

科大讯飞ICDAR 2023收获四项冠军,图文识别理解能力持续进阶
人工智能
描述
作为文档图像分析识别领域最重要的国际会议之一,国际文档分析与识别会议ICDAR 2023(International Conference on Document Analysis and Recognition)近期传来好消息: 科大讯飞研究院与中科大语音及语言信息处理国家工程研究中心(以下简称研究中心)在多行公式识别、文档信息定位与提取、结构化文本信息抽取三项比赛中获得四个冠军!
MLHME之冠: 首个“多行书写”挑战赛,复杂度再突破 MLHME(多行公式识别比赛)考查输入包含手写数学公式的图像后,算法输出对应LaTex字符串正确率。值得一提的是,相比此前数学公式识别赛事,此次比赛业内首次将“多行书写”设为主要挑战对象,且不同于之前识别扫描、在线手写的公式,本次以识别拍照的手写多行公式为主。 最终,科大讯飞研究院图文识别团队以67.9%的成绩拿下冠军,并在主要评价指标——公式召回率(Expression Recall,即统计识别正确的样本数占总测试样本数的比例)上大幅超越其他参赛团队。
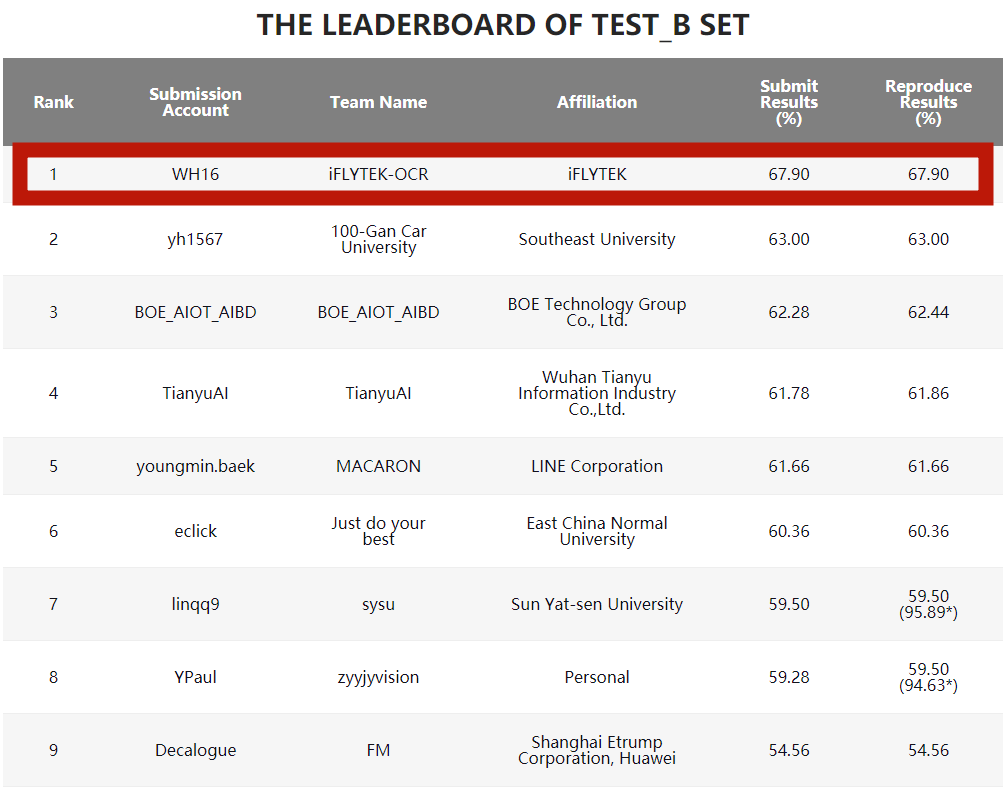
公式召回率与榜单中Submit Results相对应 针对比赛中出现的多行公式结构复杂问题,团队使用大卷积核的Conv2former作为编码器结构,扩大了模型的视野,更好地捕捉多行公式的结构特征;创新性提出基于transformer的结构化序列解码器SSD,显式对多行公式内部的层次关系做了精细化建模,极大提升了复杂结构的泛化性,更好地建模了结构化语义。
