

NeurIPS 2023 | 如何从理论上研究生成式数据增强的效果?
描述

代码链接:
https://github.com/ML-GSAI/Understanding-GDA

概述
生成式数据扩增通过条件生成模型生成新样本来扩展数据集,从而提高各种学习任务的分类性能。然而,很少有人从理论上研究生成数据增强的效果。为了填补这一空白,我们在这种非独立同分布环境下构建了基于稳定性的通用泛化误差界。基于通用的泛化界,我们进一步了探究了高斯混合模型和生成对抗网络的学习情况。
在这两种情况下,我们证明了,虽然生成式数据增强并不能享受更快的学习率,但当训练集较小时,它可以在一个常数的水平上提高学习保证,这在发生过拟合时是非常重要的。最后,高斯混合模型的仿真结果和生成式对抗网络的实验结果都支持我们的理论结论。

主要的理论结果
2.1 符号与定义
让 作为数据输入空间, 作为标签空间。定义 为 上的真实分布。给定集合 ,我们定义 为去掉第 个数据后剩下的集合, 为把第 个数据换成 后的集合。我们用 表示 total variation distance。
我们让 为所有从 到 的所有可测函数, 为学习算法,为从数据集 中学到的映射。对于一个学到的映射 和损失函数 ,真实误差 被定义为 。相应的经验的误差 被定义为 。
我们文章理论推导采用的是稳定性框架,我们称算法 相对于损失函数 是一致 稳定的,如果
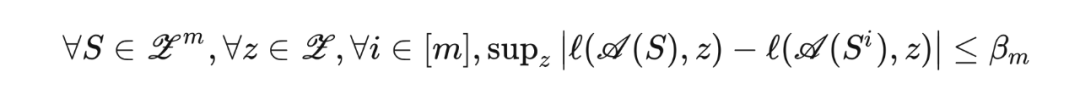
2.2 生成式数据增强
给定带有 个 i.i.d. 样本的 数据集,我们能训练一个条件生成模型 ,并将学到的分布定义为 。基于训练得到的条件生成模型,我们能生成一个新的具有 个 i.i.d. 样本的数据集 。我们记增广后的数据集 大小为 。我们可以在增广后的数据集上学到映射 。为了理解生成式数据增强,我们关心泛化误差 。据我们所知,这是第一个理解生成式数据增强泛化误差的工作。2.3 一般情况
我们可以对于任意的生成器和一致 稳定的分类器,推得如下的泛化误差: ▲ general一般来说,我们比较关心泛化误差界关于样本数 的收敛率。将 看成超参数,并将后面两项记为 generalization error w.r.t. mixed distribution,我们可以定义如下的“最有效的增强数量”:
▲ general一般来说,我们比较关心泛化误差界关于样本数 的收敛率。将 看成超参数,并将后面两项记为 generalization error w.r.t. mixed distribution,我们可以定义如下的“最有效的增强数量”:


▲ corollary
2.4 高斯混合模型为了验证我们理论的正确性,我们先考虑了一个简单的高斯混合模型的 setting。 混合高斯分布。我们考虑二分类任务 。我们假设真实分布满足 and 。我们假设 的分布是已知的。 线性分类器。我们考虑一个被 参数化的分类器,预测函数为 。给定训练集, 通过最小化负对数似然损失函数得到,即最小化
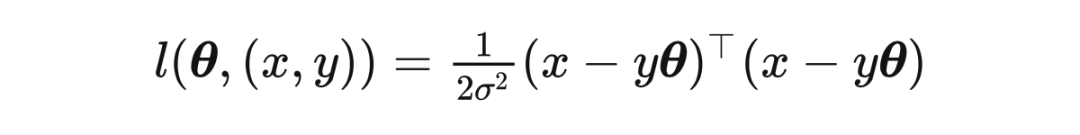
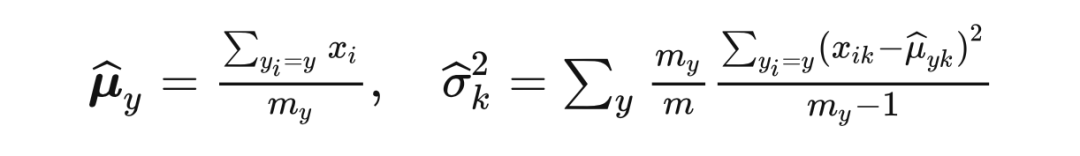

