

如何适配新架构?TPU-MLIR代码生成CodeGen全解析!
描述
背景介绍
TPU-MLIR的CodeGen是BModel生成的最后一步,该过程目的是将MLIR文件转换成最终的Bmodel。本文介绍了CodeGen的基本原理和流程,并记录了针对BM1684X等新架构的CodeGen重构过程。
与后端的关系
由于一些历史的因素,MLIR文件中的每个OP对应的指令并不直接在TPU-MLIR工程中生成,而是需要调用后端的函数完成最终指令的生成,这也带来了两个问题
- 如何设计编译器与后端的接口
- 生成指令的数据结构存在后端还是编译器中
关于问题1,目前的设计是采用CodeGen与后端隔离的形式,也就是CodeGen过程不直接调用后端函数,而是将不同处理器的相应函数全部封装到类中,在CodeGen中调用类方法间接使用后端接口,达成解耦。
而关于问题2,依据不同的处理器其数据结构位置也不同,1684的数据结构放在编译器这边,而BM1684X等新架构的处理器数据结构放在后端。无论放在哪里,其全部封装于问题1答案中的相应类中,对于CodeGen过程来说,看到的接口是一样的。
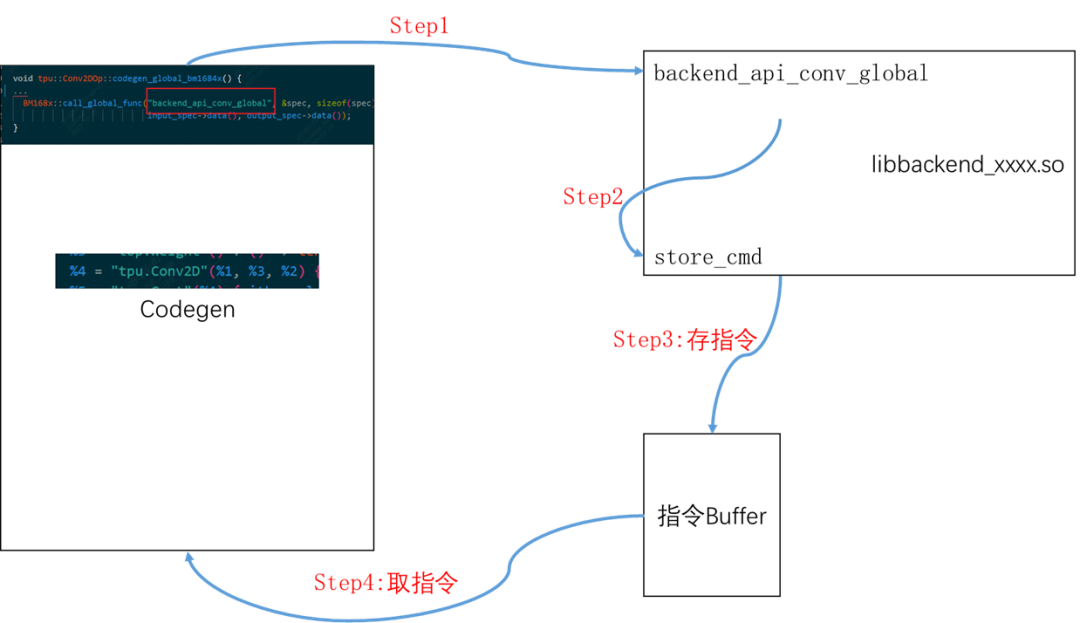
一个OP生成指令的大致流程
代码位置:lib/Dialect/Tpu/Transforms/Codegen/BM168xCodegen.cpp
该流程忽略CodeGen代码内部细节,这里只讲解类似于把大象装冰箱主要分几步这样的通俗介绍。
- 在BM168XCodegen.cpp会遇到某个Op时会调用该op的codegen_local_bm168x/codegen_global_bm168x,算子的这个函数都在lib/Dialect/Tpu/Interfaces/中
- 在具体OP中会设置一些参数,然后调用到后端的具体op的指令生成,比如Conv2d算子会调用后端函数backend_api_conv_global
- (后端过程)直接做一系列检查后,会直接生成指令(二进制码),这些二进制码会通过store_cmd存储在指定数据结构中,
- 等所有op的二进制码全部都生成完毕后,在编译器会调用BM1684X系列类中封装的函数取走指令,生成Bmodel
做个形象点的例子:
原来 装冰箱只需要我,现在我嫌大象沉,我叫个张三帮我装。
我:张三,你把这个大象给我装冰箱里
张三吭哧吭哧帮我装完了
我:行了,张三,你走吧;我自己把装的运走。
指令生成所需要的数据结构
指令依据处理器的engine不同而有所差别,比如1684有GDMA和TIU,而新架构的处理器SG2260会存在sdma、cdma等engine。这里拿最通用的两种engine即BDC(后更名为TIU)和GDMA为例:
std::vector<uint32_t> bdc_buffer;
std::vector<uint32_t> gdma_buffer;
uint32_t gdma_total_id = 0;
uint32_t bdc_total_id = 0;
std::vector<uint32_t> gdma_group_id;
std::vector<uint32_t> bdc_group_id;
std::vector<uint32_t> gdma_bytes;
std::vector<uint32_t> bdc_bytes;
int cmdid_groupnum = 0;
CMD_ID_NODE *cmdid_node;
CMD_ID_NODE *bdc_node;
CMD_ID_NODE *gdma_node;
- bdc_buffer和gdma_buffer:放指令
- gdma_total_id和bdc_total_id:存指令总数目,因为指令不一定是32位的,因此使用buffer的长度不能获取到指令的总数目
- gdma_group_id和bdc_group_id:每个group中的指令数,这个group是什么意思待调查清楚,后端对其进行控制时代码如下所示
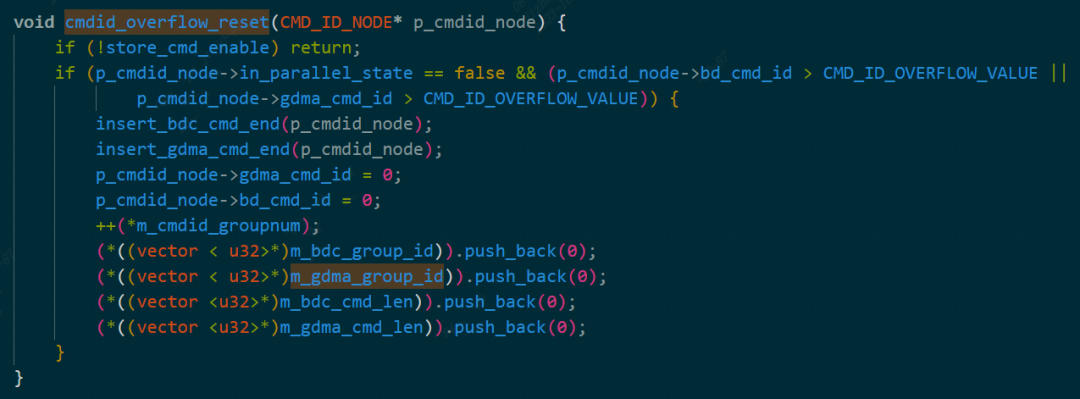
