

任意模型都能蒸馏!华为诺亚提出异构模型的知识蒸馏方法
描述
自知识蒸馏方法在2014年被首次提出以来,其开始广泛被应用于模型压缩领域。在更强大教师模型辅助监督信息的帮助下,学生模型往往能够实现比直接训练更高的精度。然而,现有的知识蒸馏相关研究只考虑了同架构模型的蒸馏方法,而忽略了教师模型与学生模型异构的情形。例如,最先进的MLP模型在ImageNet上仅能达到83%的精度,无法获取精度更高的同架构教师模型以使用知识蒸馏方法进一步提高MLP模型的精度。因此,对异构模型知识蒸馏的研究具有实际应用意义。
本文的研究者们分析了针对异构模型(CNN,ViT,MLP)特征的差异性,指出特征中模型架构相关的信息会阻碍知识蒸馏的过程。基于此观察,研究者们提出了名为OFAKD异构模型知识蒸馏方法:该方法将特征映射到架构无关的统一空间进行异构模型蒸馏,并使用一种能够自适应增强目标类别信息的损失函数。在CIFAR-100和ImageNet数据集上,该方法实现了对现有同架构知识蒸馏方法的超越。
异构模型间的特征差异
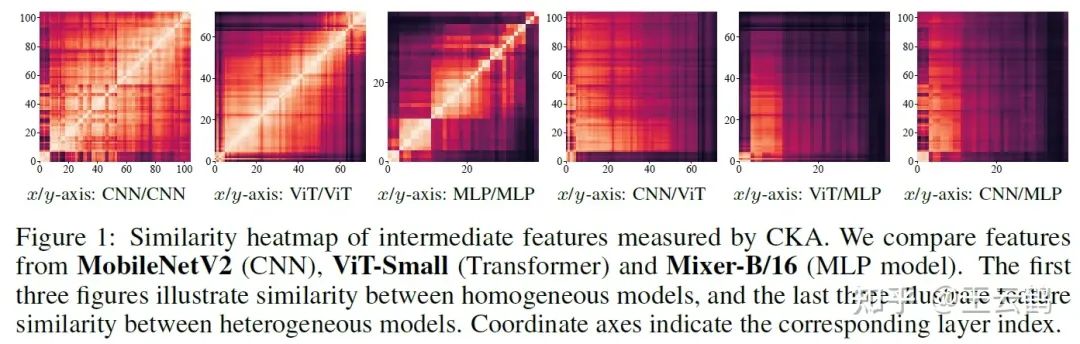
图1 异构模型学习到的特征对比
