且预测框不够准确。
本文提出了Cascade-DETR用于高质量通用目标检测。我们通过提出Cascade Attention层同时解决不同域的泛化问题和定位精度问题,它通过限制注意力到先前的预测框,将以对象中心的信息直接输入到检测解码器中。为进一步提高准确性,我们还重新访问查询分数。我们预测查询期望的IoU,而不再依赖于分类分数,从而大大提高了校准后的置信度。最后,我们引入了通用目标检测基准UDB10,其中包含10个数据集。同时在COCO上也推进了最先进的技术,Cascade-DETR大大改进了UDB10中所有数据集上的基于DETR的检测器的性能 ,在某些情况下甚至提高了超过10 mAP。在严格的质量要求下,提升甚至更加明显。这里也推荐「3D视觉工坊」新课程《国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程》。
背景简述
现有的DETR系列模型在非COCO数据集上表现较差,且预测框不够准确。其主要原因是:DETR在检测头中用全局交叉注意力替换了原来的卷积,删除了以中心为中心的先验知识;另一方面,DETR仅依赖分类分数评分查询提议,忽略了定位质量。考虑到这些问题,我们主要进行了以下两个方面创新:
方法:(1) 提出连续注意力机制,将交叉注意力逐层限制在先前预测框内,以聚焦对象区域并引入对象中心先验知识。(2) 添加IoU预测分支,以感知每一个查询建议的定位质量,用于重新标定查询得分。
网络:(1) 引入连续注意力的检测Transformer解码器,包含多个解码层。(2) 每层连续注意力使用上一层的预测框约束其注意力区域。
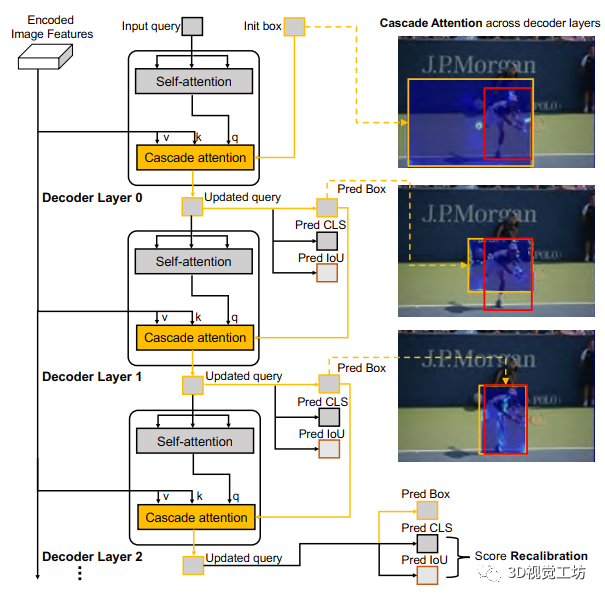
图1 Cascade DETR 的transformer解码器
方法解析
在本节中,首先介绍了标准DETR解码器的设计。然后分析了Cascade-DETR整体架构,最后逐一解释了连续注意力、IoU感知查询、再标定训练和推理细节。
1.标准DETR解码器
标准DETR解码器是由一组交叉注意层和自注意层组成,这些层迭代更新一组查询,初始化为可学习的常量。在第i层,查询Q∈RN×D首先输入到自注意模块,接着进行图像特征的交叉注意,其大小为H×W×D。交叉注意力计算为对整个特征图的加权和,
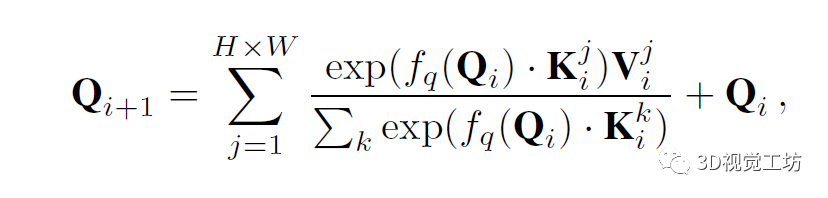
其中K和V分别表示从图像特征中提取的键和值图。索引i表示交叉注意力层,j是图像上的2D空间位置,fq表示查询变换函数。
更新的查询Qi+1然后分别通过两个并行线性层fbox和fscore输入到边界框B(i+1)和查询分数S(i+1)的预测中,即B(i+1)=fbox(Q(i+1))和S(i+1)=fcls(Q(i+1))。大小为N×(C+1)的查询分数矩阵S(i+1)包含数据集所有C类的所有输入查询的类别概率。
2.Cascade-DETR架构
在这一节中,我们介绍Cascade-DETR的架构,其向标准转换解码器引入局部目标中心偏置。与现有的基于DETR的方法(如DAB-DETR和DN-DETR)类似,我们的架构包含transformer编码器来提取图像特征。编码的特征与位置编码一起输入到transformer解码器。可学习查询也输入到解码器中,以通过交叉注意力进行目标定位和分类。Cascade-DETR中,连续注意力和IoU感知查询重新标定是两个新模块,这两个模块几乎不增加计算时间或模型参数,但显著提高了检测质量和泛化能力。
