

基于机器学习的应用系统指纹识别技术研究
描述
来源:信息安全与通讯保密杂志社
作者:贺彦钧 , 朱磊 , 黄炜
摘要: 在信息安全测试领域,基于机器学习的应用系统深度指纹识别技术对应用系统进行漏洞检测时,可快速获取应用系统指纹信息,并且能够根据系统深度指纹信息进行精确的自适应漏洞检测。通过研究面向 http 协议的信息收集爬虫技术、基于字符串匹配的识别技术和目标安全缺陷利用技术,基于目标指纹特征提出并搭建了朴素贝叶斯模型,实现了基于机器学习的应用系统指纹识别技术,识别目标应用系统信息,发现缺陷和自适应漏洞检测。最后对相关技术的实现进行实验验证,实验结果符合预期。
随着互联网的迅速发展和智能化应用的普及,对数据的隐私保护和安全性的要求越来越高。在网络安全领域,指纹识别技术被广泛用来识别和验证用户的身份,以保护敏感信息和资源的安全。传统的指纹识别技术主要集中在人体指纹的识别上,但随着技术的进步和应用场景的改变,深度指纹识别技术逐渐引起了研究者和工程师的关注。深度指纹识别技术是一种基于机器学习的指纹识别方法,通过训练模型和学习特征来实现更准确和可靠的指纹识别。与传统的指纹识别技术相比,深度指纹识别技术具有更高的灵活性和扩展性。它能够识别各种类型的指纹,包括人体指纹、网络活动指纹、行为指纹等,以满足不同领域的应用需求。深度指纹识别技术是通过深度学习模型来提取和学习指纹数据的特征,从而实现指纹的分类和识别,并通过分析指纹的局部特征和上下文信息,达到更高的识别准确率和鲁棒性。
因此,本文面向信息安全测试领域,在应用系统进行漏洞检测时,针对如何快速获取应用系统指纹信息,如何根据应用系统指纹信息进行自适应漏洞检测等问题,提出了“基于机器学习的深度指纹识别技术及应用”思路,帮助测试人员快速准确找到应用系统漏洞,及时通知系统开发人员进行整改修复,做好网络安全防护工作,进一步保障系统安全稳定运行。
1研究思路
1.1 概 述
目前针对 Web 服务器指纹识别的主流研究主要通过分析大量 HTML 数据,包括 HTML 源码关键字和特殊文件及路径,来识别 Web 组件,探测以下几个请求和返回信息进行 Web 应用指纹判断:网站响应头部信息(Response header)、HTML页面内 META 标签信息、HTML 内脚本语言信息(JavaScript,JS)、 层 叠 样 式 表(Cascading StyleSheets,CSS)等引用链接信息、特殊统一资源定位(Uniform Resource Locator,URL)地址及参数、特定文件名、文件内容及文件的数字摘要(Hash 值)。
主流的 Web 指纹识别技术是基于特征匹配实现的,包括特殊静态文件 Hash 值和关键字段两类特征。特殊静态文件可以是 js、css 文件,也可以是图片、默认图标 favicon.ico 等。关键字段特征包括 HTTP 响应头里的关键字段特征信息、正常或错误页面里的关键字段特征、文件资源路径里的关键字段特征。
1.2 研究思路
本文通过基于机器学习的应用系统深度指纹识别技术及应用的研究,实现了一种使用基于机器学习的自动化安全测试工具。该系统首先通过基于机器学习的数据对安装在 Web 服务器上的软件(操作系统、中间件、框架、CMS 等)进行标识和深度识别;其次利用识别后的精确数据,使用安全检查工具(The Metasploit Framework,MSF)对标识的软件执行有效的数据分析和安全测试;最后生成扫描结果报告。该系统自动执行上述处理,如图 1 所示。
