

cnocr和tesseract的使用方法和效果
描述
今天尝试了一下cnocr和tesseract,给大家分别讲讲两个模块的使用方法和效果。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上噢,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),准备开始输入命令安装依赖。
当然,我更推荐大家用VSCode编辑器,把本文代码Copy下来,在编辑器下方的终端运行命令安装依赖模块,多舒服的一件事啊:Python 编程的最好搭档—VSCode 详细指南。
在终端输入以下命令安装我们所需要的依赖模块:
pip install cnocr
看到 Successfully installed xxx 则说明安装成功。
如果你只想使用cnocr,那么只需要安装上述的cnocr包即可。如果你想试试其他语言的OCR识别,Tesseract 是更好的选择。
首先,无论是Windows还是macOS,你都需要安装 pytesseract:
pip install pytesseract
其次,还需要安装Tesseract. Tesseract 在macOS下可以使用brew安装:
brew install tesseract
Windows下安装tesseract则相对复杂。
需要先下载安装tesseract的程序,然后下载中文简体字预训练好的模型包(尽管本教程不会用tesseract,但还是给大家提供了)。
你可以在Python实用宝典公众号后台回复:**tesseract **打包下载。
下载完成后,将tesseract-ocr-setup-4.00.00dev.exe安装到Tesseract-OCR指定目录下,复制该目录路径增加到Path中:
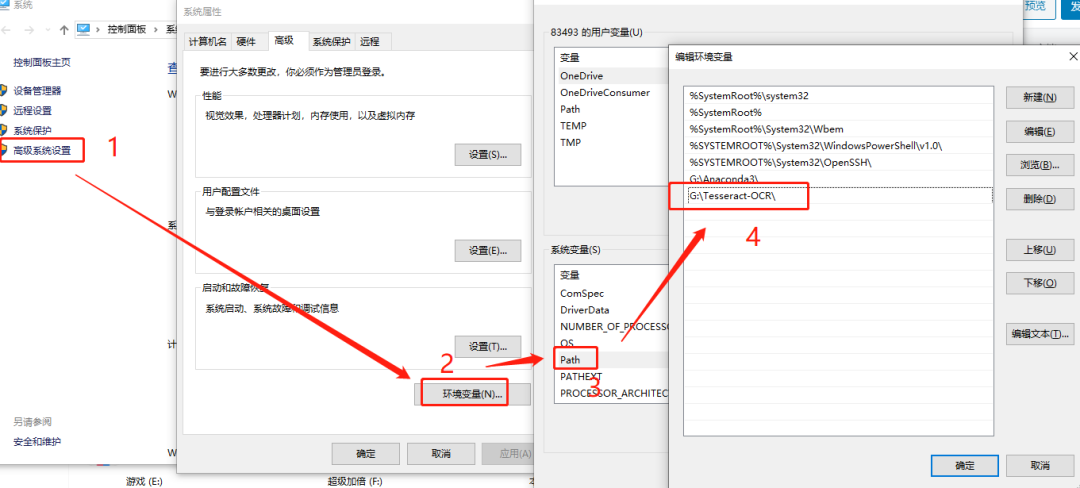
并将训练好的模型文件chi_sim.traineddata放入该目录中,这样安装就完成了。
2.cnocr 识别图片的中文
cnocr 主要针对的是排版简单的印刷体文字图片,如截图图片,扫描件等。目前内置的文字检测和分行模块无法处理复杂的文字排版定位。
尽管它分别提供了单行识别函数和多行识别函数,但在本人实测下,单行识别函数的效果非常糟糕,或者说要求的条件十分苛刻,基本上连截图的文字都识别不出来。
不过多行识别函数还不错,使用该函数识别的代码如下:
from cnocr import CnOcr
ocr = CnOcr()
res = ocr.ocr('test.png')
print("Predicted Chars:", res)
图片版代码:

用于识别这个图片里的文字:
效果如下:

如果不是很吹毛求疵,这样的效果已经很不错了。
3.pytesseract 识别图片的英文
如果你的OCR目的不是中文而是英文,是需要别的模型的。这里给大家分享Tesseract-OCR,它是一款由HP实验室开发,由Google维护的开源OCR引擎。
Tesseract-OCR 可扩展性很强,你可以基于它训练属于自己的OCR模型。
现在给大家看看它分类英文的效果,代码如下:
import pytesseract
from PIL import Image
image = Image.open('test2.png')
code = pytesseract.image_to_string(image, lang='eng')
print(code)
图片版代码:

识别的图片:
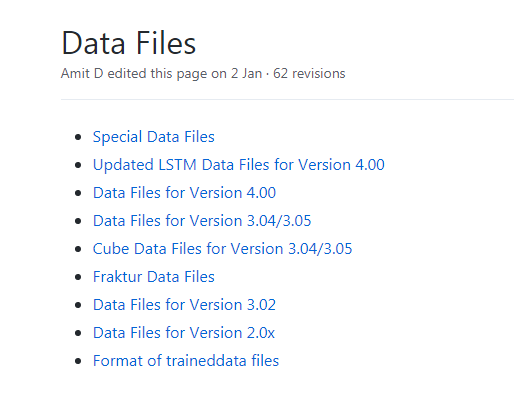
效果如下:
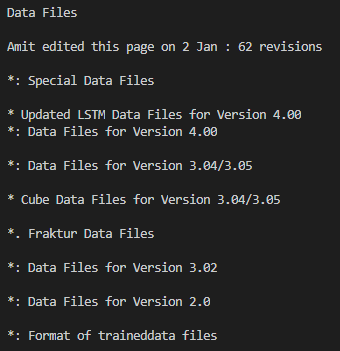
英文效果真的很不错,不过官方预训练好的中文模型效果就比较一般了。
如果你想试试Tesseract识别中文,只需要将代码中的eng改为chi_sim即可,不过相信我,效果不忍直视。
-
锡膏的储存及使用方法详解2025-07-18 1823
-
关于两个Python开源识别工具的效果2023-10-17 1828
-
示波器的使用方法(三):示波器的使用方法详解2020-12-24 4800
-
linux的tesseract-ocr安装2019-07-15 2631
-
git使用方法2017-10-24 1128
-
xilinx原语使用方法2017-10-19 1379
-
CC debuger的使用方法2017-10-18 1356
-
xilinx 原语使用方法2017-10-17 1391
-
AT指令使用方法2017-07-21 1639
-
基于zed的tesseract移植过程记录2017-02-10 1782
-
Matlab使用方法和程序设计2008-10-17 5871
-
示波器的使用方法2008-01-14 19026
全部0条评论

快来发表一下你的评论吧 !