多行公式结构复杂,图片质量不高、批改干扰 针对图片质量问题所引起的字符歧义问题,团队创新性提出了语义增强的解码器训练算法,通过语义和视觉的联合训练,让解码器具备内在的领域知识。当字符难以辨认时,模型能够自适应利用领域知识做出推理,给出最合理的识别结果。 针对字符尺寸变化大的问题,团队提出了一种自适应字符尺度估计算法和多尺度融合解码策略,极大提升了模型对字符大小变化的鲁棒性。
DocILE之冠:“行里挑一” 文档信息定位与提取比赛双赛道登顶榜首 DocILE(文档信息定位与提取比赛)评估机器学习方法在半结构化的商业文档中,对关键信息定位、提取和行项识别的性能。该赛事分为KILE和LIR两个赛道任务,讯飞与研究中心最终收获双赛道冠军。
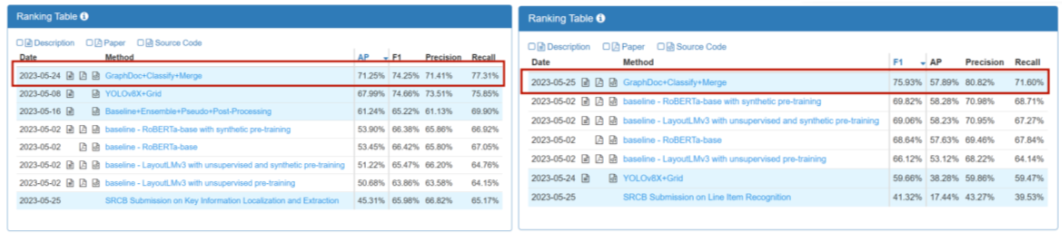
KILE赛道榜单和LIR赛道榜单双第一
此次赛事,文档中待抽取的信息种类非常繁杂。面对挑战,联合团队在算法层面提出了两项技术创新方案: 预训练阶段设计了基于OCR质量的文档过滤器,从主办方提供的无标注文档中提取出274万页的文档图像,随后通过预训练语言模型获取文档中各文本行的语义表征,并采用掩码语句表征恢复任务进行不同Top-K(GraphDoc模型中关于文档的注意力范围的一个超参数)配置下的预训练。
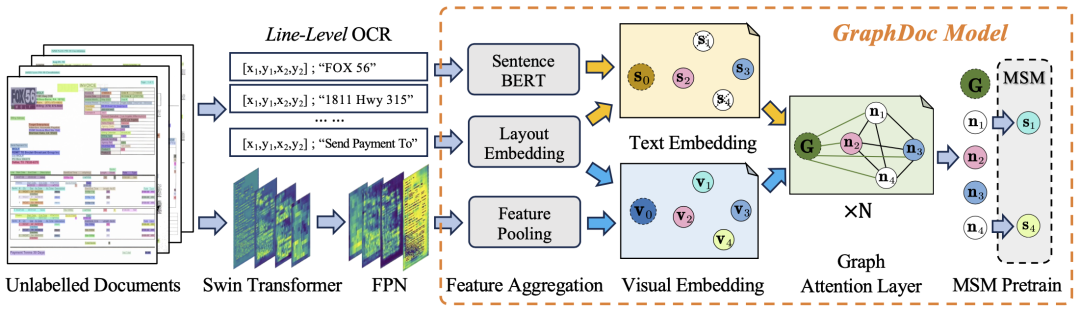
在数据集微调阶段,团队使用了预训练后的GraphDoc提取文本框的多模态表征,并进行分类操作。在分类结果的基础上,将多模态表征送入低层注意力融合模块进行实例的聚合,在实例聚集的基础上,使用高层注意力融合模块实现行项实例的聚集,所提出的注意力融合模块结构相同、但彼此不共享参数,可以同时用于KILE和LIR任务且具有很好的效果。
