

大模型在代码缺陷检测领域的应用实践
描述
作者 | 小新、车厘子
导读
静态代码扫描(SA)能快速识别代码缺陷,如空指针访问、数组越界等,以较高ROI保障质量及提升交付效率。当前扫描能力主要依赖人工经验生成规则,泛化能力弱且迭代滞后,导致漏出。本文提出基于代码知识图谱解决给机器学什么的问题,以及基于代码大模型解决机器怎么学的问题,让计算机像人一样看懂代码,并自动发现代码中的缺陷,给出提示,以期达到更小的人力成本,更好的效果泛化和更高的问题召回。
01代码缺陷检测背景介绍
静态代码扫描(SA)指在软件工程中,程序员写好源代码后,在不运行计算机程序的条件下,对程序进行分析检查。通过在代码测试之前,在编码阶段就介入SA,提前发现并修复代码问题,有效减少测试时间,提高研发效率,发现BUG越晚,修复的成本越大。
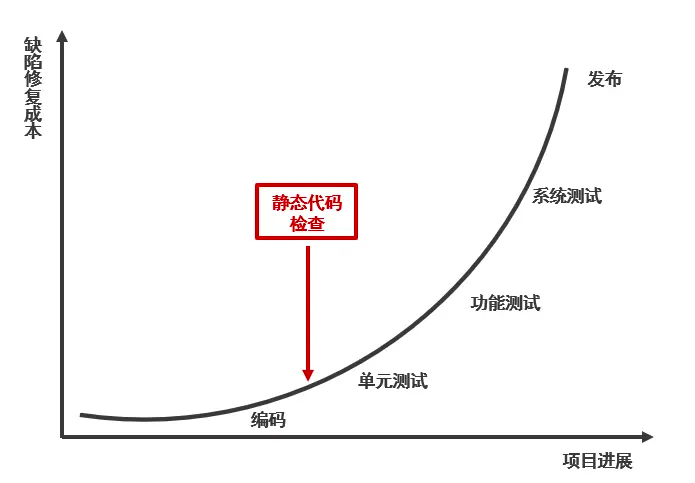
MEG的SA能力于2018年建立,支持C++、GO等语言,建设100+个规则,覆盖大部分MEG的模块,一定程度保障线上质量。当前检测主要依赖人工生成规则,存在人工编写成本高,以及泛化能力弱且迭代滞后,导致问题漏出。2022年Q2,我们团队尝试引入大模型:通过代码语言大模型,实现机器自主检测缺陷,提升泛化能力和迭代效率,减少人工编写规则的成本。接下来,为大家带来相关介绍。
02基于规则的代码缺陷检测主要问题
随着缺陷规则增多,覆盖的语言和模块增多,有两个突出的痛点急需解决:
1、每种规则都需人工根据经验和后续的漏出分析维护,成本较高;以空指针场景为例,人工编写的规则代码共4439行,维护的回归case共227个,但Q2仍有3个bug漏出。我们如何引入大模型减少开发成本,提质增效?
2、有效率偏低,扫描的能力有限(如断链、框架保证非空、复杂场景静态很难识别等,且风险的接受不同,扫描的部分高风险问题存在修复意愿低,对用户造成打扰。我们如何通过模型,从历史误报中学习经验,进行过滤,减少打扰,提升召回?