3.连续注意力

图2 DNDETR和Cascade-DN-DETR在COCO和Cityscapes数据集上的交叉注意力图的可视化比较
在标准DETR解码器中,可学习查询在整个图像要素上全局参与,如式1所示。然而,为了准确实现目标分类和定位,我们认为对象周围的局部信息最为关键。全局上下文可以通过查询之间的自注意提取。在图2中,我们观察到在COCO训练期间,交叉注意力分布趋于收敛到预测对象位置周围的区域。尽管transformer模型可以端到端学习这种归纳偏置,但它需要大量的数据。当训练数据集较小或图像样式与ImageNet中的样式完全不同时,这个问题变得更加显著。
为解决上述问题,我们将对象中心先验视为已知约束,以将其整合到初始化过程和训练程序中,如图1所示。我们在第i+1层设计连续注意力为:
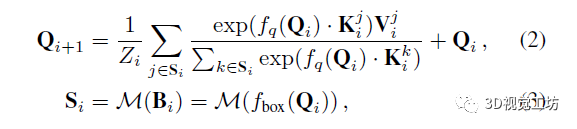
其中Si是前一解码层i中的预测边界框Bi内的2D位置集合。连续结构利用DETR系列检测器中每个解码层后预测的Bi将更准确的属性。因此,框约束的交叉注意力区域Si不仅带来对象中心偏置,而且会逐层加强(参见图1)。随着每层可以获得更准确的交叉注意特征,连续注意力反过来也可提升每层的检测准确率。
我们通过图2中的注意力图验证了我们的假设。我们同时展示了COCO和Cityscapes上DN-DETR模型的初始和最终注意力图。在COCO上,我们观察到无论使用DN-DETR还是Cascade-DN-DETR,随机初始化查询的交叉注意力最终都会收敛到语义明显不同的位置。然而,在Cityscapes上,两种方法之间存在明显对比,对象中心知识的融合将注意力集中在图像最相关的部分更为重要。
与其他方法相比,我们的Cascade-DETR设计更简单。DETR解码器中的每层预测框都直接用于约束下一层的交叉注意力范围。这种归纳偏置使DETR能够快速收敛,并且在特别是小型和多样化数据集上拥有卓越的性能。
4.IoU感知查询再标定
大多数基于DETR的检测器将300甚至900个可学习查询作为输入提供给transformer解码器,并为每个查询预测一个框。在计算最终检测结果时,采用分类置信度作为所有查询提议的排序标准。然而,分类分数并没有明确考虑预测边界框的准确性,这对于选择高质量提议至关重要。因此,我们引入了IoU感知查询重新标定,通过添加IoU预测分支来重新标定查询的置信度,以获得更准确的校准置信度,这更好地反映了预测的质量。
我们不再使用分类置信度对查询进行评分,而是使用其与真值框的期望IoU进行评分。令E(IoUq)为查询q的期望真值IoU。此外,令P(objq)表示从分类概率获得的q指示对象的概率。查询的期望IoU计算为
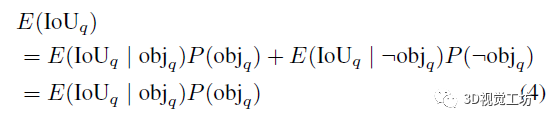
这里,¬表示否定二值随机变量。第二个等号遵循非对象的期望IoU为零:E(IoUq|¬objq)=0。
为预测期望IoU(4),我们引入一个额外的分支来预测存在地面实况的期望IoU E(IoUq|objq),如图1所示。具体而言,我们在平行于分类和框回归分支之外简单地再使用一个线性层。如式(4)中导出的,最后的查询分数然后计算为预测IoU与原始分类置信度P(objq)的乘积。
我们用L2损失监督IoU预测与地面真值IoUGTq之间的差异,
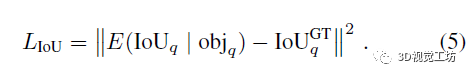