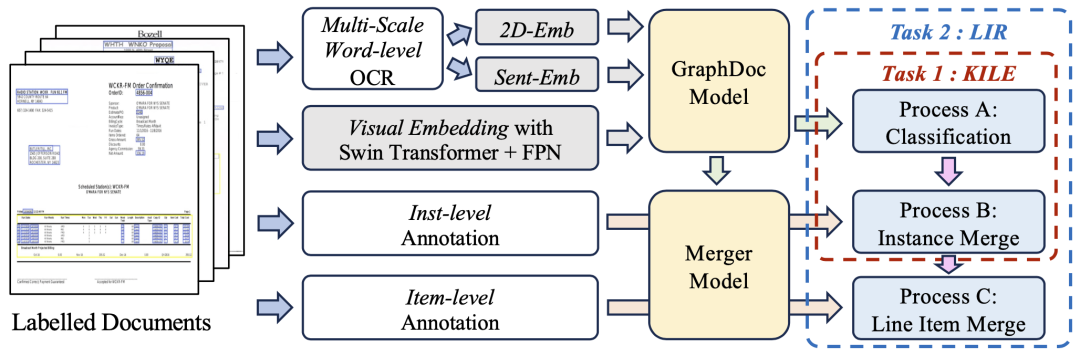
SVRD之冠:零样本票证结构化信息抽取任务第一 预训练模型大考验 SVRD(结构化文本信息抽取)比赛分为4个赛道子任务,讯飞与研究中心在难度颇高的零样本结构化信息抽取子赛道(Task3:E2E Zero-shot Structured Text Extraction)获得第一。
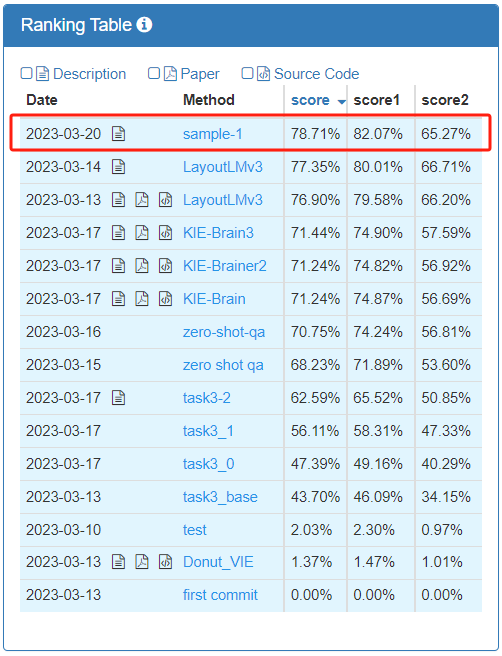
榜单排名 零样本对预训练模型能力提出了更高要求。同时,比赛使用的发票版式多样、同一个要素名称不同、照片背景干扰、反光、文字重叠等问题,进一步提升了识别和抽取难度。
不同版式的发票以及条纹背景干扰的发票 团队首先对要素抽取模型采用复制-生成双分支解码策略,在前端OCR结果置信度较高的情况下直接复制OCR结果,在OCR结果置信度较低的情况下生成新的预测结果,以此缓解前端OCR模型引入的识别错误。 此外,团队还基于OCR结果提取句子级的graphdoc特征作为要素抽取模型输入,该特征融合了图像、文本、位置、版面多模态特征,相比于单模态的纯文本输入具有更强的特征表示。 在此基础上,团队还结合了UniLM、LiLT、DocPrompt多个要素抽取模型在不同场景、不同语种上的性能优势进一步提升了最终的要素抽取效果。
教育、金融、医疗等已落地应用 科大讯飞在ICDAR 2023数个比赛中“多点开花”,既是在图文识别理解技术上的持续进步,也是应用落地的不断扩宽。此次夺冠的技术,也已经深入教育、金融、医疗、智能硬件等领域,赋能多项业务与产品。 在教育领域,手写公式识别的技术能力被高频使用,机器能给予精准的识别、判断和批改。例如科大讯飞AI学习机中的个性化精准学、AI诊断;老师上课所使用的“讯飞智慧窗”教学大屏、学生的个性化学习手册等,都已发挥了很大成效。