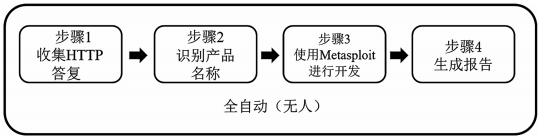
图 1 系统处理步骤
用 户 的 操 作 只 输 入 目 标 Web 服 务 器 的 顶 部URL(TOP UR),系统就自动爬取收集目标服务器的数据信息,获取域名信息,探测 Web 应用程序的目录结构,识别 Web 应用程序的技术栈,发现敏感信息等。通过系统智能化分析,用户可以在不花费时间和精力的情况下自动识别 Web 服务器的构建特征信息、组件信息和脆弱性信息等。
2研究内容及方法
2.1 HTTP 信息收集爬虫技术
HTTP 信息收集爬虫技术是一种利用 HTTP 协议进行信息收集和抓取的技术方法。它通过模拟HTTP 请求,访问目标网站的不同页面,获取网页内容并提取有用的信息。
本文利用爬虫技术收集目标网站的 HTTP 响应报文包,在用户输入 TOP URL 后,自动扩展目标网站资源、路径链接,进行原始响应数据的爬取。信息收集爬虫技术基本原理为:网络爬虫通过HTTP 链接输入并向目标站点发起请求,即发送一个 Request 请求,请求数据可以包含 Headers(附加信息)、Cookies 等信息,等待后台的响应。后台正常接收并响应返回一个 Response 响应数据,响应报文中的响应体包含网页信息,可能有 HTML、文档、图片、视频等资源文件或者 JSON 数据等 [3]。HTML解析可以使用网页解析库和正则表达式进行处理。如果是 JSON 的话,可以直接转成 JOSN 对象进行解析。如果是其他资源文件,就先保存等待爬取完成后处理。爬虫可以用不同种形式来存储网页信息、生成文本文档,或者直接保存到数据库。
本文通过 Scrapy 框架来实现信息收集爬虫技术。Scrapy 是一个为了爬取网站内容、提取结构性数据而编写的开源爬虫应用框架。可以运用在数据挖掘、信息处理或者存储历史数据等一系列程序中。使用 Scrapy 框架可以方便地自定义爬虫的爬取规则,此外,还有很多稳定的开源库帮助本文进行前置后续处理。
HTTP 信息收集爬虫技术的实现步骤如下:
(1)确定目标网站:首先需要确定要爬取的目标网站,包括网站的 URL 和要抓取的页面。
(2)构建爬虫程序:根据所选的编程语言和爬虫框架,编写爬虫程序。爬虫程序需要实现 URL管理、HTTP 请求、页面分析以及数据存储等功能。
(3)发送 HTTP 请求:爬虫根据 URL 队列中的待访问 URL,构造 HTTP 请求,并发送给目标服务器。HTTP 请求中包含请求方法(GET、POST 等)、请求头(headers)、请求体(body)等信息。
(4)处理服务器响应:爬虫接收到目标服务器返回的 HTTP 响应,并根据响应的状态码和内容进行处理。常见的响应状态码有 200 表示成功,404 表示页面不存在等。
(5)页面分析和信息提取:爬虫对服务器返回的 HTML 页面进行解析和分析,根据页面分析技术提取出所需的信息,如文字、链接、图片等。
(6)数据存储:将提取的信息进行存储,可以选择合适的存储方式,如文本文件、数据库等。
(7)循环迭代:根据需要,爬虫可以设置循环迭代的逻辑,不断发送 HTTP 请求,抓取多个页面的信息,还可以通过设置抓取深度、时间间隔等方式进行控制。
2.2 目标指纹识别技术
面向特定目标的指纹识别技术主要利用基于字符串匹配的识别技术和基于机器学习的识别技术,对前面的爬虫收集的 HTTP 响应数据集进行处理分析,从而识别目标的深度指纹信息。