cmdid_overflow
- cmdid_groupnum:group的数量
- gdma_bytes和bdc_bytes:内部是每个group中指令的字节(Bytes)数
- cmdid_node、bdc_node和gdma_node:这个node是为了并行生成GroupOp内部所需要指令而形成指的,具体机制还有待研究
TPU-MLIR中layer group和上述行为中group的概念区分
TPU-MLIR中的layer group是指可以存放在Lmem的一系列算子,组成一个Group Op。
而上述的group,指的是指令组。这个指令组存在的意义是防止内存不够用,比方说1684只有16位寻址空间,那么大于这个数字的指令无法一次性全部搬运到内存,所以当指令超出某个数时候,就会重新建一个组。
TPU-MLIR中BM168X及其相关类
这边的相关类tpu-mlir/include/tpu_mlir/Backend该文件夹下定义的类,目的就是将不同的处理器后端封装,从而实现后端于Codegen过程的隔离。
其继承关系为:
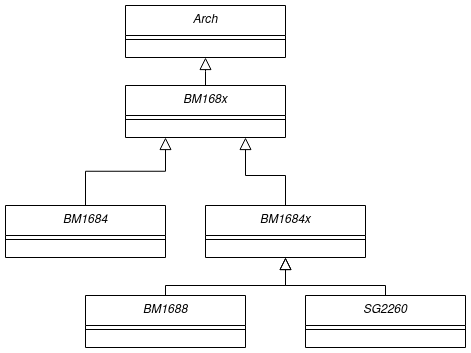
在一次运行中只存在一个类(设计模式中单例),该类初始化时候会经过:读取后端动态链接库、加载函数(设置后端的函数指针)、指令数据结构的初始化、设置一些处理器相关的参数例如NPU_NUM、L2_SRAM起始地址等。
后端函数的加载
后端作为一个动态库放入了TPU-MLIR工程里,具体在third_party/nntoolchain/lib/libbackend_xxx.so。在我们要使用backend时候,先在需要函数的类中定义好函数指针,然后再将动态库加载后,使函数指针指向动态库中真正的函数。
以同步函数tpu_sync_all为例,由于之后要加上多核支持的,所以需要在相关后端Bmodel库中定义好,
- 注意必须和后端的函数名和参数保持一致typedef void (*tpu_sync_all)();
- 在类内部加入该函数成员tpu_sync_all, dl_tpu_sync_all;
- 有成员后,在该类load_functions函数的实现中加入宏,CAST_FUNCTION(tpu_sync_all);该宏可以将dl_tpu_sync_all指向动态库中真正的函数
这时候在我们获得到该类实例后即可使用动态库中的函数了。
后端store_cmd设计
后端的store_cmd功能是指编译器调用算子的过程中,把配置的指令保存到约定空间的过程。(以下是后端代码,以后会选择性开放)。后端的重点函数在store_cmd.cpp中,以cmodel/src/store_cmd.cpp;cmodel/include/store_cmd.h为例
注:store_cmd类设计的非常复杂,参杂各种设计模式在里面,只大概梳理一下类之间关系
store_cmd分别有EngineStorer系列类和CmdStorer系列类:
- EngineStoreInterface(接口类)、继承于EngineStoreInterface接口的GDMAEngineStorer、BDEngineStorer等具体类、EngineStorerDecorator(装饰类接口)、继承于EngineStorerDecorator的VectorDumpEngineStorerDecorator等具体装饰类
- CmdStorerInterface(接口)、继承于接口的ConcretCmdStorer、StorerDecorator:装饰接口、VectorDumpStorerDecorator具体装饰类。
关于类之间的关系与逻辑
- 使用单例设计模式,在store_cmd中只存在一个ConcretCmdStorer类,该类中会存所有EngineStorer的类,当调用不同的engine时,会调用不同EengineStorer,如下代码
virtual void store_cmd(int engine_id, void *cmd, CMD_ID_NODE *cur_id_node,