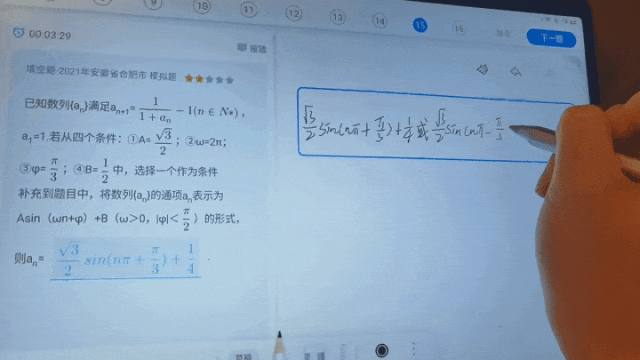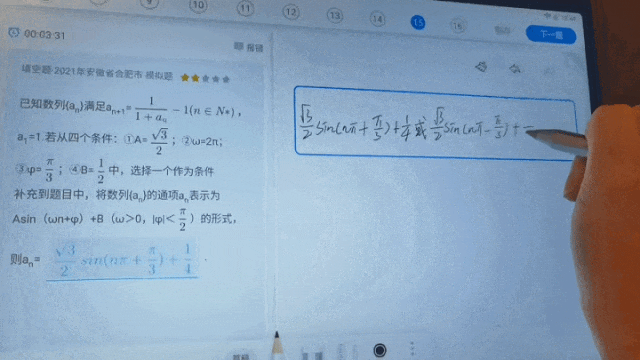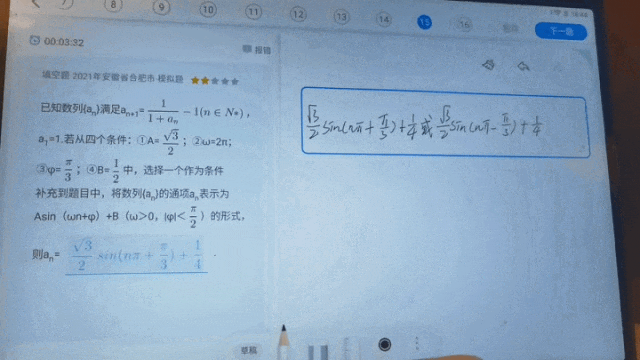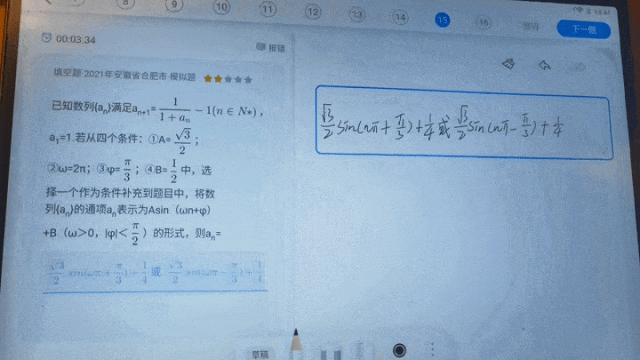
不久前科大讯飞全球1024开发者节上发布的星火科研助手,三大核心功能之一的论文研读可实现智能解读论文,快速回答相关问题。后续在高精度公式识别基础上进阶有机化学结构式、图形、图标、流程图、表格等结构化场景识别的效果,这项功能也会更好助力科研工作者提升效率。

文档信息定位与抽取技术则在金融领域得到了广泛运用,例如合同要素抽取与审核、银行票据要素抽取、营销内容消保审查等场景,可以实现文档或文件的数据解析、信息抽取和比对审核等功能,从而辅助业务数据的快速录入、抽取、比对,实现审核过程的降本增效。
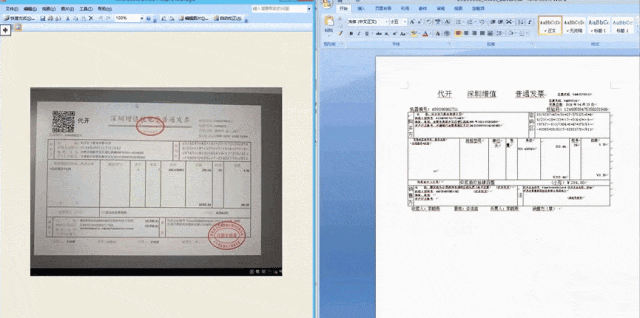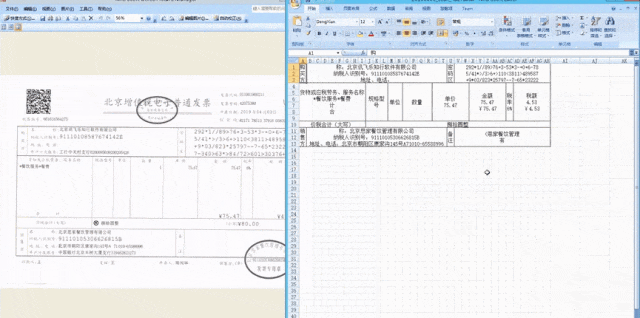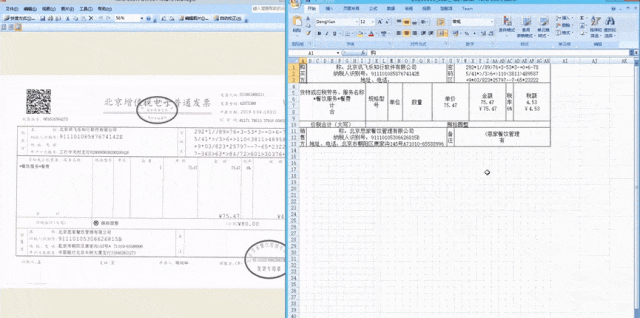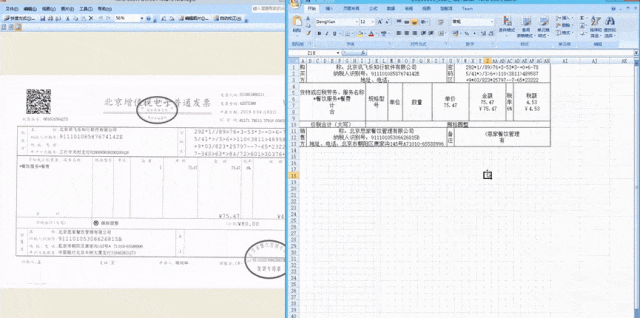
同样在今年1024上发布的个人AI健康助手——讯飞晓医,不仅能扫描检查单、化验单识别后给出分析和建议,还可以扫描药盒后进一步主动询问、给出辅助用药建议。对于体检报告,拍照上传后讯飞晓医可以识别全维度关键信息,联合异常指标综合解读,主动询问发现更多问题给予帮助。当然,背后也是文档信息定位与抽取技术的支持。