03解决方案
为了解决2个痛点问题,提出对应的解决方案。
3.1 基于大模型的缺陷自动扫描
如何让计算机像人一样看懂代码,并自动发现代码中的缺陷,给出提示。要让计算机自主进行缺陷检测,核心需要解决2个技术难题:
【学什么】给计算机输入什么内容,能让计算机更快、更好的学习;主要依托代码知识图谱提取目标变量相关的片段,减少机器学习需要的样本量,提升学习的准确性。
【怎么学】针对输入的内容,采用什么算法,能让机器像人一样读懂多种程序语言,并完成检测任务;采用深度学习的方法,主要包含预训练和微调两部分。预训练技术让计算机在海量无标签的样本中学习到多种语言的通用代码语义,本项目主要采用开源的预训练大模型。微调技术通过给大模型输入缺陷检测的样本,从而得到适配场景的大模型,让机器自主的进行缺陷识别。
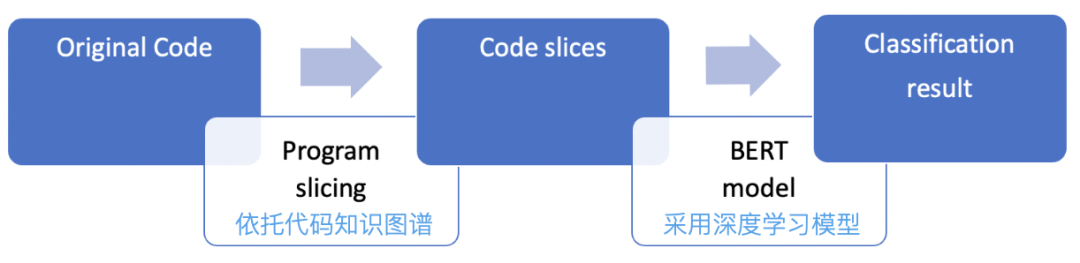
3.1.1 代码知识图谱提取片段
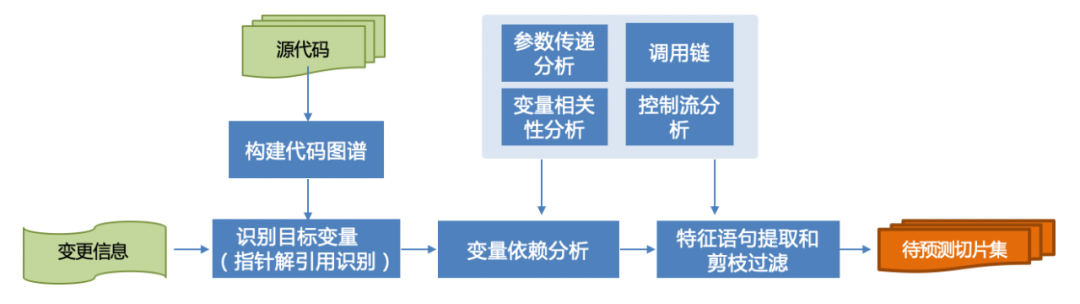
为了平衡模型性能和资源,不同大模型允许输入的token量级不同,如Bert模型限制512个token,因此,需要对输入进行缩减。代码知识图谱是基于程序分析手段,对业务源代码经过模糊或精准的词法分析、语法分析和语义分析后,结合依赖分析、关系挖掘等手段,构建得到的软件白盒代码知识网。图谱提供了多种数据访问方式,用户可以低成本的访问代码数据。
借助于代码知识图谱能力,可以根据不同场景制定不同的与目标变量或目标场景相关的上下文源码获取能力,提取的关键步骤包括:
构建被分析代码的知识图谱
目标变量检测识别:在变更代码中识别目标变量,作为待检测变量
变量依赖分析:基于控制流和数据流的与目标变量相关的依赖变量分析
特征语句提取和剪枝
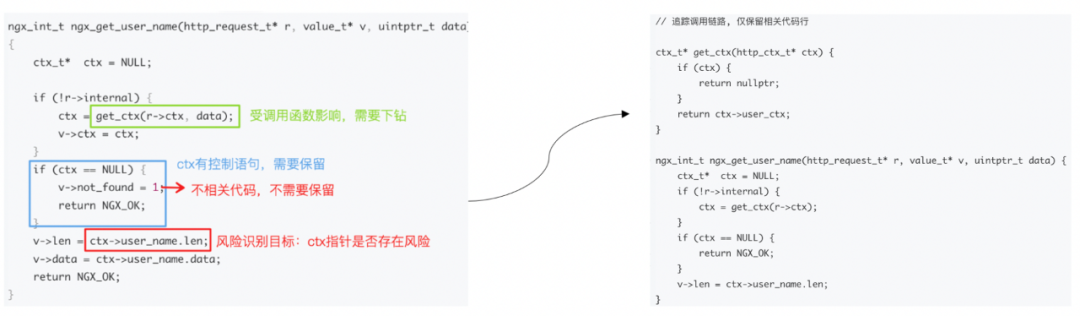
以空指针风险检测为例,最终得到如下样例的代码切片信息:
3.1.2 采用大模型学习算法进行缺陷预测
大模型检测缺陷有两种思路:
1、一种是通过判别式的方法,识别是否有缺陷以及缺陷类型;
2、一种是通过生成式的方法,构建prompt,让程序自动扫描所有相关缺陷。
本项目主要采用判别式的方法,并在实践中证明该方法具有一定可行性。生成式的方法同步实验中,接下来分别介绍两种思路的一些实践。
3.1.2.1 判别式的方法
通过分类的思想,基于模型,从历史的样本中学习规律,从而预测新样本的类别。深度学习众多算法中,如TextCNN、LSTM等,应该采用哪一种?我们通过多组对比实验,最终选择效果最佳的BERT代码大模型。
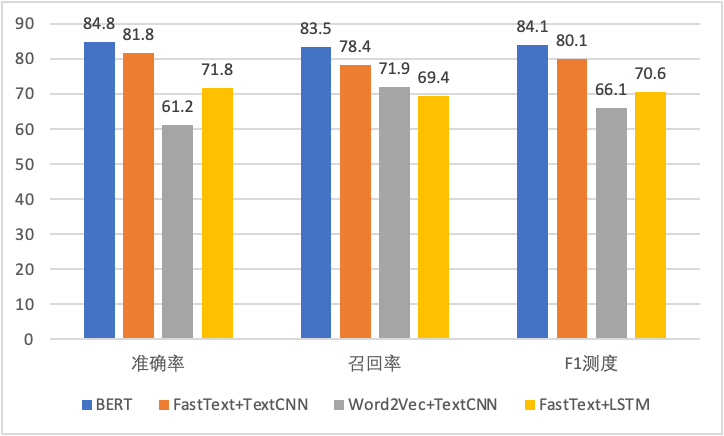
△模型效果
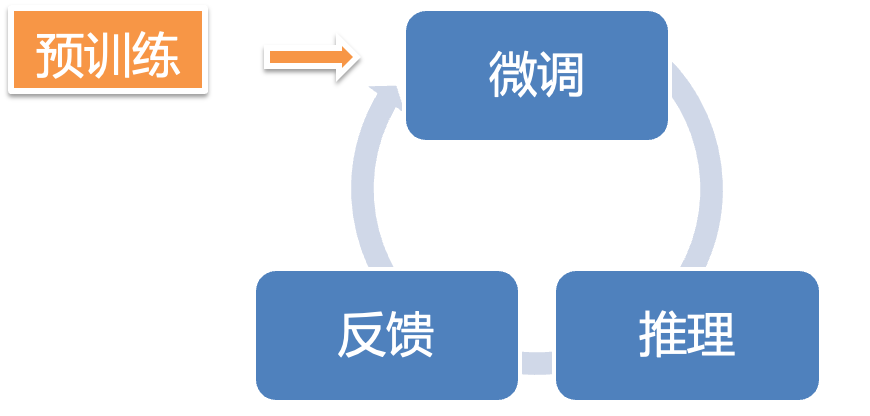
采用BERT进行缺陷检测共含3步,分别是预训练、微调和推理。
预训练阶段采用开源的多语言大模型,已较好的学习多种程序语言的语义。
微调阶段,给模型输入上述通过代码知识图谱提取的变量使用点相关的切片,以及是否有缺陷或者缺陷类型的标签,生成微调模型,让机器具备做检测任务的能力。输入的格式:
{
"slices": [{"line":"行代码内容", "loc": "行号"}],
"mark": {"label":"样本标签", "module_name":"代码库名", "commit_id":"代码版本", "file_path":"文件名", "risk_happend_line":"发生异常的行"}
}
推理阶段,分析使用点目标变量的相关切片,通过微调模型进行预测,得到使用点是否有缺陷,以及缺陷类型
模型上线后,用户对结果反馈状态包括误报和接受,采集真实反馈样本,加入微调模型自动训练,从而到达自动迭代、快速学习新知识的目的。
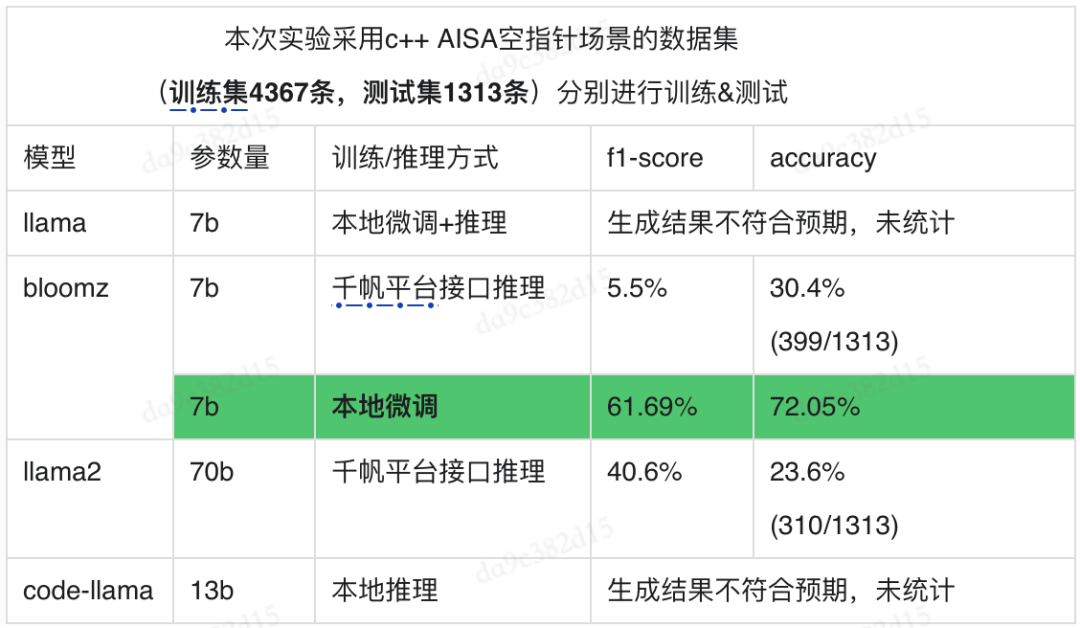
3.1.2.2 生成式的方法