- 当数据量 足够时,即使我们采用“最有效的增强数量”,生成式数据增强也难以提高下游任务的分类性能。
- 当数据量 较小的,此时主导泛化误差的是维度等其他项,此时进行生成式数据增强可以常数级降低泛化误差,这意味着在过拟合的场景下,生成式数据增强是很有必要的。
2.5 生成对抗网络
我们也考虑了深度学习的情况。我们假设生成模型为 MLP 生成对抗网络,分类器为 层 MLP 或者 CNN。损失函数为二元交叉熵,优化算法为 SGD。我们假设损失函数平滑,并且第 层的神经网络参数可以被 控制。我们可以推得如下的结论:

- 当数据量 足够时,生成式数据增强也难以提高下游任务的分类性能,甚至会恶化。
- 当数据量 较小的,此时主导泛化误差的是维度等其他项,此时进行生成式数据增强可以常数级降低泛化误差,同样地,这意味着在过拟合的场景下,生成式数据增强是很有必要的。

实验
3.1 高斯混合模型模拟实验
我们在混合高斯分布上验证我们的理论,我们调整数据量 ,数据维度 以及 。实验结果如下图所示:
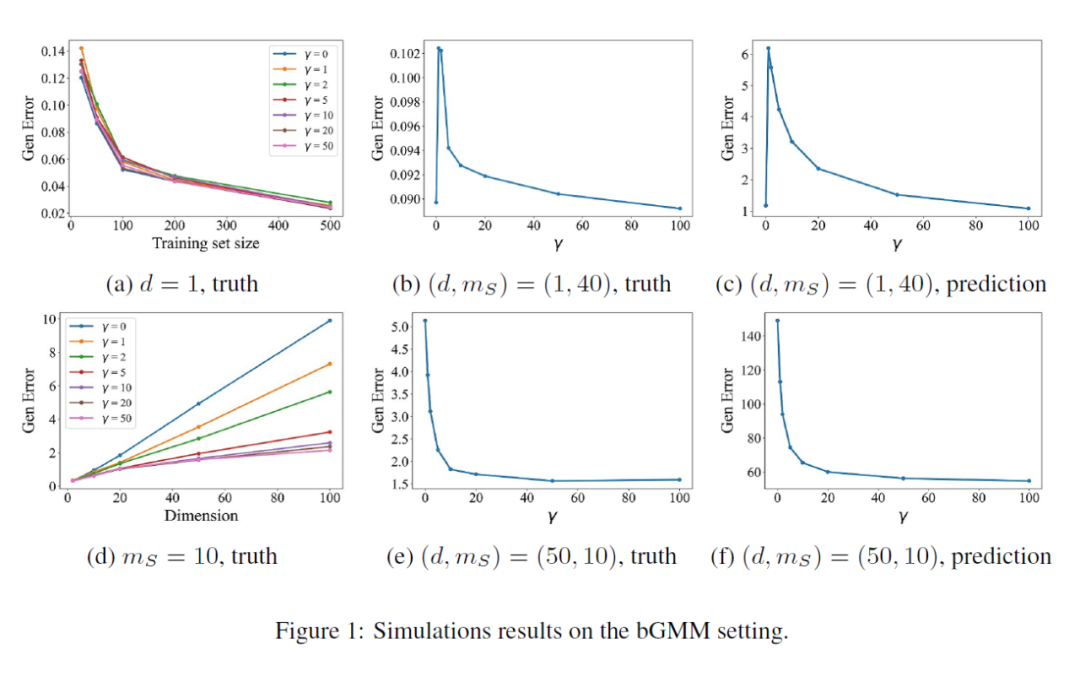
▲ simulation
- 观察图(a),我们可以发现当 相对于 足够大的时候,生成式数据增强的引入并不能明显改变泛化误差。
- 观察图(d),我们可以发现当 固定时,真实的泛化误差确实是 阶的,且随着增强数量 的增大,泛化误差呈现常数级的降低。
- 另外 4 张图,我们选取了两种情况,验证了我们的 bound 能在趋势上一定程度上预测泛化误差。
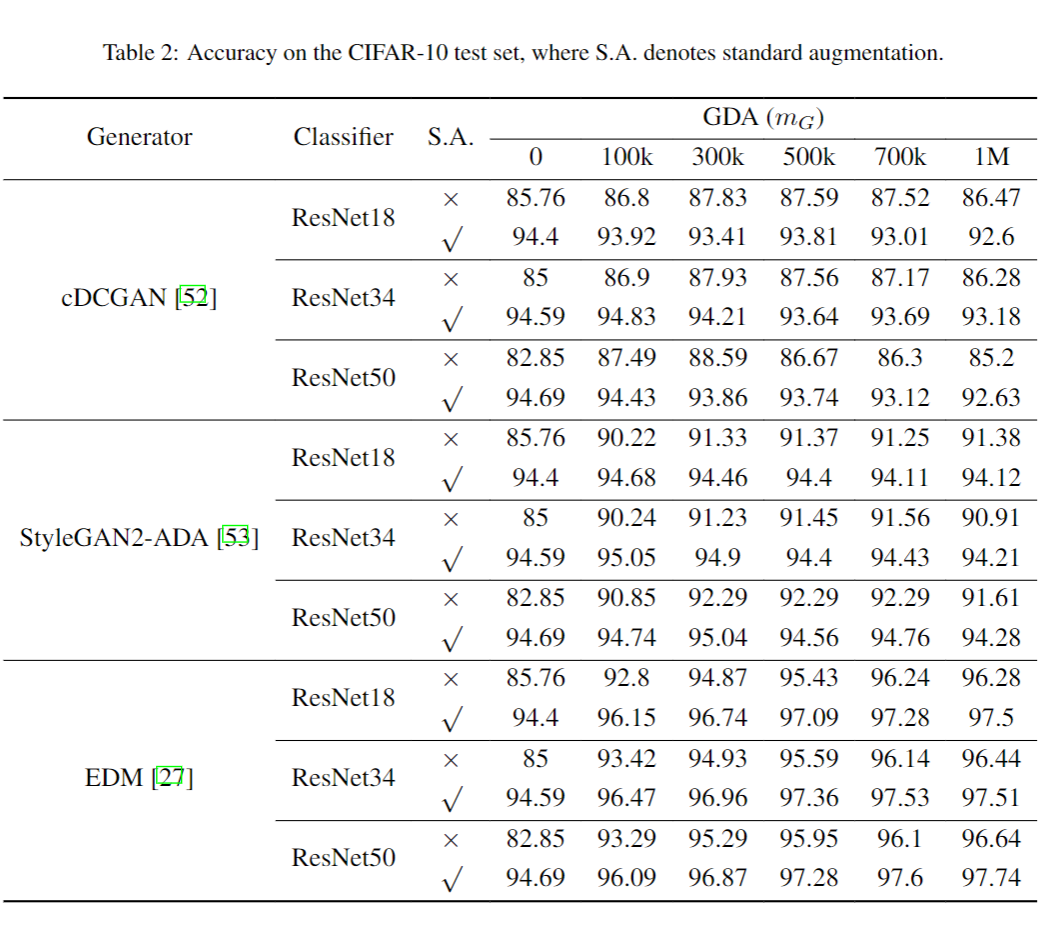
▲ deep
- 在没有额外数据增强的时候, 较小,分类器陷入了严重的过拟合。此时,即使选取的 cDCGAN 很古早(bad GAN),生成式数据增强都能带来明显的提升。