从单字识别、文本行识别,到难度更高的二维复杂结构识别、篇章级识别,科大讯飞的图文识别相关技术在算法上持续迭代突破,更强的图文识别技术还能使多模态大模型在图像描述、图像问答、识图创作、文档理解与处理上展现出更好的效果和潜力。 图文识别技术结合语音识别、语音合成、机器翻译等技术形成系统性创新,也将赋能产品应用展现出更强大的功能,融入千行百业,走进千家万户。
-
科大讯飞发布讯飞星火4.0 Turbo:七大能力超GPT-4 Turbo2024-10-24 1968
-
科大讯飞星火大模型新添功能,语音台历即将面世2024-04-28 1256
-
科大讯飞首次亮相迪拜GITEX Global 2023,探索科技创新未来!2023-10-11 1868
-
AI办公赛道持续领跑 科大讯飞发布双十一终极战报2021-11-12 3802
-
科大讯飞夺冠2019年度计算机视觉顶级会议CVPR和ICDAR多项评测2019-06-26 5321
-
科大讯飞董事长刘庆峰:20年不断累积,AI技术价值今年将开始兑现2019-05-25 6353
-
科大讯飞的商业出路是在另辟溪路吗?2019-03-06 8507
-
破局与进阶,科大讯飞的新武器“讯飞阅读”2018-10-17 490
-
全球首家!讯飞AI电话能力平台开放合作!2018-09-10 4971
-
新能力上线 | 讯飞AI能力星云赋能人脸识别、内容审核!2018-08-03 12054
-
新能力上线 | 讯飞AI能力星云赋能,4项OCR技术助力“证”途!2018-07-06 3802
-
科大讯飞股票怎么样_科大讯飞股票分析2018-03-05 15116
全部0条评论

快来发表一下你的评论吧 !