生成式模型百花齐发,有闭源的如chatgpt、文心一言,有开源的如llama、bloom和starcode等。我们主要尝试文心一言、llama和bloom,通过prompt(few shot、引入思维链、指定抽象的引导规则)和微调的方式,探索模型在空指针缺陷检测的预测效果。整体f1测度不高,最佳的bloom61.69%,相比Bert路线的80%有差距,且模型的稳定性较差。因生成式路线有自身的优势,如参数量大存在智能涌现具有更强的推理能力,允许输入的token量不断增加可减少对切片清洗的依赖,可与修复一起结合等,我们预判在缺陷检测场景生成式是个趋势,接下来我们将继续优化,不断尝试prompt和微调,通过更合适的引导,更好的激发模型的潜力,从而提升生成式方法在检测场景的效果。
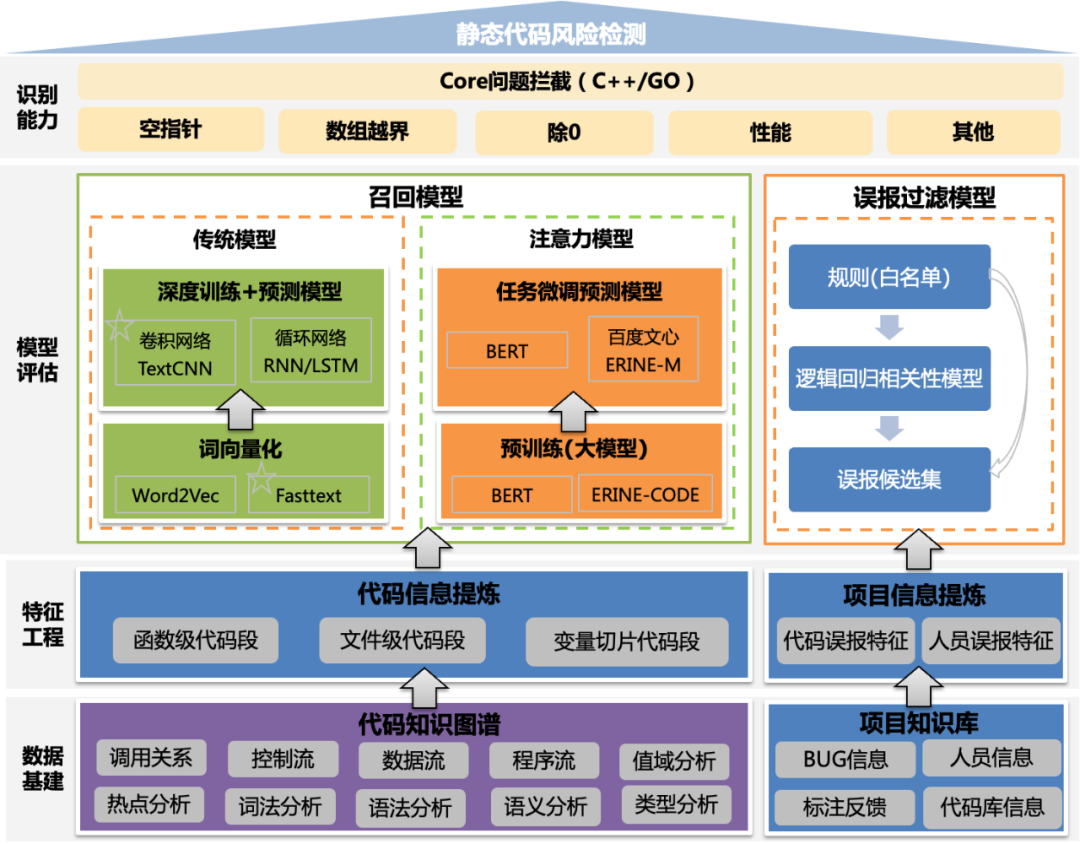
3.2 采用规则+机器学习进行误报过滤
缺陷检测场景识别的缺陷是风险,存在接受度问题,如何过滤掉其中低风险问题,是个难题。通过分析误报和修复的样本,我们采集误报相关的特征,如指针类型,模块误报率、文件误报率等跟误报相关的10+特征,训练机器学习模型(逻辑回归),判断是否需要过滤.
整体方案架构图如下:
04业务落地
基于AI的代码缺陷检测能力可以集成进入code管理平台,每次代码提交,展示可能存在的代码缺陷,阻塞合入,并采集研发人员的反馈,便于模型迭代。
05收益和展望
5.1 收益
通过理论和实践证明,让计算机自主学习程序语言并完成缺陷检测任务具有一定可行性。
1、本项目的方法已在IEEE AITest Conference 2023发表论文:
2、实际落地效果:2023Q2 C++空指针场景已覆盖1100+模块,修复问题数662个,相比规则型静态代码扫描召回占比26.9%,增量召回484个,重合度26.8%,初步证明AI的召回能力,打开了大模型做代码缺陷检测的大门,同时也验证大模型具备传统规则的扩召回、低成本的优势,可形成标记+训练+检测的自闭环。