2.2.1 基于字符串匹配识别
(1)原理
基于字符串匹配目标指纹识别技术是一种通过字符串匹配来识别目标的技术。它在文本、代码、日志等数据中查找指定的字符串,从而实现目标的定位和识别。
基于字符串匹配的目标指纹识别技术的原理主要包括以下几个方面。
①字符串匹配算法:字符串匹配算法是基于目标字符串和待搜索字符串之间的比较,从而确定是否存在匹配的子串。常见的字符串匹配算法包括暴力 匹 配 法、KMP(Knuth-Morris-Pratt) 算 法、BM(Boyer-Moore)算法等。本文通过 KMP 算法实现字符串匹配和目标识别。
②目标定义和关键词提取:在使用字符串匹配目标识别技术之前,需要明确目标的定义和关键词的提取。目标可以是一个特定的字符串,也可以是一组字符串的组合。关键词提取是通过文本分析和数据挖掘技术,从大量的文本数据中提取出与目标相关的关键词,用于目标识别和匹配。
③输入数据预处理:在进行字符串匹配目标识别之前,通常需要对输入数据进行预处理。这包括去除无关字符、转换大小写、分割文本等操作。预处理可以提高匹配效率和准确性,减少干扰和误判。
④匹配模式设计:匹配模式设计是指设计和实现匹配规则和模式,对目标字符串进行匹配。匹配模式可以是简单的字符串匹配,也可以是模式匹配、正则表达式匹配等更复杂的匹配方法。根据目标的特征和匹配的需求,选择合适的匹配模式进行目标识别。
⑤目标识别和处理:基于字符串匹配的目标识别技术可以通过扫描输入数据,并根据预先定义好的匹配模式和关键词,检测出目标的位置和存在。一旦识别出目标,就可以进行后续的处理,如记录日志、生成报告、触发事件等。
(2)实验验证
爬虫所爬取的数据如图 2 所示。通过字符串匹配可识别出为 Drupal 的 CMS 系统,如图 3 所示。
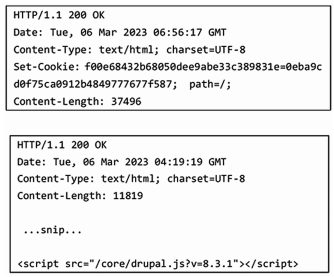
图 2 爬虫数据

图 3 字符串匹配识别
2.2.2 基于机器学习的指纹识别
(1)朴素贝叶斯算法原理
贝叶斯算法主要用于对目标进行分类,其算法思想主要基于贝叶斯原理,关键在于计算各类值之间的数据联合分布 。
由于朴素贝叶斯是假定贝叶斯模型中的所有属性都是相对独立的,因此在属性具有特定值的条件下,可以通过将所有属性乘以具有特定类标签的概率来获得类的概率值,是一种有监督学习算法。计算流程如下文所述。
步骤 1:计算特征值 y 被分类为 xi 类别的后验概率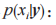
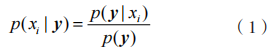
式中: 为
为 特征值的先验概率。最大化 p(y|xi) 可以实现分类的目的。
特征值的先验概率。最大化 p(y|xi) 可以实现分类的目的。
步骤 2:已知 HTTP 指纹特征 y 包含 n 维特征向量,则 y 可表示为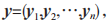 结合公式(1)可知:
结合公式(1)可知:
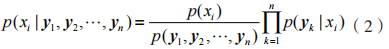
步骤 3:将公式(2)中的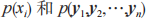 看作常量,则可简化为:
看作常量,则可简化为:
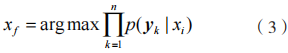
式中: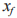 为指纹样本 y 的分类结果。
为指纹样本 y 的分类结果。
(2)特征选取
指纹特征输入到贝叶斯模型前,需要将响应内容从不同的特征维度进行表示,以便贝叶斯模型能够学习到响应内容的特征 [6-7]。本文主要从响应内容的 4 个特征维度进行考量,具体特征维度如表 1 所示。
表 1 选取的特征维度

(3)归一化
HTTP 请求特征和 URL 特征在数据分布区间上存在差异,容易导致模型训练不收敛,因此采用公式(4)对特征向量进行归一化:

式中:y 为归一化后的特征元素;x 为待归一化的特征元素; 分别为特征元素的最大值和最小值。
分别为特征元素的最大值和最小值。
(4)算法流程
步骤 1:通过 URL 地址发送请求,并获取返回的响应信息。
步骤 2:对响应信息的 3 个特征维度进行特征编码,并且对数据进行归一化处理。
步骤 3:将归一化后的数据向量作为贝叶斯模型的输入,输出结果即为预测结果。
预测流程如图 4 所示。
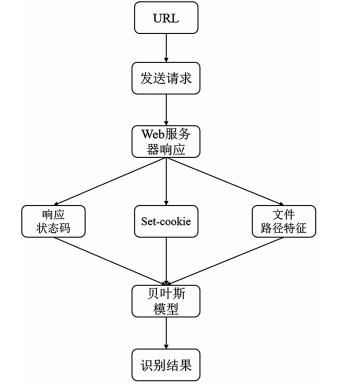
图 4 预测流程
(5)实验验证
由 于 Apache、Joomla !、Typeo、Drupal 等 每个软件的特性都略有不同,将它们组合起来进行识别。朴素贝叶斯利用训练数据学习。与签名库不同的是,当无法在一个特性中识别软件时,朴素贝叶斯是基于 HTTP 响应中包含的各种特性随机识别的,如图 5 可以识别为 CMS Joomla 系统。这是因为机器学习识别模块学会了 Joomla 的特征,例如“Cookie名称 (f00e6….9831e)”和“Cookie 值 (0eba9….7f587)”。在本文的数据分析中,Joomla 在许多情况下使用 32个小写字母作为 Cookie 名称和 Cookie 值。训练数据如图 6 所示。

图 5 响应 set-cookie 值

图 6 训练数据
基于机器学习指纹识别实验获取的目标数据如图 7 所示,包括产品名称、产品版本、组件名、操作系统版本。
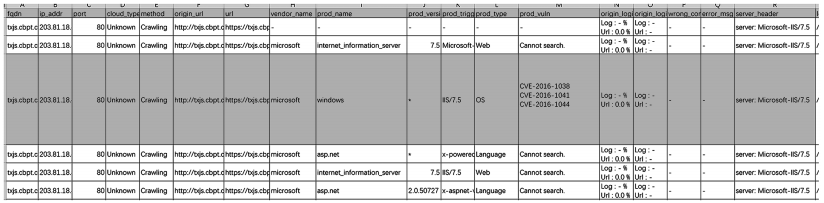
图 7 基于机器学习的指纹识别数据结果
2.3 目标安全缺陷利用技术
Metasploit 是一个被广泛使用的安全测试工具,它可以帮助安全专业人员发现和利用计算机系统中的安全漏洞。它拥有强大的功能和广泛的支持,可以帮助用户从安全测试者的角度来检测和修复系统漏洞。基于机器学习的指纹识别软件在安全测试中的作用是识别目标系统的运行环境。通过分析系统的响应和标识信息,目标指纹识别软件可以确定目标系统使用的操作系统、服务和软件版本等重要信息。这些信息对于成功利用系统漏洞至关重要,因为不同的操作系统和服务可能存在不同的漏洞。
本文通过基于机器学习指纹识别软件与Metasploit 工具配合执行,检查被测目标是否受到漏洞的影响,来自动化实现目标安全缺陷利用,如图 8 所示。
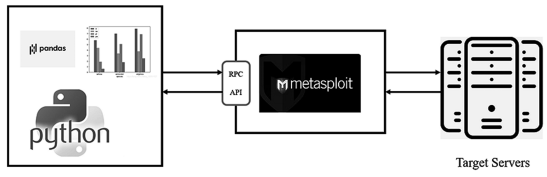
图 8 应用思路
整体应用思路过程如下文所述。
(1)数据收集:机器学习指纹识别软件通过扫描目标系统收集关键特征数据,如操作系统版本、软件配置等。
(2)特征提取和训练:收集到的特征数据被提供给机器学习算法进行训练。这个训练过程会建立一个指纹库,其中包含已知的漏洞特征和与之相应的利用。