仅当查询q具有分配的对应真值时才应用损失,因为我们在期望值中对对象的存在进行了条件化。注意,L2损失意味着学习高斯分布上IoU值的均值,即期望值。我们在实验部分的表5中对这个损失选择进行分析。这里也推荐「3D视觉工坊」新课程《国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程》。
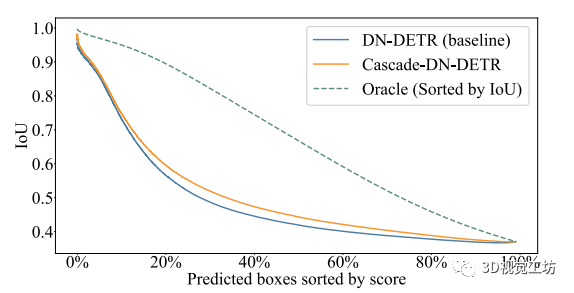
图3 查询定位质量(IoU到GT框)和查询评分之间的稀疏图
为分析我们的IoU感知查询再标定的优势,我们在COCO上的所有预测上生成稀疏化图,如图3所示。根据置信度对所有预测进行排序。然后绘制拥有最高置信度的前N个预测的平均IoU,通过在x轴上变化N。Oracle表示上确界,通过考虑地面真值IoU获得。与不进行查询再标定的Cascade-DN-DETR(蓝色曲线)相比,我们的再标定结果(橙色曲线)得出了明显更好的结果排序,从而导致更高的IoU。
5.训练和推理细节
我们使用多任务损失函数端到端训练我们的Cascade-DETR,
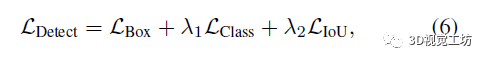
其中LDetect同时监督位置预测和类别分类,源自DETR检测器。超参数λ1和λ2平衡损失函数在验证集上分别设置为{1.0,2.0}。在每个解码层后采用FFN和匈牙利损失。FFN在每个预测层中共享模型参数。
在推理期间,我们一致使用连续注意力,因为它仅依赖于DETR解码器中每层的预测框。对于查询评分的校准方式,如第4节所述,我们仅将其应用于最终的transformer解码器层。
实验结果
我们在COCO、UVO、Cityscapes和构建的UDB10基准测试集上将Cascade-DETR与最新目标检测方法进行了比较。我们将Cascade-DETR集成到三个代表性方法中,发现Cascade-DETR相对于强基线获得了一致的大幅提升。
结论
我们提出了Cascade-DETR,是适用于高质量通用目标检测的第一个基于DETR的检测器。通过引入局部对象中心先验知识,Cascade-DETR在通用检测应用中实现显著优势,特别是在更高的IoU阈值下。与其他基于DETR的检测器相比,我们的方法不仅在COCO数据集表现优异,也可以在更多的现实生活和实际应用场景中展现出良好的性能。
-
如何做一个高质量的毕业设计?2010-01-26 3609
-
protel输出高质量gerber2011-12-12 26574
-
高质量C++、C编程指南2012-08-06 5157
-
高质量C&C++2012-08-16 2765
-
高质量C语言编程2013-07-22 14111
-
编写高质量C语言代码2013-07-31 4814
-
林锐《高质量C语言编程》2013-08-17 2481
-
高质量c语言高级教程2015-01-07 3292
-
高质量编程2016-02-27 7326
-
高质量音频改变我们的收听方式2018-09-04 3167
-
【下载】高质量干货-22本高质量EMC电磁兼容性设计资料2020-03-20 6023
-
请问怎么才能设计出高质量的印制线路板?2021-04-23 1550
-
设计一个高质量、可制造的柔性印制电路的原则是什么?2021-04-26 1719
-
港大&腾讯提出DiffusionDet:第一个用于目标检测的扩散模型2022-11-22 3435
-
百度开源DETRs在实时目标检测中胜过YOLOs2024-03-06 4294
全部0条评论

快来发表一下你的评论吧 !
