

Tablib:一个Python的第三方数据导出模块
描述
Tablib是一个Python的第三方数据导出模块,它支持以下文件格式的导出:
- Excel
- JSON
- YAML
- Pandas DataFrames
- HTML
- Jira
- TSV
- ODS
- CSV
- DBF
其实这个工具能做到的东西,Pandas都能做到,但是有时候Pandas实在是过重了,如果我们只想实现轻量数据的导出,而非上千万级别的数据导出,该工具更能体现它的优势。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上噢,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),准备开始输入命令安装依赖。
当然,我更推荐大家用VSCode编辑器,把本文代码Copy下来,在编辑器下方的终端装依赖模块,多舒服的一件事啊:Python 编程的最好搭档—VSCode 详细指南。
在终端输入以下命令安装我们所需要的依赖模块:
pip install tablib
看到 Successfully installed xxx 则说明安装成功。
2.基本使用
这一块,官方文档已经有详细介绍,这里转载自xin053的翻译与介绍,有部分修改:
https://xin053.github.io/2016/07/10/tablib%E5%BA%93%E4%BD%BF%E7%94%A8%E8%AF%A6%E8%A7%A3/
创建Dataset对象

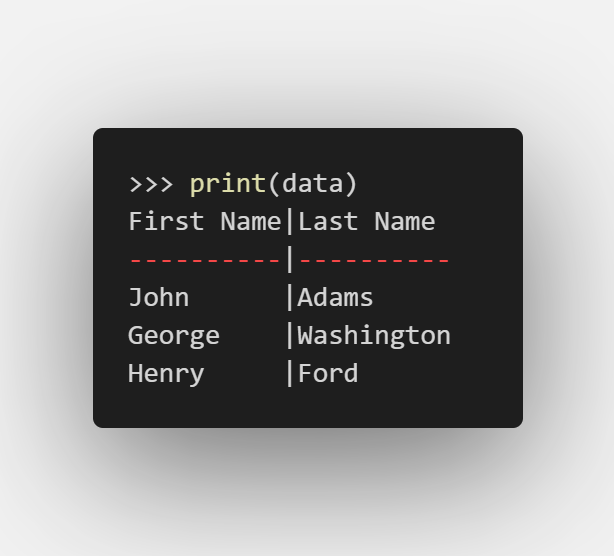
这样相当于构造了一张表:
| first_name | last_name |
|---|---|
| John | Adams |
| George | Washington |
其中最重要的就是Dataset对象,当然该对象的创建也可以不输入参数,直接
data = tablib.Dataset()
创建出一个Dataset对象,然后通过
data.headers = ['first_name', 'last_name']
设置表头,当然也可以使用 data.headers = ('first_name', 'last_name'), 因为不管是用列表还是元组,tablib都会自动帮我们处理好,我们可以通过
