

chatGPT的175Billion个参数是哪儿来的
描述
最近大语言模型模型LLM很火,大家总是说chatgpt的175Billion参数。做算法的人更关心网络的结构,而我这种做硬件的人一直很好奇这个参数是怎么计算的。
最近看到了一篇文章,计算了参数的个数并且和chatgpt论文里的参数进行了比较,计算的还是比较准确的,我来总结一下。
1.Chatgpt背景
Chatgpt(chat generative pre-trained transformer)也是基于google最初的transformer模型,虽然LLM功能很强大,但是理解起来比fasterRCNN和LSTM好很多。
Transformer结构
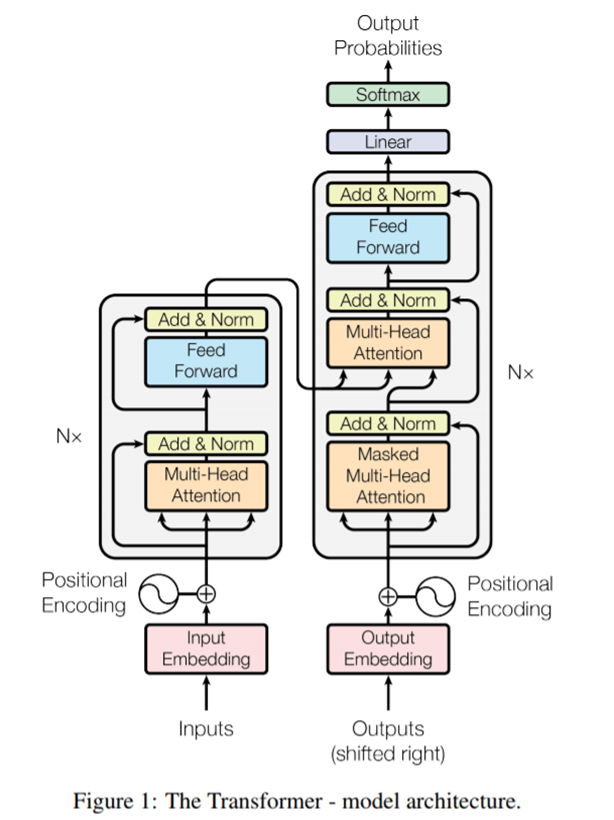
Chatgpt结构
不同于从input到output可以进行翻译工作的transformer结构,ChatGPT进行对话,只需要右侧的decoder部分就可以。
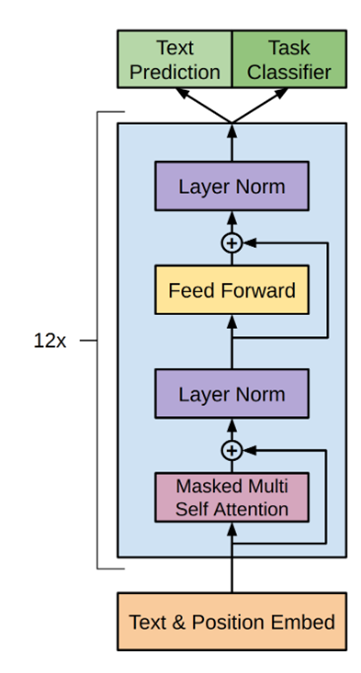
2.一张立体图:
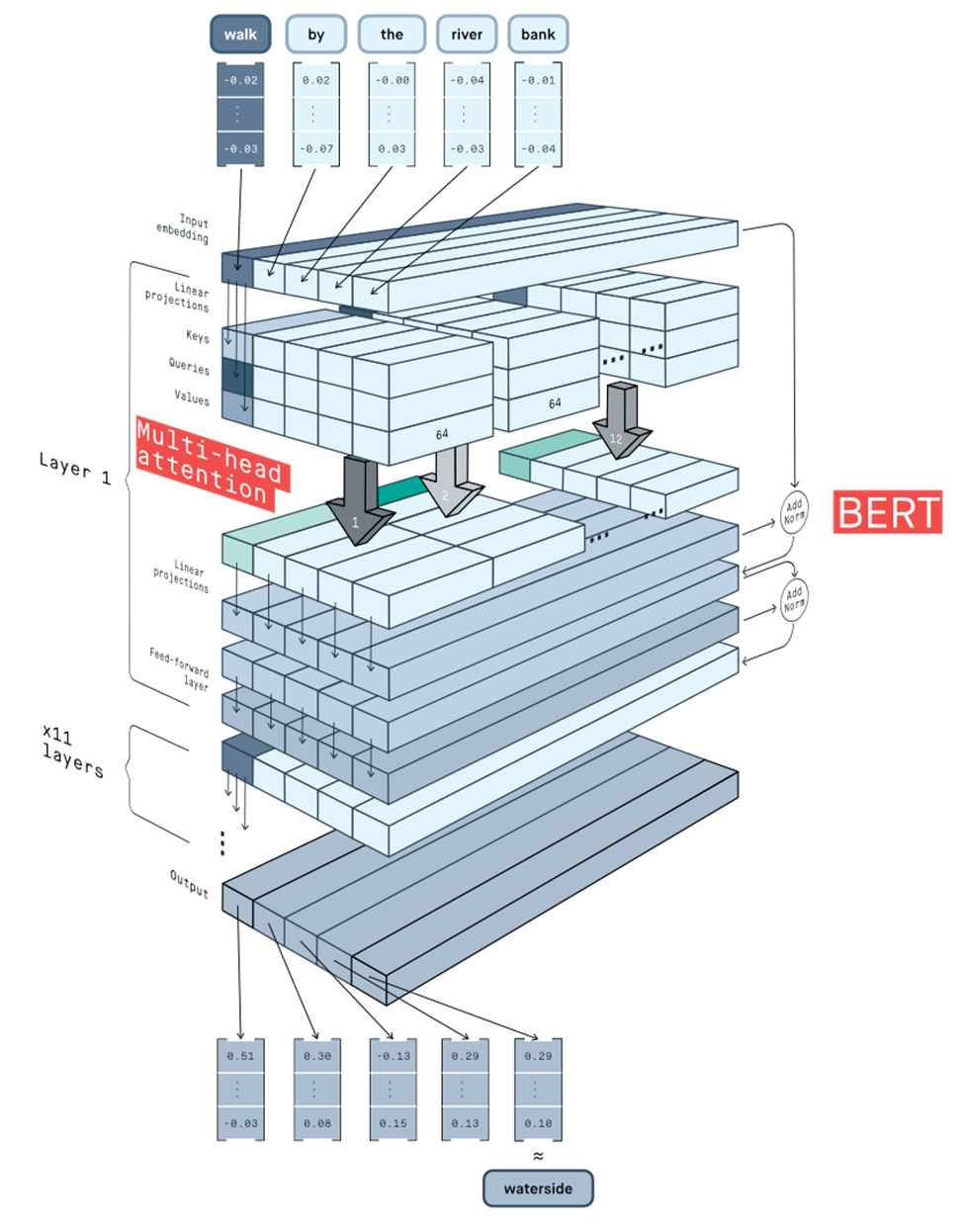
整体的Bert 结构
看了很多解释图,上面的图是看过的最好的,流程就是
1)inputembedding 分别和key,value,query的矩阵做乘法linear projection,得到的结果进行attention
2)将多个attention的结果进行concat拼接,得到的结果进行再次进行矩阵乘法,linearprojection
3)将得到的结果输入feedforwardnetwork,两层的lineartransform之后,输出结果
4)如果有n_layer个layer,那么就重复2)和3)n_layer次
