

LLM的Transformer是否可以直接处理视觉Token?
人工智能
描述
宣传一下最近的新工作,个人感觉是读博以来做得最难最累但是成就感也最大的一个项目。它起源自一个很简单的问题——自LLM诞生以来,我们见到了很多把LLM接到Vision Backbone后面的算法,那么有两个自然的问题:
LLM的Transformer是否可以直接处理视觉Token?
LLM的Transformer是否可以提升处理视觉Token的Performance?
我们的工作回答了这两个问题 (答案是Yes) 而且解释了其中的原因:在语言模型中Pretrain的Transformer可以用作视觉任务的Encoder Layer。代码已经开源,欢迎大家点赞关注我们的Paper和GitHub。

Frozen Transformers in Language Models Are Effective Visual Encoder Layers 代码:github.com/ziqipang/LM4VisualEncoding
论文:https://arxiv.org/abs/2310.12973
1. LLM的Transformer可以处理视觉Token吗?
在LLM的加持下,很多Vision-language Model 会直接把来自图像的Embedding输入给LLM,并让LLM作为Decoder输出文字、类别、检测框等。但是在这些模型中,LLM并不会直接处理来自图像的Token,它们更多地是 (1) 处理提前设计好的语义Token,例如CLIP中的cls token;(2) 处理被压缩过的Token,例如BLIP里面经过information bottleneck的token。那么LLM是否可以直接作用于其它模态的Token呢,即LLM是否可以用作Encoder,而不只是Decoder呢?
1.1 实验方法
验证这个事情非常简单,以ViT为例,我们只需要:
取出某一个LLM的Transformer Layer (例如LLaMA的最后一个Transformer),请注意这里只需要一个Transformer Block而不是整个LLM;
把它加入到最后一个Encoder Block后面,只需要额外两个Linear Layers把Feature Dimensions拉齐;
冻结LLM的Transformer,但是正常训练其它部分。
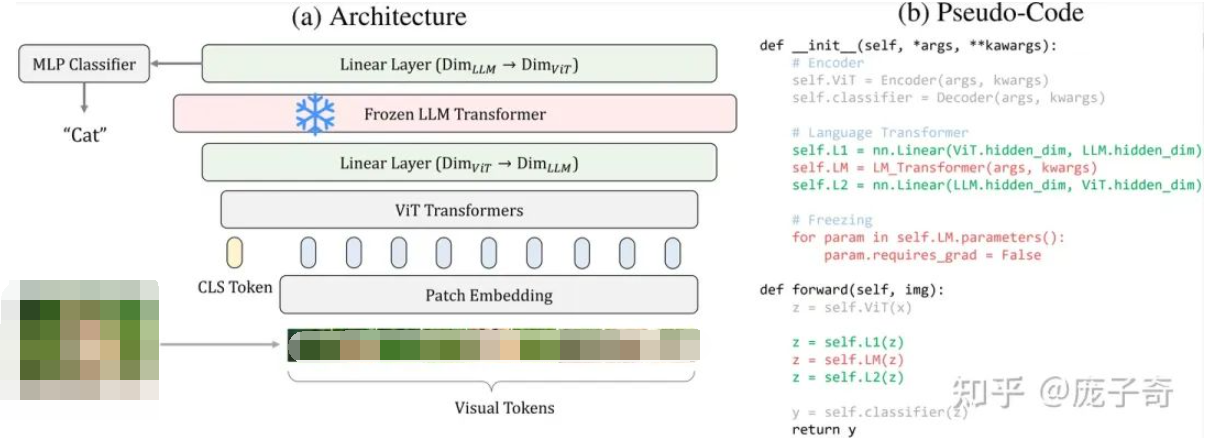
以ViT为例,我们的模型结构非常简单,只需要额外两个线性层
1.2 和现在的Vision-language Model的异同
