

如何处理重现使用仿真发现的死锁漏洞
描述
在上一部分中,我们重点讨论了在组件上设置形式验证的最佳实践。那么现在设置已经准备就绪,协议检查器可以避免不切实际的情况(这也有助于发现一个新漏洞),基本抽象也可以提高性能。现在的任务便是如何处理重现使用仿真发现的死锁漏洞?
重现死锁漏洞
重现死锁漏洞要确保设计无死锁,其中一种方法是验证它是否 "最终 "能够响应请求。”最终“这个措辞很重要,无论当前状态如何,也无论我们必须等待多少个周期,设计都必须在未来做出响应。而这可以很好地通过一种称为 "有效性属性 "的 SystemVerilog 断言来实现:
can_respond: assert property(s_eventually design_can_respond);
对于正在验证的缓存,我们在Worker端口上定义了该属性:
resp_ev:assert(s_eventually W_HREADY);
由于 W_HREADY 在 Worker 接口上永远保持 LOW 时也会出现死锁 bug,因此我们认为这个断言是最简单、最通用的检查方法。注:与安全属性相比,有效性属性的概念背后有很多理论依据。这里不需要讨论这个问题与验证有效性断言的正式算法之间的差异,同时也不在本文的讨论范围之内。
拥抱故障
然而通过证明上述断言,我们很快就败下阵来。这促使了我们使用方法和工具的支持。当发现死锁是 "可逃脱的"。换句话说,对失效计数器的抽象(见第 1 部分)使其永远不会达到终值。在这种情况下缓存 "最终 "没有响应,因为它永远停留在无效循环中。这是一个可逃逸的死锁,因为存在一个逃逸事件(计数器达到其终值,失效停止)。
这是一个错误的“故障”,我们最终放弃了这个“故障”,增加了一个 "公平性约束":一个用作约束的有效性属性。
fair_maint: assume property(s_eventually maintenance_module.is_last_index);
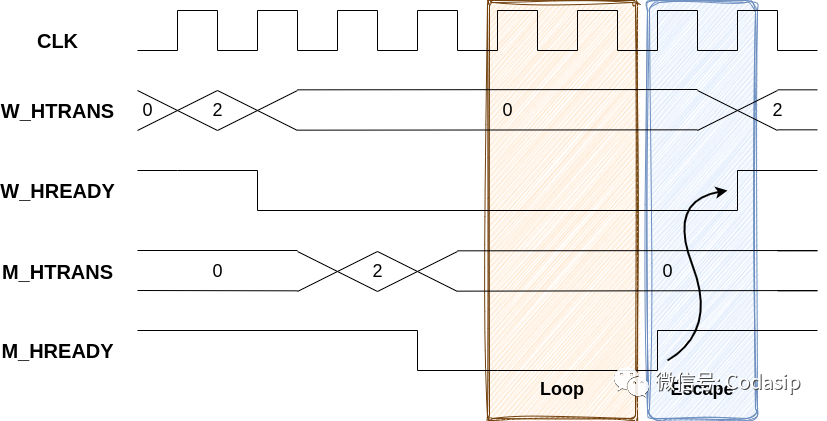
同样,必须将管理器接口上的M_HREADY约束为 "始终最终 "为高。否则,缓存可能会永远处于等待响应的状态。这在下面的波形中可以看到。
在LOOP区域,如果管理器端口上的M_HREADY在请求飞行时也保持LOW,那么Worker端口上的W_HREADY可能会永远保持LOW。这个LOOP区域可以无限大,但 Escape 区域表明,如果环境最终使管理器端口上的M_HREADY升高,那么它就会解除锁定状态,Worker端口上的相同信号也会升高。这就是 "逃逸事件"。
从一种故障到另一种故障
在修复了这些错误的“故障”后,我们又遇到了 resp_ev 断言故障。
结果更有趣:它显示为 "无法逃脱的死锁"。这意味着我们不必再尝试找出其他缺失的公平性约束。有一种状态在于无论之后发生什么,设计都不会响应。
形式化工具显示了一个在LOOP区以无限LOOP结束的波形。由于不存在任何逃逸事件,该区域总是向右无限延伸。
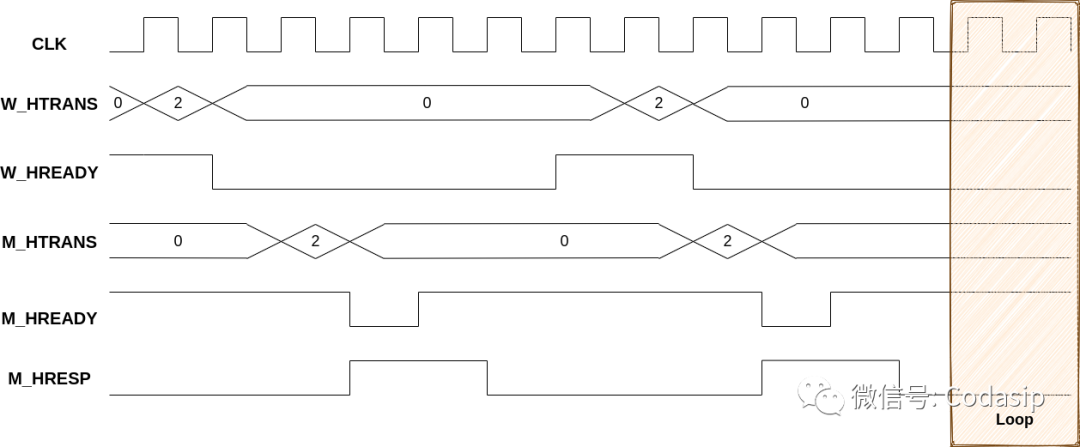
这时设计师们便可以确认 "这就是漏洞!"。最酷的是我们在不到一周的时间里,从零开始重现了这个故障。