相比于仅使用logits的蒸馏方法,同步使用模型中间层特征进行蒸馏的方法通常能取得更好的性能。然而在异构模型的情况下,由于不同架构模型对特征的不同学习偏好,它们的中间层特征往往具有较大的差异,直接将针对同架构模型涉及的蒸馏方法迁移到异构模型会导致性能下降。
通用的异构模型蒸馏方法
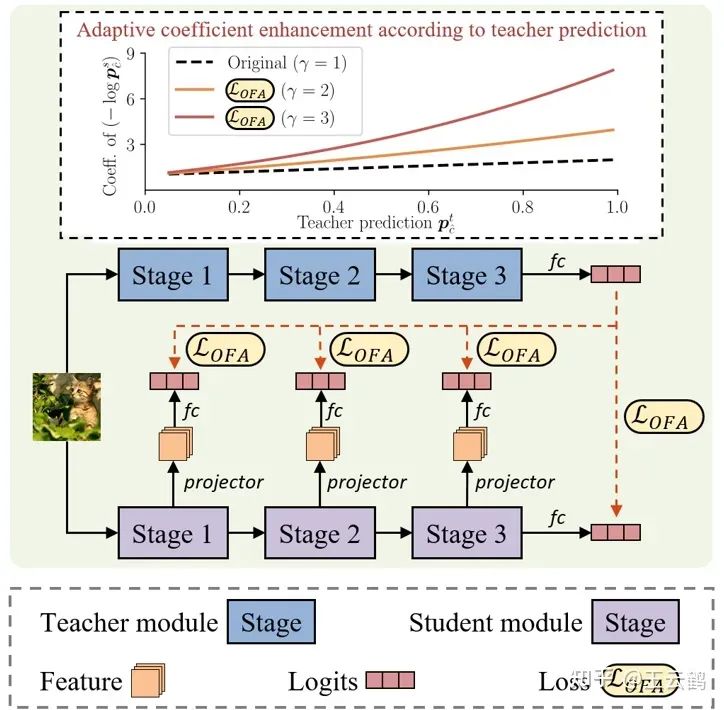
图2 异构模型的知识蒸馏方法
为了在异构模型蒸馏过程中利用中间层特征,需要排除特征中模型架构相关信息的干扰,仅保留任务相关信息。基于此,研究者们提出通过将学生模型的中间层特征映射到logits空间,实现对模型架构相关信息的过滤。此外通过在原始基于KL散度的蒸馏损失函数中引入一项额外的调节系数,修正后的损失函数能够实现对目标类别信息的自适应增强,进一步减缓异构模型蒸馏时无关信息的干扰。
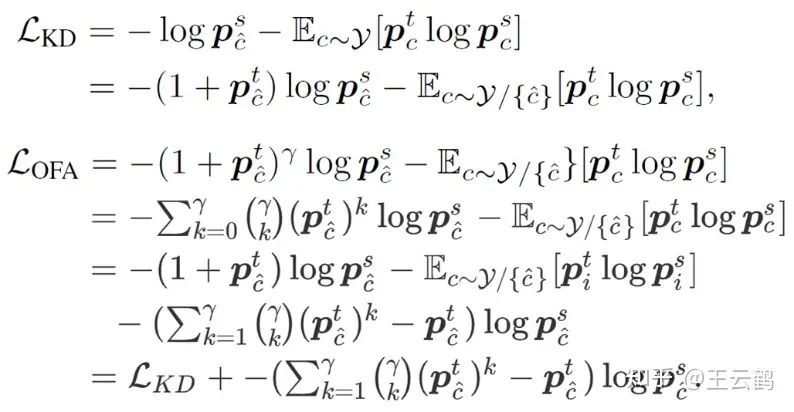
图3 原始蒸馏损失与改进后蒸馏损失的对比
实验结果
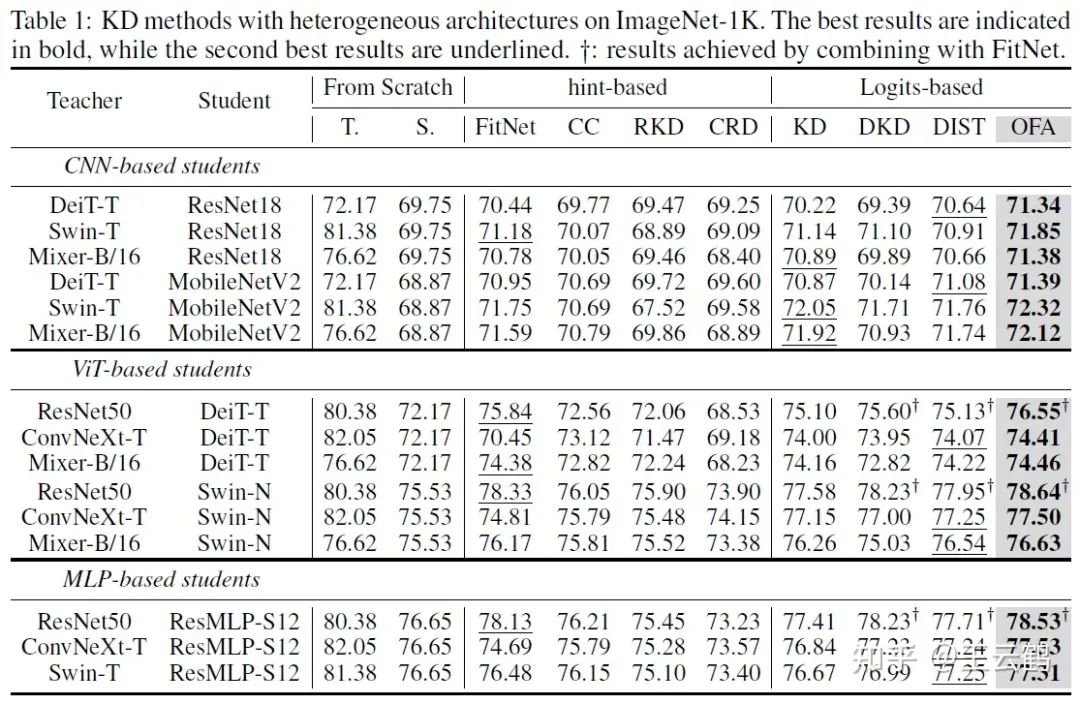
图4 在ImageNet上的异构模型蒸馏结果
上表展示了在ImageNet上的异构蒸馏结果。在所有架构的六种可能异构组合中,本文OFAKD方法都得到了超越现有方法结果。
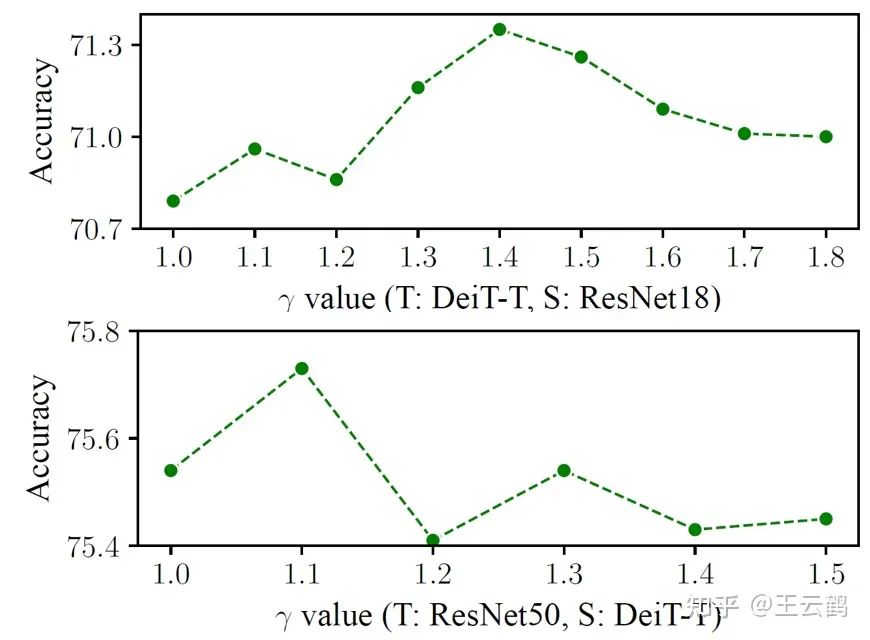