是否需要Pretraining?我们的方法重在提升Encoding能力,所以我们既支持Train-from-scratch,也支持Finetune,而不是必须要依赖预训练好的Backbones。
是否需要Language?虽然我们用的是LLM的Transformer,但是我们的Framework独立于使用Language (比如Prompts或者Alignment),而不是像Vision-language Models一样必须要Language。
可以处理多少模态?我们的Framework可以泛化到多个模态和任务,而不是只能处理图像。
Encoder和Decoder有什么区别?Encoder需要直接和Visual tokens打交道,比如和HxW个图像token的信息做Cross-attention去改变cls token。
现在已经有这么多Vision-language Models了,你们的研究有什么用?首先,我们的研究和现在的vision-language Models不矛盾而且互相补充——现在vision-language model研究如何把视觉embedding输入给LLM,而我们的研究聚焦如何提供更好的embedding。
1.3 一个预训练的LLaMA Transformer在许多不同模态、任务的Encoder上都有用
在论文中,我们发现把LLM的Transformer用作视觉Encoder可以泛化到极其多样的场景。
2D语义:图像分类 (image classification)
点云:点云分类 (point cloud classification)
视频:动作识别 (action recognition)
无语义,回归任务:轨迹预测 (motion forecasting)
2D多模态:2D VQA和图像搜索 (2D VQA and Retrieval)
3D多模态:3D VQA
在这些任务中,我们的模型不只要处理图像上像patch一样的Token,还要处理
点云中无规则的3D点
视频中形状是TxHxW的长方体形状的token
轨迹预测里面来自Agent和高精地图的Polylines
多模态任务中混合了图像和语言的Token
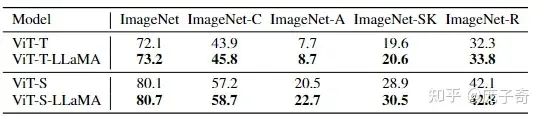
ImageNet, 图像分类

2D/3D 语言多模态任务

自动驾驶,轨迹预测
2. 为什么预训练的LLM Transformer有用:Information Filtering Hypothesis
虽然我们在许多任务和模态上都看到了性能的提升,但是如何解释这一点呢?我们在研究的过程中感觉如果把加了LLM的提升都归结于"LLM包含了可以泛化的知识",其实比较偷懒而且不一定正确。所以我们研究了Token在加LLM transformer前后的变化提出了Information Filtering假设:
LLM Transformer模块能够在训练的过程中筛选和目标任务相关的Visual Tokens并且放大他们的贡献。
这个结论是我们paper里面可能最重要的发现。
2.1 在ViT上的观察 —— LLM Transformer筛选出了前景
为什么可以这么说呢?我们看下图中我们对ViT的Token Activation的可视化:为了体现不同Token的贡献,我们从本身Activation的大小(L2-norm)和频率大小进行了可视化(做傅里叶变换后算角度的L2-norm)。
可以看到:在有了LLM Transformer之后,ViT的Activation能更干净地集中到前景区域,而这个性质只有在无监督学习的ViT中(e.g. DINO)中可以见到,在监督学习的ViT中很少见。
另一方面,我们对比了有/没有LLM transformer对于Attention weight的影响:普通的ViT的Attention Weight几乎是完全Noisy的 (和DINO的观察吻合),在加了LLMTransformer之后 (1) 有极少的Attention Head体现出了干净的前景分割的样子,但是 (2) 它们的数量较少不足以解释Token Activation更显著地好。
因此,我们观察到的提升来自有用的Feature被放大了,这也是为什么我们称之为information filtering hypothesis。
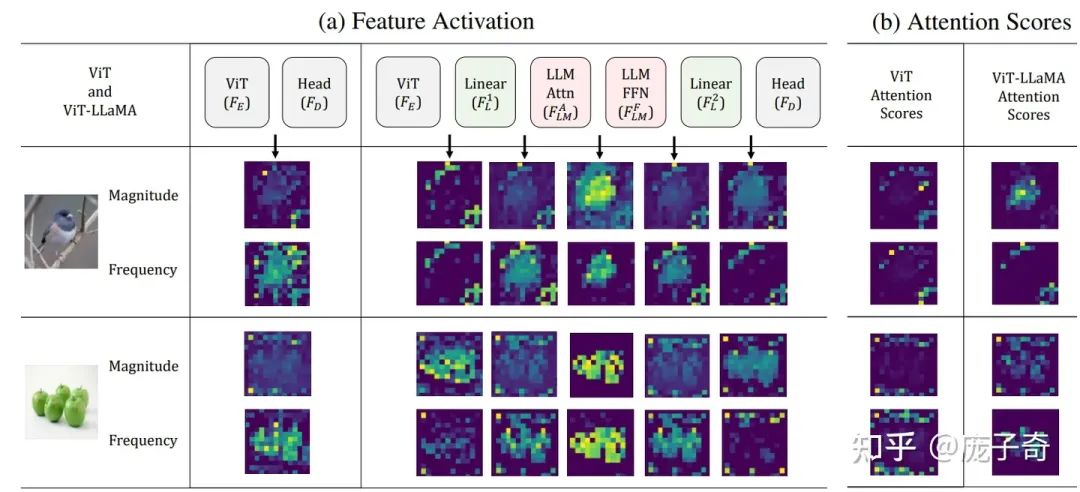
2.2 在其它任务的也可以筛选有用的Token
类似的“information filtering”现象不只在ViT和图像分类上有,在其它任务上,LLM Transformer也有效地提升了对目标任务最有用的Token。这里我们举两个例子:
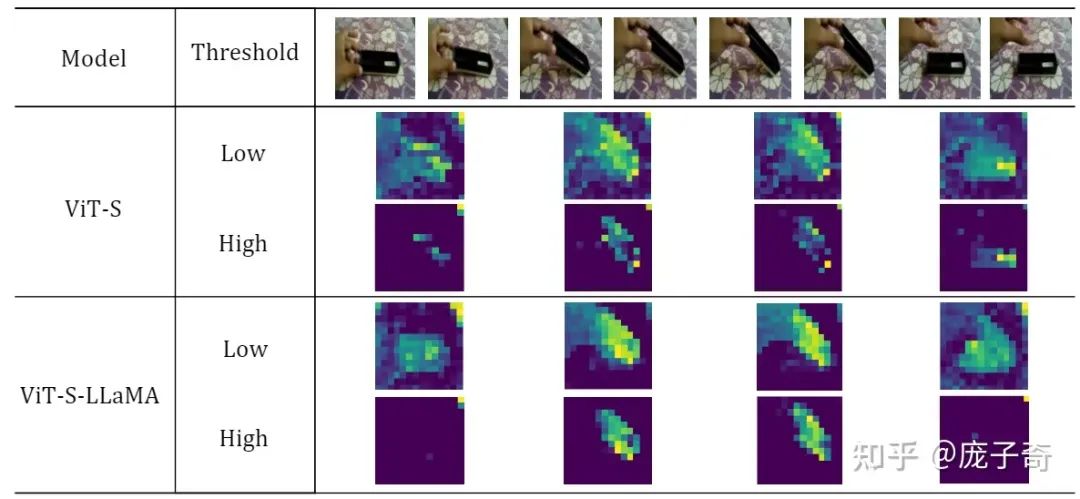
在动作识别中,加了LLaMA的Transformer可以更好地集中到前景的手和物体(low threshold),也更多地筛选出了手和物体有实际动作的帧(high threshold)。
在3D VQA中,我们可视化了点云Token的大小。可以看到,那些真正和预测目标、或者问题相关的点得到了更大的关注:比如在左图中,"behind me"的点云显著得到了更大的Activation (颜色更亮了)。

3. 一点Ablation Study
那么我们观察到的现象,即LLM的Transformer可以提升Visual Encoding,是否和不同的层、LLM有关呢?