data.append(['Henry', 'Ford'])
# 或data.append(('Henry', 'Ford'))
来向表中添加一条记录。
我们可以通过data.dict来查看目前表中的所有数据:

也可以通过print(data)显示更人性化的输出:
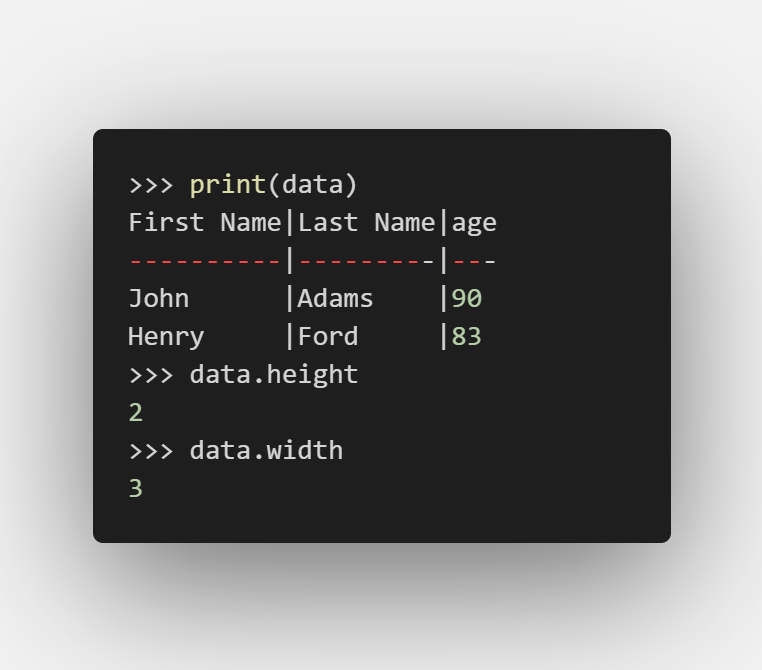
Dataset属性
data.height输出当前记录(行)总数
data.width输出当前属性(列)总数
常用方法
详情可见官方文档:
https://tablib.readthedocs.io/en/stable/api/#tablib.Dataset.remove_duplicates
lpop(), lpush(row, tags=[]), lpush_col(col, header=None)是对列的相关操作
pop(), rpop(), rpush(row, tags=[]), rpush_col(col, header=None)是对行的相关操作