图5 不同值对结果的影响
上表在ImageNet上比较了不同的值设置对结果的影响。可以看出,通过选取合适的值设置,改进后的蒸馏损失函数能得到超越原始蒸馏损失函数的结果。

图6 在ImageNet上的同构模型蒸馏结果
本文在ImageNet上与传统同构模型蒸馏方法进行了对比。在常见的ResNet34和ResNet18同构教师学生模型组合上,OFAKD也具有与现有SOTA方法相当的表现。
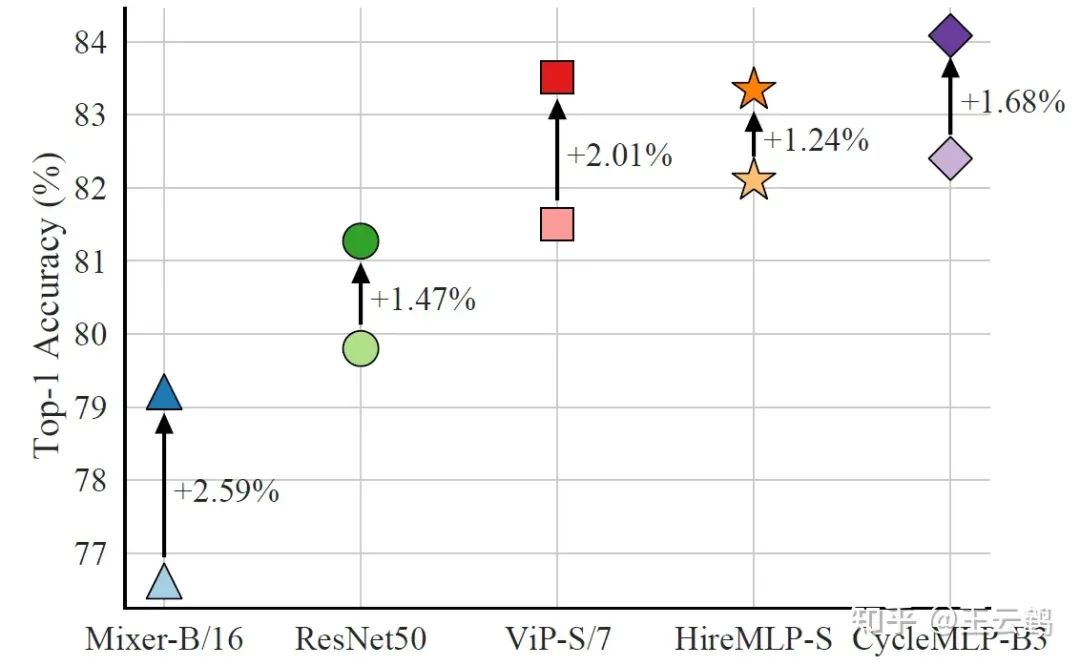
图7 MLP学生模型的蒸馏结果
最后,本文比较了文首提到的MLP作为学生模型时的蒸馏结果。通过选用ViT架构的BEiT v2-base作为教师模型,仅中等尺寸的CycleMLP-B3就刷新了MLP模型在ImageNet上的最佳结果。
结论
本文研究了异构模型之间的知识蒸馏方法,通过将学生模型中间层特征映射到logits空间来拟合教师模型最终输出,并使用在原始知识蒸馏损失函数基础上改进而来的自适应目标信息增强损失,提出的OFAKD方法在多种数据集和教师学生模型组合上实现了对现有方法的超越,扩展了知识蒸馏的应用范围。
-
异构模型的配电网信息交互2018-01-23 1134
-
微软亚洲研究院的研究员们提出了一种模型压缩的新思路2020-11-24 2429
-
深度学习:知识蒸馏的全过程2021-01-07 7068
-
针对遥感图像场景分类的多粒度特征蒸馏方法2021-03-11 1327
-
基于知识蒸馏的恶意代码家族检测方法研究综述2021-04-20 990
-
若干蒸馏方法之间的细节以及差异2022-05-12 2513
-
关于快速知识蒸馏的视觉框架2022-08-31 1778
-
用于NAT的选择性知识蒸馏框架2022-12-06 1555
-
南开/南理工/旷视提出CTKD:动态温度超参蒸馏新方法2023-01-04 1767
-
如何度量知识蒸馏中不同数据增强方法的好坏?2023-02-25 1889
-
蒸馏也能Step-by-Step:新方法让小模型也能媲美2000倍体量大模型2023-05-15 1509
-
如何将ChatGPT的能力蒸馏到另一个大模型2023-06-12 3272
-
TPAMI 2023 | 用于视觉识别的相互对比学习在线知识蒸馏2023-09-19 2808
-
大连理工提出基于Wasserstein距离(WD)的知识蒸馏方法2025-01-21 1466
-
摩尔线程宣布成功部署DeepSeek蒸馏模型推理服务2025-02-06 1544
全部0条评论

快来发表一下你的评论吧 !