多种LLM Transformer都可以提升Visual Encoding。例如用LLaMA和OPT的不同Transformer层都会有提升,而且不同层之间也会体现不同的规律。
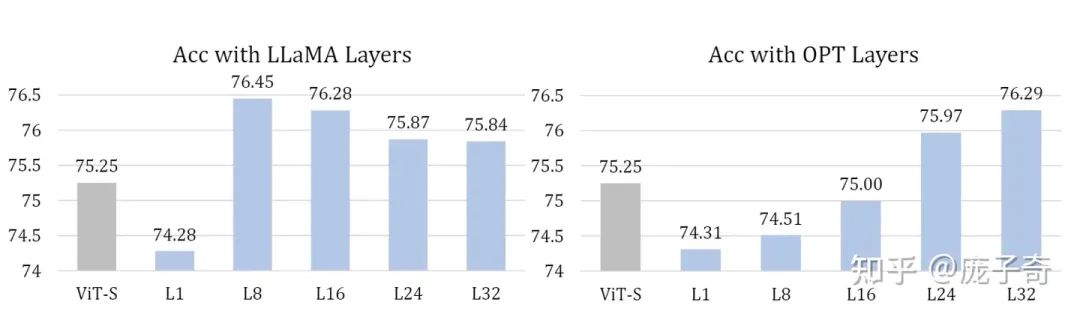
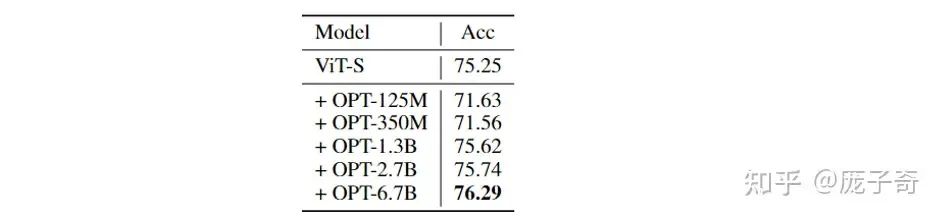
只有足够大的LLM才有提升Visual Encoding的效果。例如只有足够大的OPT才会提升Visual Encoding的效果。
4. 后记
最后写一些没有写在Paper里面的自己的感受和思考:
在论文中最让我感到兴奋的不是结合了LLM在很多Task上都有提升,而是在我们Information filtering假设的分析中看到了质变:神经网络能够更好地学习到那些和任务最相关的Token。
那么为什么会有这样的效果?我猜测是LLM的Transformer的参数矩阵,例如FFN的矩阵,有一些很好的性质,例如在某些情况下是一个高通滤波器。我们可以从反面思考,如果一个参数矩阵是随机初始化(低通滤波器),或者干脆就是一个单位矩阵,那么必然不可能去筛选出来有用的Token,并且放大他们的贡献。
在尝试解释这个现象的时候,我们发现用transfer learning的工具来分析会非常有难度,因为我们不能保证vision和language确实在一层transformer之后就align了。最终,一个比较合理的直觉是受到了我本科同学许逸伦"A Theory of Usable Information Under Computational Constraints"这篇Paper的启发:我们可以把LLM Transformer看作一种Decipher,它提升了Feature的有用性,使得一层MLP或者Decoder的有限计算资源可以把Feature映射到和真实结果Mutual Information更高的空间中。事实上,这也契合我们Information filtering的观察。
编辑:黄飞
-
Transformer架构中编码器的工作流程2025-06-10 1440
-
什么是LLM?LLM在自然语言处理中的应用2024-11-19 5305
-
LLM和传统机器学习的区别2024-11-08 3484
-
英伟达推出归一化Transformer,革命性提升LLM训练速度2024-10-23 1664
-
llm模型和chatGPT的区别2024-07-09 2959
-
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:1,LLM部署2024-06-25 1587
-
LLM推理加速新范式!推测解码(Speculative Decoding)最新综述2024-01-29 6772
-
Transformer压缩部署的前沿技术:RPTQ与PB-LLM2024-01-24 2372
-
一文详解LLM模型基本架构2023-12-25 5071
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 2854
-
CVPR 2023 | 清华大学提出LiVT,用视觉Transformer学习长尾数据2023-06-18 1220
-
Transformer在下一个token预测任务上的SGD训练动态2023-06-12 1711
-
基于视觉transformer的高效时空特征学习算法2022-12-12 2857
-
用于语言和视觉处理的高效 Transformer能在多种语言和视觉任务中带来优异效果2021-12-28 2844
全部0条评论

快来发表一下你的评论吧 !