int port) override
{
switch (engine_id)
{
case ENGINE_BD:
case ENGINE_GDMA:
case ENGINE_HAU:
case ENGINE_SDMA:
port = 0;
break;
case ENGINE_CDMA:
ASSERT(port < CDMA_NUM);
break;
case ENGINE_VSDMA:
engine_id = ENGINE_SDMA;
break;
default:
ASSERT(0);
break;
}
return this->get(engine_id, port)->store(cmd, cur_id_node);
}
- Cmd装饰类的作用是将所有的EngineStorer套上其装饰器的壳子(目的实现其他功能),以VectorDumpStorerDecorator为例,会使用宏为每个EngineStorer、套上VectorDumpEngineStorerDecorator的壳子。
void decorate_engines()
{
#define DECOR_STORER(name, idx) \
if (outputs_[ENGINE_##name][idx]) \
{ \
auto name##_str = std::make_shared( \
StorerDecorator::get(ENGINE_##name, idx), \
&(outputs_[ENGINE_##name][idx])); \
StorerDecorator::get(ENGINE_##name, idx) = name##_str; \
engine_decorators_.push_back(name##_str); \
}
DECOR_STORER(BD, 0)
DECOR_STORER(GDMA, 0)
DECOR_STORER(HAU, 0)
DECOR_STORER(SDMA, 0)
for (int i = 0; i < CDMA_NUM; i++)
{
DECOR_STORER(CDMA, i)
}
#undef DECOR_STORER
}
每个具体的EngineStorer,注意其功能并非把命令存下来,他只干解析命令,比方说拿到一条320位的命令(瞎说的),EngineStorer会将其解析成长度为10的32位数组(std::vector)。
真正存命令是使用VectorDumpEngineStorerDecorator,装饰器的作用是:执行被装饰类的特定函数时,进行更多的操作,具体可以《设计模式》的书。这点对于理解store_cmd非常重要,作者在设计store_cmd时,使用了很多装饰器、为每个EngineStorer赋予了额外的功能,其中把指令储存也看作一个装饰器。VectorDumpEngineStorerDecorator该装饰器执行EngineStorer类中的store函数后,会追加执行take_cmds函数,该函数将所有指令存储到output_中。
class VectorDumpEngineStorerDecorator : public EngineStorerDecorator
{
private:
std::vector<uint32_t> *&output_;
void take_cmds()
{
auto cmds = EngineStorerDecorator::get_cmds();
(*output_).insert((*output_).end(), cmds.begin(), cmds.end());
}
public:
VectorDumpEngineStorerDecorator(ComponentPtr component,
std::vector<uint32_t> **output)
: EngineStorerDecorator(component), output_(*output) {}
virtual void store(void *cmd, CMD_ID_NODE *cur_id_node) override