remove_duplicates()去除重复的记录
sort(col, reverse=False)根据列进行排序
subset(rows=None, cols=None)返回子Dataset
wipe()清空Dataset,包括表头和内容
新增列
data.append_col((90, 67, 83), header='age')
这样表就变成了:
| first_name | last_name | age |
|---|---|---|
| John | Adams | 90 |
| George | Washington | 67 |
| Henry | Ford | 83 |
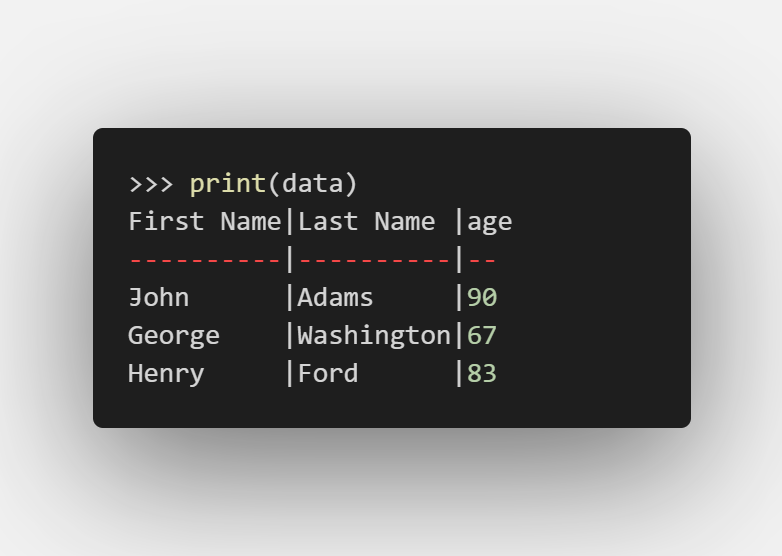
对记录操作
> > > print(data[:2])
[('John', 'Adams', 90), ('George', 'Washington', 67)]
> > > print(data[2:])
[('Henry', 'Ford', 83)]
对属性操作
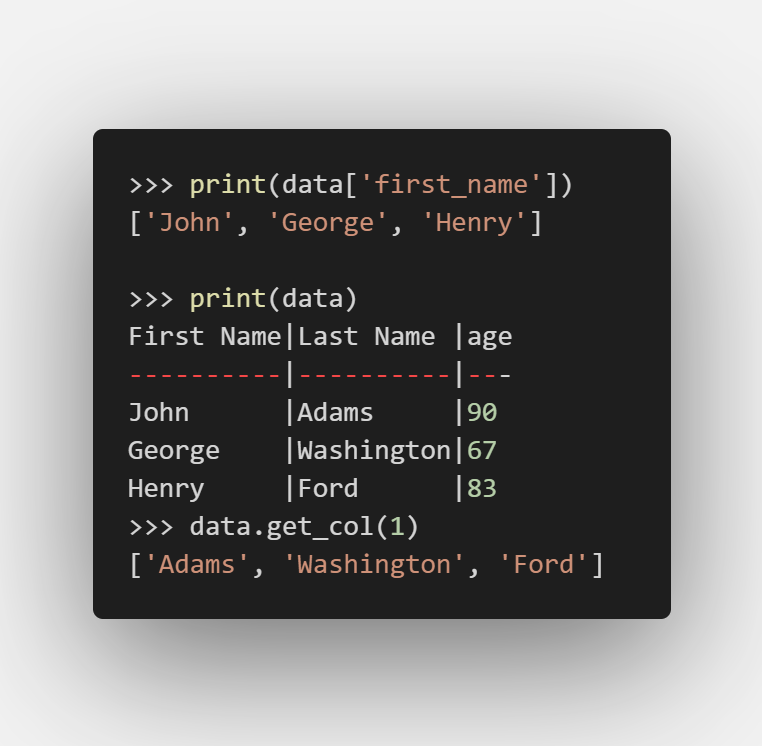