3.具体的参数个数计算
先解释一下参数:
n_head : attention 中head的个数
d_model: 中间bottlenecklayer的向量的维度
n_vocalulary: 字典的维度
n_context: 上下文的长度
n_layer:网络的层数
1)Inputembedding

对应UWe将U的(n_context,n_vocalulary) 维转为UWe(n_context, d_model)维,其矩阵大小为(n_vocabulary,d_model) , 参数大小即为n_vocabulary* d_model。
此外,Wp对应(n_context,d_model)。 因此此处的参数个数为: n_vocabulary*d_model+ n_context * d_model
2)Attention& MultiHead
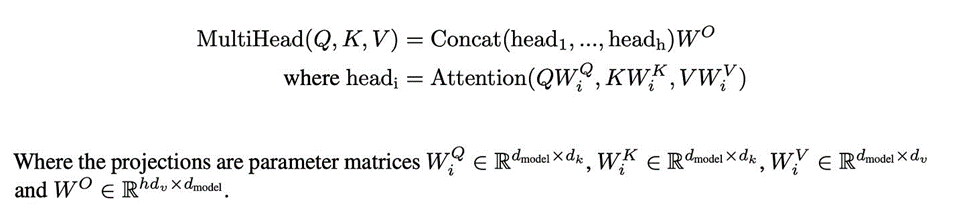
a. WiQ, WiK,WiV都是相同的大小投影矩阵,每个都是d_model*d_head维度,这里的d_head就对应上面公式里面的de, ,dk,dv,ChatGPT中他们都是同样的大小;
b. 因此attention部分的计算量就是3*d_model*d_head,因为有三个矩阵WiQ,WiK, WiV;
c. 如果有MultiHead,如果head的个数为n_head,那么即为W矩阵的总参数3*d_model*d_head*n_head
d. concat的结果的维度为(n_context,n_head*d_head),经过矩阵WO计算后维度变为(n_context,d_head)维,因此WO的维度为(n_head*d_head,d_head) 对c)和d)的参数求和,此时参数个数为 4*d_model*d_head*n_head