5.2 展望
基于5.1收益,给了我们用大模型做代码缺陷检测的信心,后续我们继续在以下几个方面加强:
1、扩展更多语言和场景,如除零、死循环、数组越界场景,并在多语言go、java等进行快速训练,并进行发布;
2、随着生成式模型的兴起,也会逐渐积累有效的问题和修复数据,贡献文心通用大模型,进行预训练和微调,以探索生成式模型在智能缺陷检测与修复领域的应用;
3、同时将调研更多基础切片技术,拿到更多丰富有效代码切片,以提升准召率。
审核编辑:汤梓红
-
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》2024-04-30 1335
-
【大语言模型:原理与工程实践】大语言模型的评测2024-05-07 1934
-
缺陷检测在工业生产中的应用2015-11-18 3966
-
[转]产品表面缺陷检测2020-08-07 2456
-
labview深度学习应用于缺陷检测2020-08-16 2988
-
机器视觉检测系统在薄膜表面缺陷检测的应用2020-10-30 2386
-
芯片缺陷检测2021-07-23 1654
-
表面检测市场案例,SMT缺陷检测2022-11-08 1596
-
基于改进万有引力优化的LSSVM模型在标签缺陷检测中的应用2016-12-28 671
-
基于无人机图像的两阶段销钉缺陷检测模型2021-07-05 1152
-
表面缺陷检测系统的应用领域有哪些2021-09-16 1536
-
魔方大模型在智能汽车领域的应用实践与探索2023-08-30 2879
-
瑞萨电子深度学习算法在缺陷检测领域的应用2023-09-22 2224
-
深度学习在工业缺陷检测中的应用2023-10-24 4802
-
描绘未知:数据缺乏场景的缺陷检测方案2024-01-25 1511
全部0条评论

快来发表一下你的评论吧 !