- 在有额外数据增强的时候, 充足。此时,即使选取的 StyleGAN 很先进(SOTA GAN),生成式数据增强都难以带来明显的提升,在 50k 和 100k 增强的情况下甚至都造成了一致的损害。
-
我们也测试了一个 SOTA 的扩散模型 EDM,发现即使在有额外数据增强的时候,生成式数据增强也能提升分类效果。这意味着扩散模型学习分布的能力可能会优于 GAN。
原文标题:NeurIPS 2023 | 如何从理论上研究生成式数据增强的效果?
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 物联网
-
研究生2013-09-16 3300
-
如何用555做频率可调且占空比理论上维持40%不变的电路方波2014-10-12 4722
-
作为研究生自学嵌入式如何?以及嵌入式的发展。2016-09-08 8040
-
为什么理论上电感器,不会消耗电能?2017-05-18 5006
-
风机性能测试系统的设计与研究2021-09-06 1927
-
为什么生成模型值得研究2021-09-15 1746
-
基于熵权的研究生培养质量多级模糊评价2018-01-04 882
-
量子安全超级SIM卡问世,量子加密理论上是无法破解的2020-09-18 5451
-
从理论上来看,人类不可能控制超级人工智能2021-01-21 2921
-
生成式对抗网络应用及研究综述2021-06-09 1041
-
NVIDIA 凭借生成式 AI 和通用智能体方面的研究获得 NeurIPS 奖2022-12-01 1155
-
英伟达 GTC 2023上黄仁勋谈生成式AI2023-03-22 2893
-
软件开发的未来:生成式AI增强角色并解锁共同创新2023-06-09 1018
-
英特尔研究院将在NeurIPS大会上展示业界领先的AI研究成果2023-12-08 1341
-
美日联手研究生成式AI,将建立合作框架2024-04-18 1676
全部0条评论

快来发表一下你的评论吧 !