(3)特征匹配:在执行利用之前,使用指纹识别软件对目标系统进行扫描,并提取目标系统的特征;然后,与指纹库中已知的漏洞特征进行匹配,如果匹配成功,就意味着目标系统可能存在与已知漏洞对应的安全缺陷。
(4)目标缺陷利用:机器学习指纹识别软件 通 过 Metasploit 框 架 的 远 程 过 程 调 用(Remote Procedure Call,RPC)服务与 Metasploit 工具进行通信连接,实现安全测试流程自动化。一旦匹配到目标系统的漏洞,Metasploit 框架可以根据匹配结果自动选择相应的漏洞利用模块进行测试。这样,目标缺陷利用的过程可以自动化和精确地执行。
将 Metasploit 和基于机器学习的指纹识别软件结合使用,可以提高安全测试的效率和成功率。首先,Metasploit 通过使用模块来实现对目标系统的漏洞利用。Metasploit 拥有大量的模块,包括扫描器、漏洞利用器、Payload 生成器等。用户可以根据目标系统的特点选择相应的模块进行测试和利用。其次,Metasploit 可以根据目标指纹识别软件提供的信息选择适当的模块进行漏洞测试和利用。例如,如果目标系统被识别为运行着一个特定版本的 Web服务器软件,Metasploit 可以选择相应的漏洞利用模块来检测和利用该软件版本的安全漏洞。同样重要的是,Metasploit 还可以使用 Payload 生成器来生成定制的载荷。用户可以根据目标系统的特点选择合适的 Payload 生成器来生成特定的载荷,以实现对目标系统的完全控制。
目标安全缺陷利用验证效果见图 9。
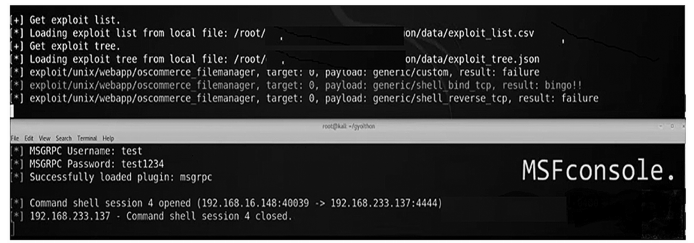
图 9 目标安全缺陷验证效果
综上所述,这种结合使用的目标安全缺陷利用方法可以帮助安全测试人员更准确、高效地对目标系统进行评估和测试。
3结语
基于机器学习的应用系统深度指纹识别技术是面向信息安全测试领域的智能安全测试技术。本文在深入研究信息收集爬虫技术和基于机器识别的指纹识别技术的基础上,实现了相关功能模块,结合基于 Metasploit 的目标安全缺陷利用实现,进行实网目标测试实验,提高了互联网目标安全测试的效率和成功率,且实验验证结果符合预期。
审核编辑:汤梓红
-
基于单片机的指纹识别门禁系统设计资料分享2022-01-24 1421
-
设计一种基于单片机的指纹识别系统2021-11-19 2839
-
绝对实用的ARM指纹识别系统方案2021-11-09 1255
-
Android指纹识别系统的原理与使用相关资料分享2021-06-30 1330
-
指纹识别传感器的原理是什么2020-05-20 4071
-
指纹识别应用了什么技术_指纹识别的特点2020-04-02 14197
-
如何开发嵌入式指纹识别系统?2019-09-20 3625
-
指纹识别技术原理及发展2018-11-12 4135
-
指纹识别算法2016-08-23 4516
-
指纹识别技术的研究2016-02-25 941
-
基于指纹识别技术的防盗门控制系统的设计?2016-02-22 4114
-
新唐指纹识别2015-01-27 5293
-
win7系统如何设置指纹识别2014-09-22 2784
-
指纹识别技术详解2007-10-16 1911
全部0条评论

快来发表一下你的评论吧 !