3)feedforward
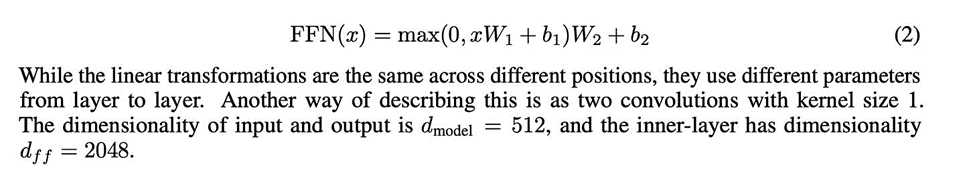
在chatgpt中,feedforward内部由两层lineartransformer组成,并且d_ff为d_model的4倍。 W1的参数个数为(d_model,d_ff), b1的参数个数为d_ff,W2的为(d_ff,d_model),b2的参数个数为d_model,而d_model又是d_ff的四倍,因此: 2*d_model*d_ff+d_model+d_ff 即 8*d_model2+ 5* d_model 4)将2)和3)重复n_layer次 n_layer * (4*d_model*d_head*n_head+ 8*d_model2 + 5* d_model)
总体的参数计算:1)+ 4):
n_vocabulary*d_model-> embedding atrix
+n_context * d_model-> position matrix
+ n_layer * -> layer 重复N次
// multi head attention
(4 * d_model * d_head * n_head ->
// feedforward network
+ 8 * d_model2+ 5* d_model )
验证一下:
如果按照chatGPT论文中设置的参数:
n_vocabulary = 50257
d_model = 12288
n_context = 2048
n_layer= 96
d_head= 128
n_head= 96
1)word_embeding + position
50257 * 12288 + 2048 * 12288 = 642723840
2)Attention& MultiHead