验证RTL修复
我们已经有了一个RT 修复方案,所以很快就可以尝试......结果发现它并不完整!我们仍然遇到了无法摆脱的死锁。在经过几次迭代后,情况有所改善,此类的故障也没有再出现......但同时也没有证据可以证明已经彻底摆脱死锁。
增加时间限制后,我们在 iCache 总线上得到了 resp_ev 断言的完整证明(见实践之一)。通过对dCache 总线上的瓶颈分析,发现它是由于标准缓存请求与 CSU 动态更改缓存配置请求的混合功能造成的。这使得状态空间变得非常大。为了避免这种情况,我们对环境进行了限制从而使证明趋于一致。
使用过度约束
在迭代调试过程中,我们使用了过度约束来减少探索。这可以大大减少获得反例或证明所需的时间,并有助于调试故障,因为生成的方案更简单。当然,这些过度约束必须在最终运行时去除。
在正式设置中以简单的方式允许过度约束是很重要的。为了安全起见,最好的做法是禁止在正式测试平台中直接编写约束条件(即假设属性)。这样做的风险太高,可能会在最后留下一些已启用的属性。相反,所有属性都必须写成断言,有些属性可以通过显式运行选项转换成约束。同时Codasip的形式框架允许我们这样做。
其它死锁检测技术
在该系列的第一部分我们已经介绍了形式验证工具如何区分可逃逸和不可逃逸的死锁。然而并非所有工具都能提供这种功能,下面是一种模仿这种功能的技术:
以 s_eventually expr 的形式编写一个有效性断言A。
用工具来证明A。如果被证明就意味着大功告成:没有死锁。
如果出现了反例,就会产生一个以无限循环结束的跟踪T,以防止 expr 再次为真。
运行A、WA的见证证明,使用T来初始化设计,而不是正常的重置序列。形式分析将从LOOP状态开始。
如果证明的结果是WA不可达,则意味着T显示了不可避免的死锁。
如果WA被覆盖,则意味着T是一个可逃逸的死锁,并且WA的跟踪显示了该逃逸事件。
证明有效性断言在计算上比证明安全性断言更困难。因此有时最好采用不同的方法来验证死锁。
使用有界断言
有一种方法是用有界断言代替有效性断言。可以写成 !expr [*N] |=> expr 来代替 s_eventually expr。这意味着expr预计不会在超过N个LOOP的时间内为假。这种特性在仿真测试平台中非常常见。难点在于将N设置得足够大,但又不能太大!如果将N设置为数百或数千个周期,FV就不太可能得到结果。如果将N设得很小,可能会发生一些事件导致N太小,从而导致错误故障。因此在验证有效性断言时,所遇到的困难类似于寻找公平性约束,以摒弃所有可逃逸的死锁。
使用进度计数器
另一种方法是使用进度计数器。首先必须定义一个计数器,每当设计中发生一些事情,例如更接近任务完成时,计数器就会递增。然后安全断言可以检查并在必须取得进展的情况下取得进展。以缓存为例,我们可以将进度计数器定义为在一个管理器端口上发出请求时递增。但一般来说,定义所有必须使计数器递增的事件是很困难的。
进一步验证死锁的方式
在重现了目标错误并验证了建议的 RTL 修正后,我们希望更进一步。我们了解到,只有在使用 "写透 "高速缓存配置时才会出现该错误。因此,在完成上述工作时,我们限制只启用这种配置。当然,我们还想确保在 "回写 "配置中不会出现该问题,因此我们重复了上述过程,取消了这一限制。