{
EngineStorerDecorator::store(cmd, cur_id_node);
if (!enabled_)
return;
this->take_cmds();
}
virtual void store_cmd_end(unsigned dep) override
{
EngineStorerDecorator::store_cmd_end(dep);
this->take_cmds();
}
};
store_cmd中类与暴露给编译器接口的关系
实际上上述的各种类不能直接暴露给编译器,因为必须传的是c函数的函数接口,因此必须将类中各种函数封装进c语言函数形式,以store_cmd为例,get_storer会获得唯一的ConcretCmdStorer类
void store_cmd(void *cmd, int engine_id, CMD_ID_NODE *cur_id_node, int port,
int thread_id)
{
get_storer()->store_cmd(engine_id, cmd, cur_id_node, port);
}
TPU-MLIR中的重构修改
分为三部分:BM168X及派生类、BM168XCodeGen
对于BM168X派生类来说,后端工程中添加了很多新的函数,这些函数主要是将存指令的数据结构放入了后端管理,涉及的后端有1684X之后架构的处理器,而1684并不适配新的函数。这意味着:
存储指令的数据结构需要发生改变,许多数据结构已经不需要。如下图所示:

需要添加新的接口函数,即使获取指令的方式不同,但是在Codegen过程看到的应该是一样的行为。

这里传入的参数是const char*是为了简化参数定义,可以用特定格式字符串来指定后端engine。如gdma1,这里gdma表示GDMA Engine, 0表示第0个GDMA Engine(一个TPU内可能有多个相同的engine), 1表示第0号GDMA Engine的第1个线程(每个Engine可能支持多线程)。
对于BM168XCodegen,之前是需要在上面的Code结构体获取相关的数据,而修改后须使用新接口,
修改前:auto gdma_ptr = (uint8_t *)(*bm168x)->gdma_buffer.data();修改后:auto gdma_ptr = (uint8_t *)(*bm168x).get_inst_data("gdma0");
并且对于后续架构处理器的指令生成来说,目前需要存储sdma和hau的指令,所以相关指令也需要添加入Bmodel。如下图所示(这里主要用到了FlatBuffer操作):
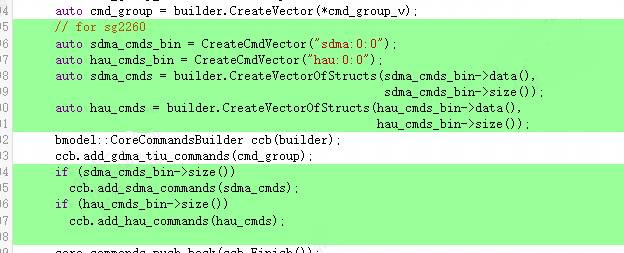
codegen_save
总结
从中可以看出,TPU-MLIR虽然能够满足当前TPU上的基本需求,但随着应用场景的扩展和TPU架构的不断演进,其需要满足很多新的要求。这就需要开发者不断思考和挖掘新的接口和架构,使其具有一定的扩展性和适应性。欢迎并感谢各位有识之士为TPU-MLIR多提建议,贡献代码!
-
TPU-MLIR开发环境配置时出现的各种问题求解2024-01-10 1190
-
深入学习和掌握TPU硬件架构有困难?TDB助力你快速上手!2023-12-22 2653
-
TPU-MLIR量化敏感层分析,提升模型推理精度2023-10-10 3147
-
在“model_transform.py”添加参数“--resize_dims 640,640”是否表示tpu会自动resize的?2023-09-18 565
-
如何使用TPU-MLIR进行模型转换2023-08-21 1776
-
TPU-MLIR中的融合处理2023-08-18 1392
-
如何设计MLIR的Dialect来在GPU上生成高性能的代码?2023-05-10 3618
-
TVM学习(四)codegen2021-01-27 882
全部0条评论

快来发表一下你的评论吧 !