单层:4 * 12288 * 128 * 96 = 603979776
3)feedforward
8 * 12288 * 12288 + 5 * 12288= 1208020992
4)2)和3)重复n_layer次
N_layer = 96 层 96*(603979776+1208020992) = 173952073728
1)+2) = 174594797568 也就是所说的175Billion个参数。
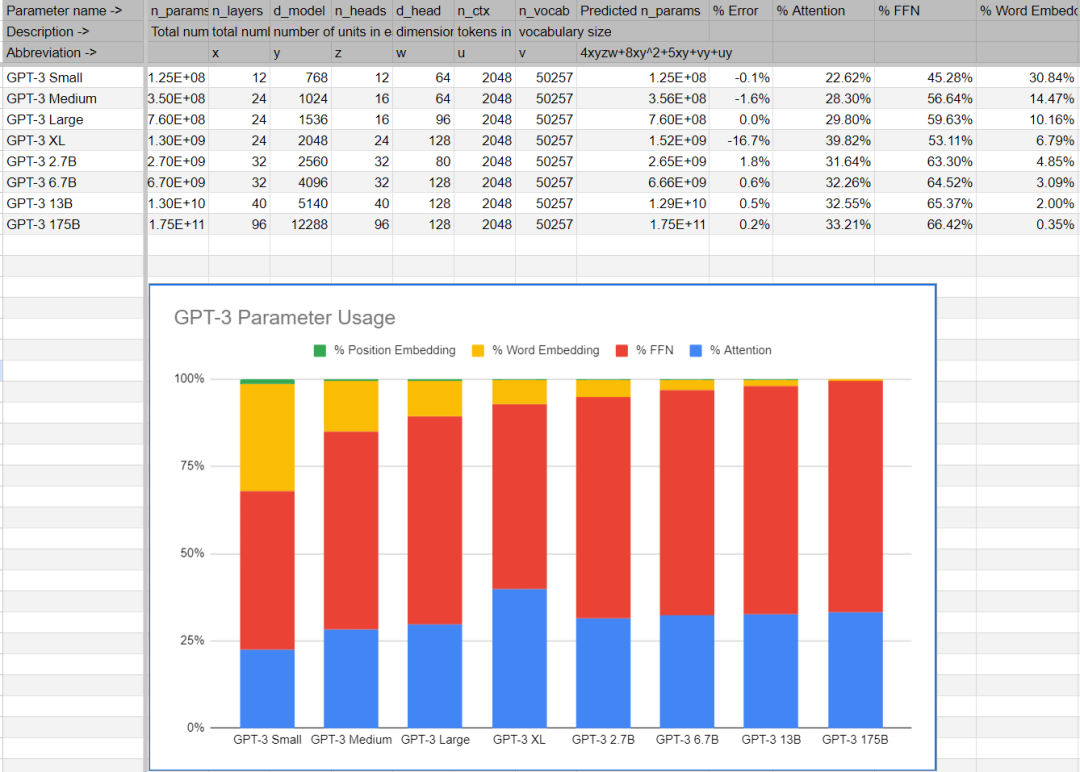
这个方法估计出的参数和论文中参数的对比:
审核编辑:刘清
-
在FPGA设计中是否可以应用ChatGPT生成想要的程序呢2024-03-28 48946
-
【国产FPGA+OMAPL138开发板体验】(原创)6.FPGA连接ChatGPT 42024-02-14 51744
-
如何使用Rust创建一个基于ChatGPT的RAG助手2023-10-24 2729
-
ChatGPT系统开发AI人功智能方案2023-05-18 23982
-
【米尔MYD-JX8MMA7开发板-ARM+FPGA架构试用体验】4.使用ChatGPT来助力测试GPU2023-04-10 2369
-
一个令人惊艳的ChatGPT项目,开源了!2023-03-31 3250
-
关于ChatGPT八个技术问题的猜想2023-03-03 1066
-
#chatgpt 使用chatGPT辅助开发第一弹-电路设计,让它设计一个放大电路,看下效果#人工智能jf_82140138 2023-02-27
-
ChatGPT了的七个开源项目2023-02-15 847
-
ChatGPT入门指南2023-02-10 3038
-
HMC175 S参数2021-03-23 555
全部0条评论

快来发表一下你的评论吧 !