然后,我们要验证是否存在其他死锁。这些死锁不会出现在HREADY上,而是出现在设计的内部有限状态机(FSM)上。事实上,死锁可能出现在FSM永远阻塞在某个特定状态时,尽管HREADY并没有像LOW那样被阻塞。为此,我们确定了设计中的主要FSM,并生成了有效性断言,检查所有状态是否最终都能达到。例如
fsm_dcache_miss: assert(s_eventually dcache.fsm_state == MISS);
故障再次出现
我们很快就遇到了许多故障,而且都是可以逃脱的死锁。
例如,如果Worker端口接收到对同一地址的连续请求流。第一个请求可能未命中,也可能命中。但接下来的请求都会命中。如果请求流 "足够密集",那么每次命中之间就不会有等待周期,因此FSM的状态始终是 HIT,无法达到任何其他状态,包括MISS。这就是上述断言失败的原因。
幸运的是,工具显示该失败是由于可逃逸的死锁造成的。逃脱的方法是在请求流中腾出一些空间,或者更改地址。为了掩盖这种情况,我们需要添加公平性约束。但它们似乎限制过多,大大缩小了验证范围。
我们最终决定不这么做。相反,我们让工具在不同的配置下运行了几天(这对正式版来说是很长的时间!)。它报告了许多我们忽略的可逃脱死锁,但没有发现无法逃脱的死锁,至此,这些收获即使没有得到完整的证明,但也大大增强了我们的信心。
在本次的死锁漏洞调查案中,我们探讨了验证死锁的形式化最佳实践。以下是三个主要收获:

在本次的死锁漏洞调查案中,我们探讨了验证死锁的形式化最佳实践。以下是三个主要收获。
通过故障重现和RTL修复验证,大大提高了我们对形式化验证的信心,相信并没有其他真正的死锁存在。当然Codasip并没有就此止步,作为专业的bug猎人,在下一集中,将为大家介绍Codasip如何验证设计的其他方面,包括高级属性等。敬请期待!
审核编辑:彭菁
-
安装完AIC3256EVM-U_CS_v1_2_1 软件后,发现没有固件应该如何处理?2024-10-10 358
-
如何处理MOS管小电流发热?2023-12-07 1675
-
什么是串扰?该如何处理它?2023-12-05 2091
-
Linux内核死锁lockdep功能2023-09-27 1824
-
如何处理轴表面磨损造成的伤害2022-02-15 928
-
如何处理化料机轴表面磨损2022-01-17 841
-
串口使用中断模式发现程序有时候会进去死锁状态2021-08-13 1138
-
腾讯发现特斯拉Autopilot漏洞2019-04-19 1319
-
用modelsim进行仿真时,编写testbench,inout信号应该如何处理2019-03-20 4436
-
saber仿真软件波形如何处理分析、saber仿真软件如何画电路图2017-12-08 27946
-
基于主要特征抽取的重现概念漂移处理算法2017-01-07 725
-
Linux发现更多安全漏洞LHA 与imlib受到波及2009-06-12 762
-
linux处理机调度与死锁2009-04-28 695
-
DIN中的死锁避免和死锁恢复2009-02-23 1309
全部0条评论

快来发表一下你的评论吧 !