删除记录
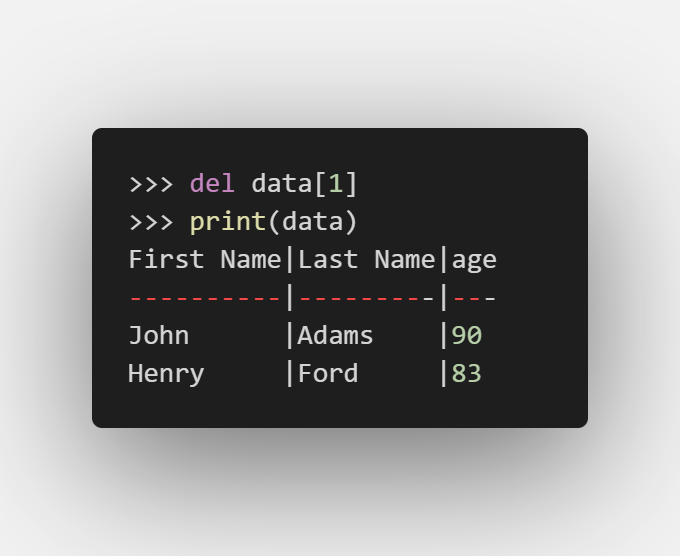
可见记录也是从0开始索引的
删除记录操作也支持切片, 即 del data[1:999] 也是可行的
删除属性
del data['Col Name']
导入数据
imported_data = tablib.Dataset().load(open('data.csv').read())
导出数据
csv:
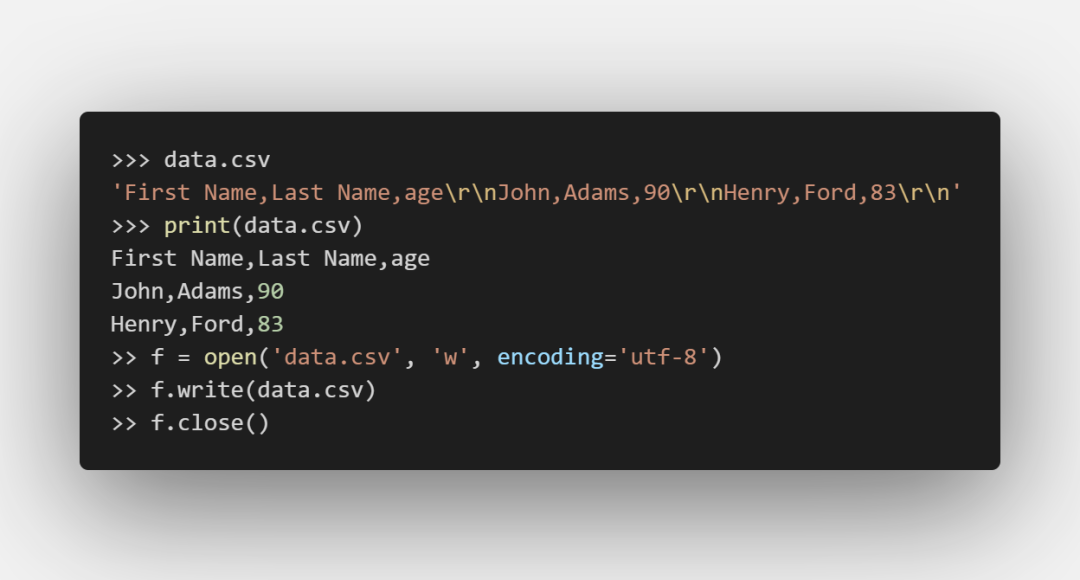
这样便可成功将数据导出为csv文件。
json:
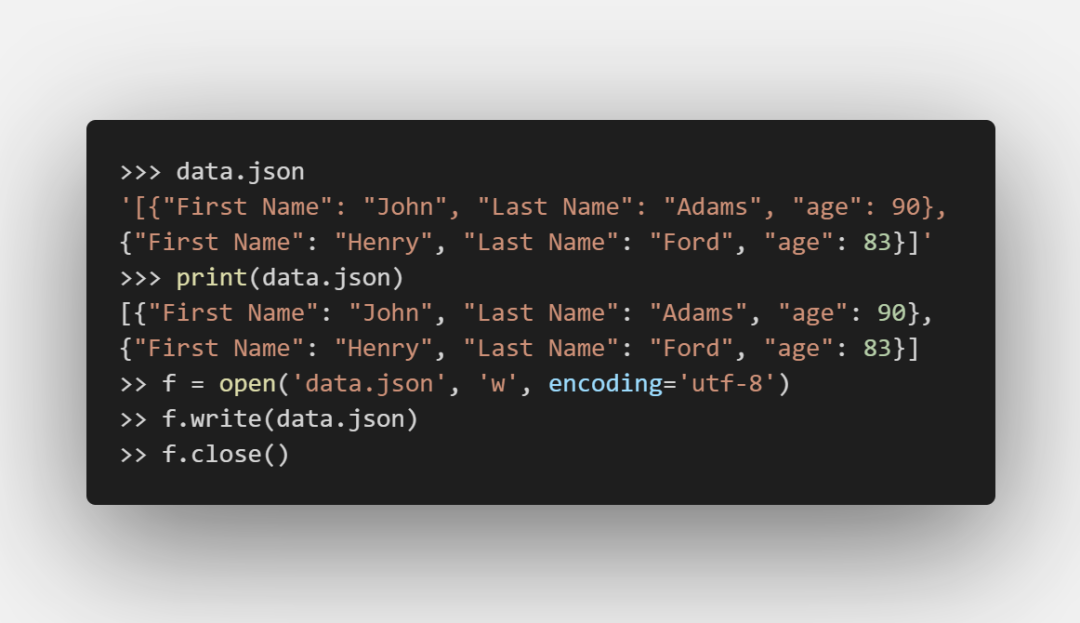
yaml:
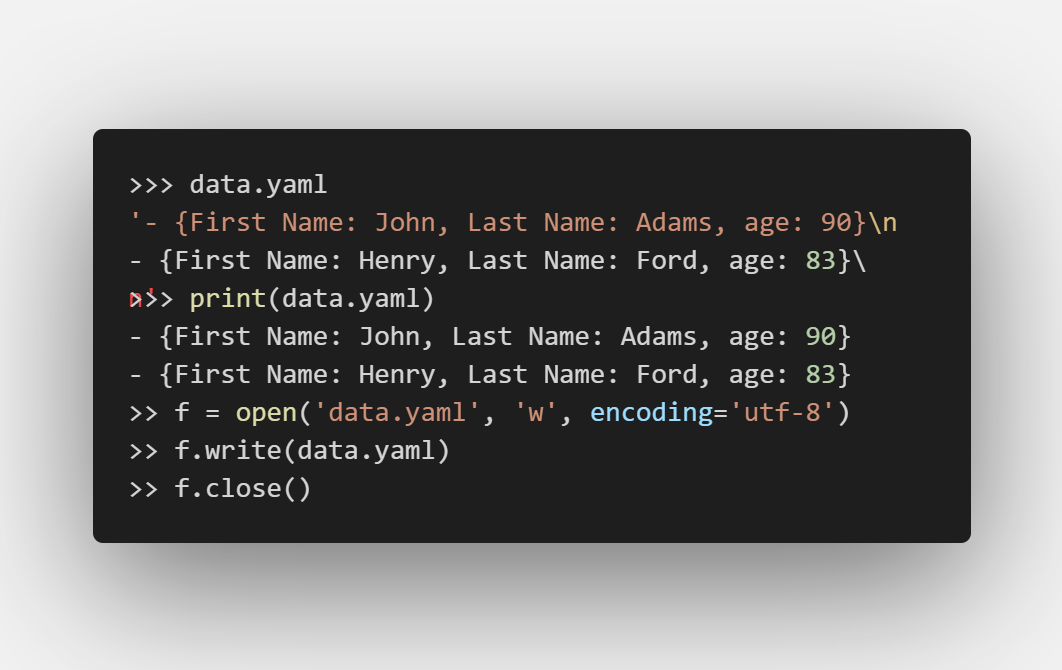
excel:
> > > with open('people.xls', 'wb') as f:
... f.write(data.xls)
注意要以二进制形式打开文件
dbf:
> > > with open('people.dbf', 'wb') as f:
... f.write(data.dbf)
高级使用
动态列
可以将一个函数指定给Dataset对象
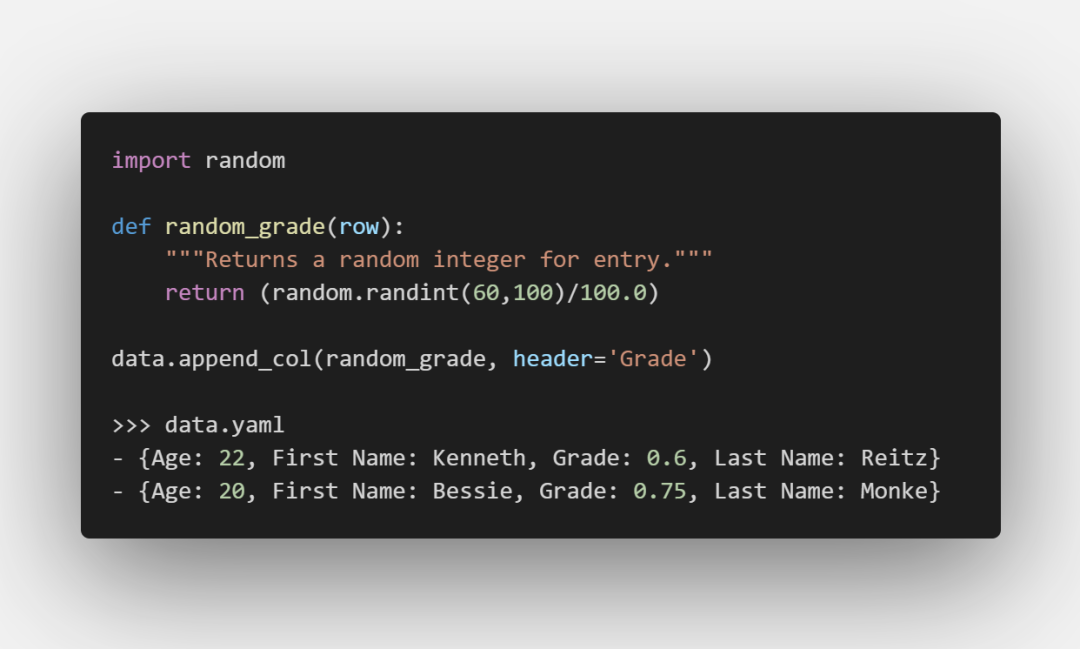
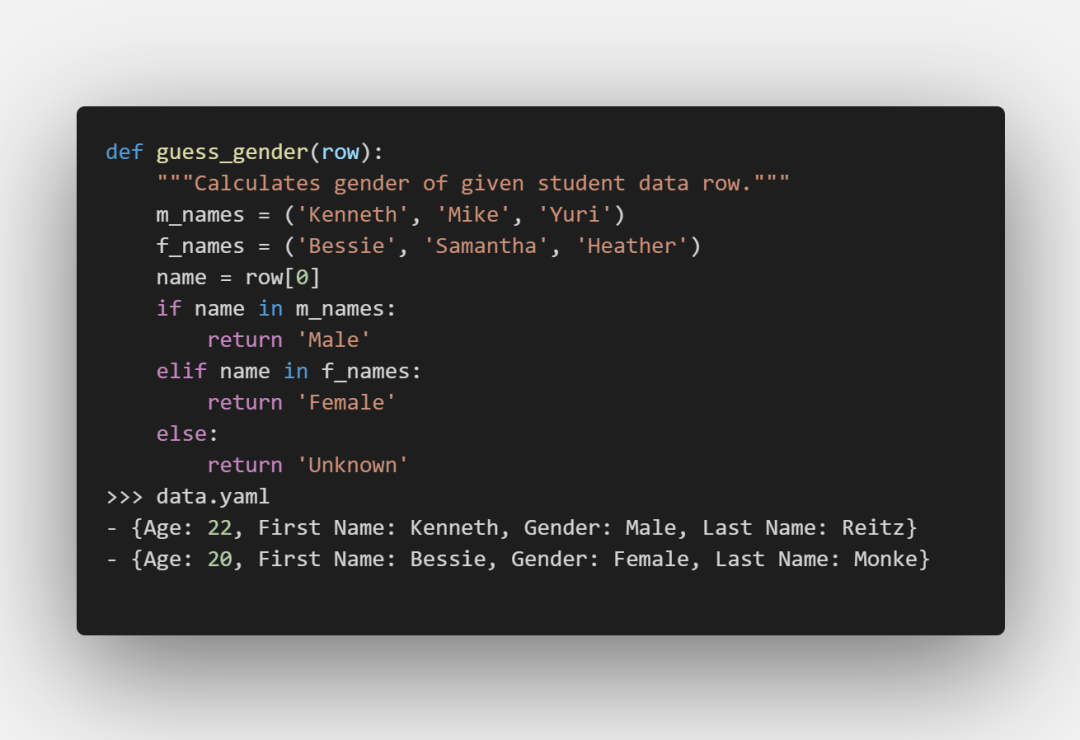
函数的参数row传入的是每一行记录,所以可以根据传入的记录进行更一步的计算:
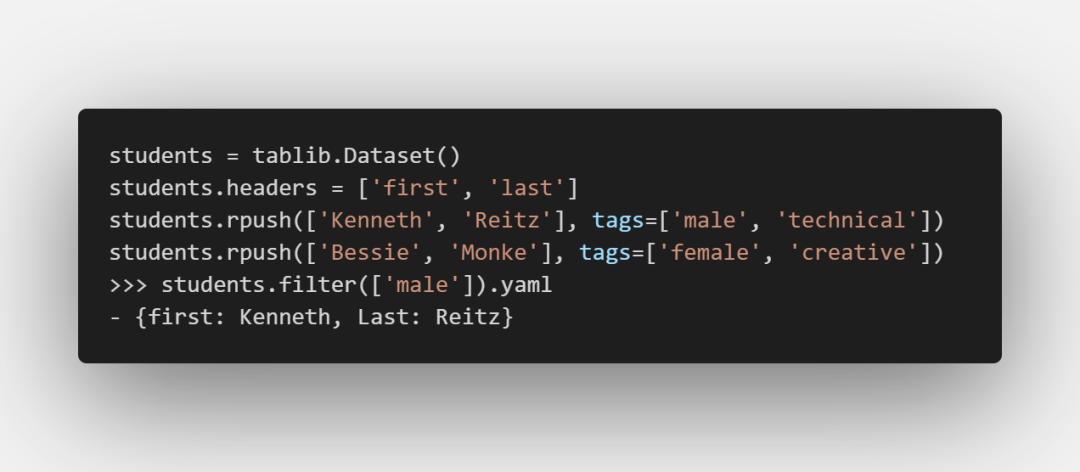
tag
可以给记录添加tag,之后通过tag来过滤记录:
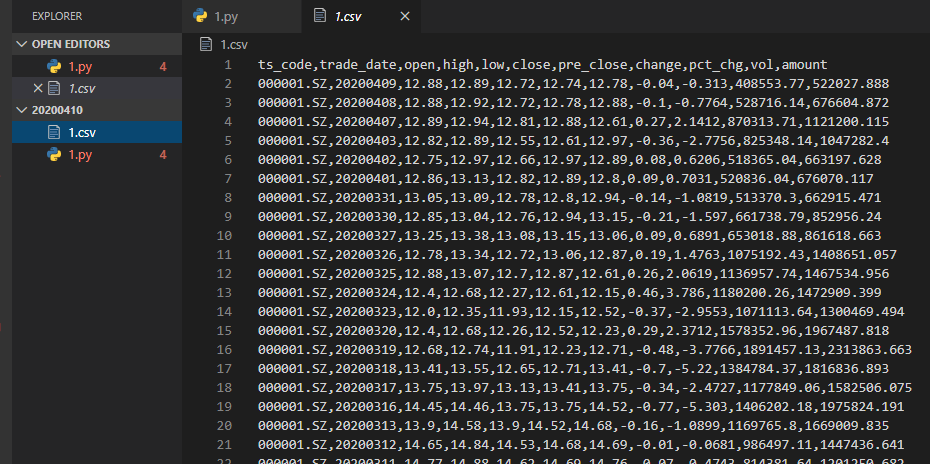
3.举个小例子
现在有一个场景,我们需要将一份股票数据csv文件转化为json数据:
你只需要这样操作:
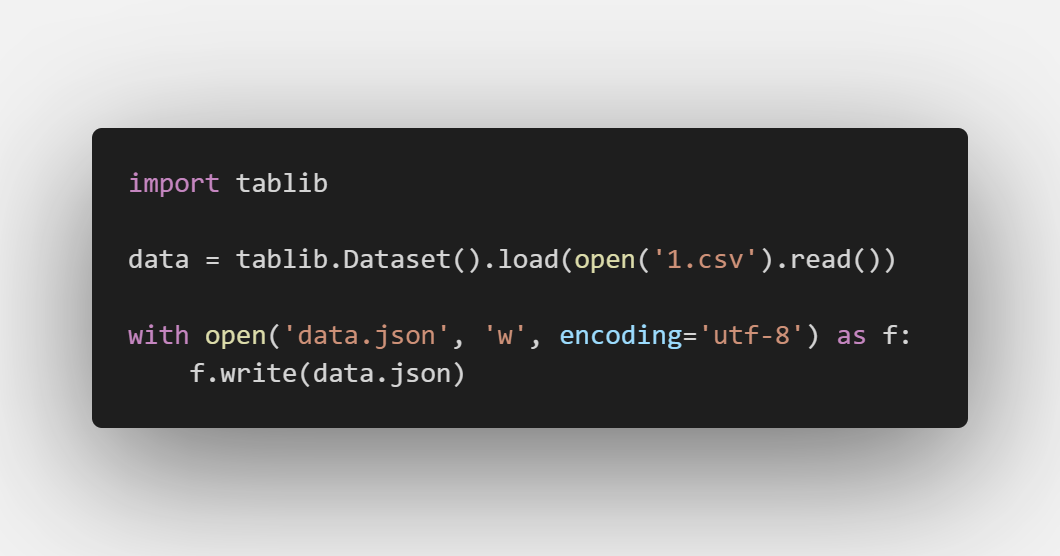
即可将其转化为json格式,显然,它的特点在于轻量、简单。如果用Pandas来做这样的转化,则有些大材小用。
-
Labview如何内嵌操作第三方EXE程序!2024-04-18 19169
-
python第三方库有哪些2023-11-29 3369
-
GeoPandas:针对地理数据做了特别支持的第三方模块2023-10-21 2026
-
头文件中包含第三方文件2021-08-18 1476
-
第三方脚本成为网络攻击“重灾区”,多管齐下防范第三方脚本安全隐患2020-09-04 4728
-
关于LabVIEW调用第三方exe,如何去控制第三方exe按钮的问题2020-08-12 12866
-
Python入门之36常用第三方模块获取系统信息psutil2020-07-16 1704
-
Detectron训练第三方数据集测试2020-04-14 2261
-
国内知名第三方检测认证机构排名2019-07-19 7478
-
下载python第三方库2019-07-02 2093
-
LabVIEW与第三方软件交互问题2018-12-26 13134
-
第三方dll调用问题!!!2018-05-11 4738
-
如何把第三方库加到PROTEUS中?2013-06-15 3373
-
银行和第三方支付:恋爱进行时2010-01-09 955
全部0条评论

快来发表一下你的评论吧 !
