

基于LLaMA的多语言数学推理大模型
人工智能
描述
写在前面
今天给大家带来一篇《多语言SFT可以显著提高LLM数学推理能力》,来自知乎@promise
Paper: https://arxiv.org/abs/2310.20246 Github: https://github.com/microsoft/MathOctopus/tree/main 知乎:https://zhuanlan.zhihu.com/p/664504560
近来,不少研究工作都集中于如何通过instruction tuning的方式来提高大模型(LLMs)的复杂数学推理能力。但是,这些基于的LLMs研究基本都集中于单语言,如何训练一个多语言数学推理大模型依然丞待解决。
因此,在这篇论文中研究者们基于LLaMA探索并构建了一系列的多语言数学推理大模型:MathOctopus。MathOctopus不仅可以广泛地提高LLMs在多语言上推理的平均性能,而且与单语训练的模型相比在其对应的语言测试中依然可以取得更加优越的表现。
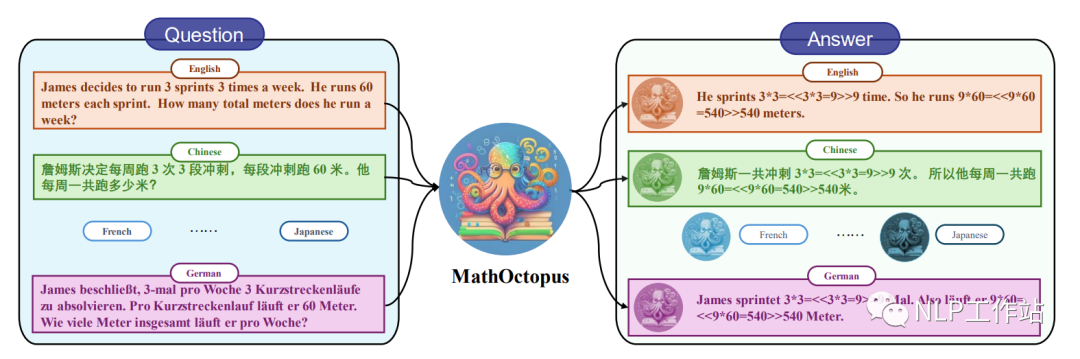
主要贡献如下:
为了解决当前多语言数学推理任务上训练数据短缺的问题,本文将英文的GSM8K数据集翻译成10种不同的语言,并使用了特定的规则来校对翻译后的语料,以确保数据的质量。最终生成的数据用来构建多语言数学推理训练数据集:MGSM8KInstruct。
基于MGSM8KInstruct数据集, 并结合不同的SFT策略和多语言拒绝采样的训练方法,本文构建了一系列有效地多语言数学推理大模型:MathOctopus。
更近一步,为了全面地验证当前模型在多语言数学推理任务上的鲁棒性和通用性,文章基于SVAMP构建了out-of-domain(OOD)的多语言测试数据集MSVAMP。
经过大量的实验,本文总结出以下结论:
MathOctopus在多语言数学推理任务中,表现出了强大的性能。MathOctopus-7B 可以将LLmMA2-7B在MGSM不同语言上的平均表现从22.6%提升到40.0%。更进一步,MathOctopus-13B也获得了比ChatGPT更好的性能。
与只在单语言上训练的LLMs相比,MathOctopus在他们对应的训练语言测试中也取得了更加卓越的效果。比如,MathOctopus-7B和,在英语GSM8K上训练的LLaMA2-7B相比,准确率从42.3%提升到了50.8%。
尽管拒绝采样方法之前在单语数学推理中证明是十分有效的方法,但是在多语言数学推理任务中,使用拒绝采样进行数据增强,对MathOctopus带来的增益相对有限。
数据收集
MGSM8KInstruct训练集
在多语言数学推理任务中,面临的问题是在low-resource语言中缺乏相应高质量的训练数据集,为此,本文使用ChatGPT将英文的GSM8K数据集翻译成多种语言,其中包括孟加拉语(Bn),中文(Zh),法语(Fr),德语(de),日语(Ja),俄语(Ru),西班牙语(Es),斯瓦希里语(Sw)和泰语(Th),并对翻译后的语料进行校对,确保数据的质量。基于此,构建了MGSM8KInstruct多语言数学推理训练数据集。
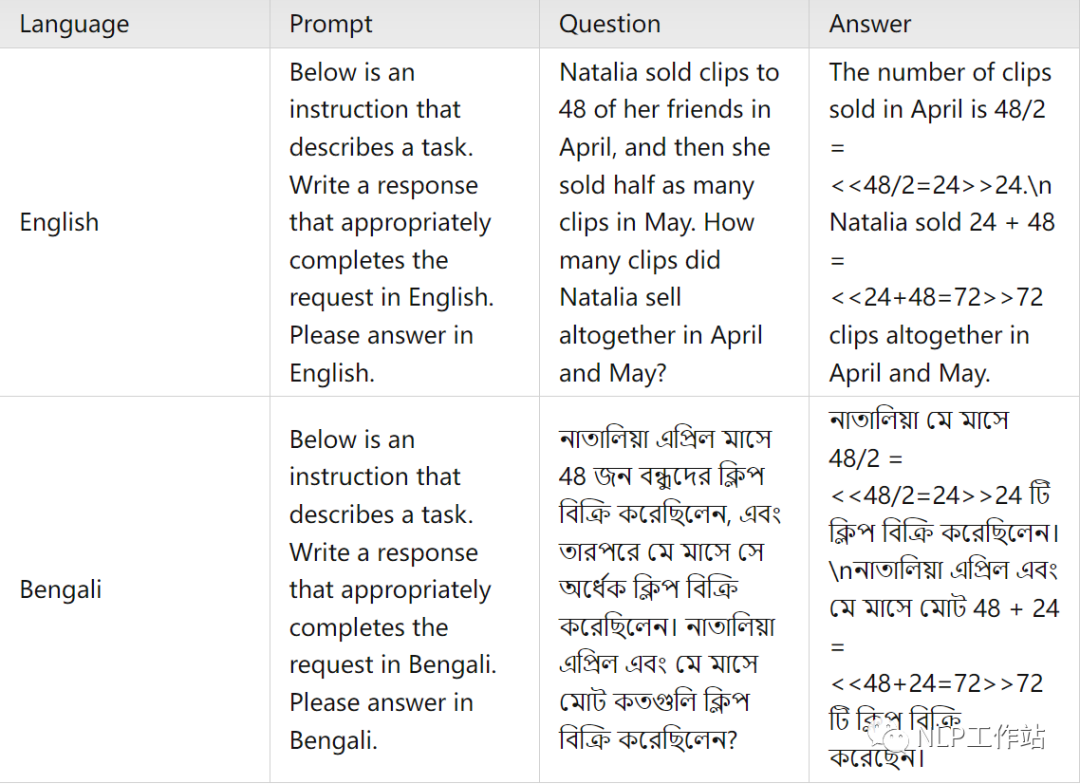
平行训练语料样例
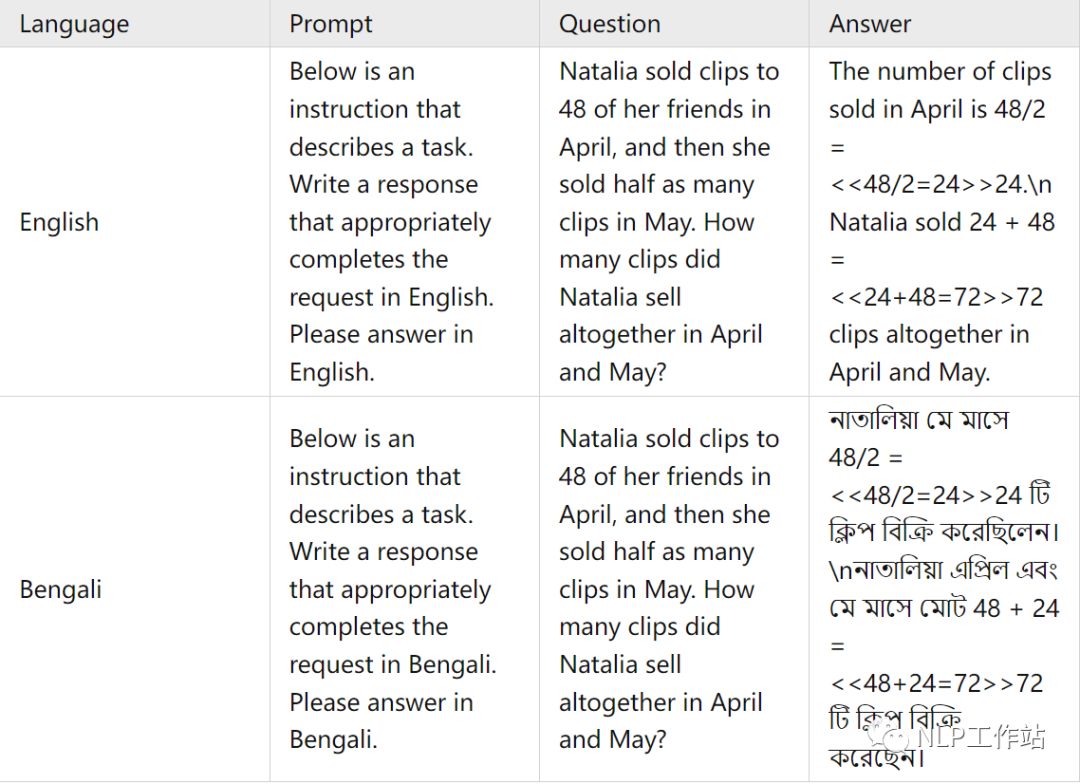
交叉训练语料样例
翻译
在这篇文章中,使用了ChatGPT将英文的GSM8K训练集和他们对应的 chain-of-thought(COT)回答翻译成了十种语言。为了保证翻译的质量,本文在翻译时使用的提示词(prompt)中遵循以下规则:
翻译前后人物和地点的名字保持一致。
翻译前后数学公式保持不变。
所有的数字都用阿拉伯数字表示。
对于每种语言,在提示词(prompt)中提供了两个翻译的例子。
下面是完整的翻译提示词

校对
在翻译问题与答案后,ChatGPT生成的句子通常没有语言翻译错误,但存在数学公式在翻译前后不一致的情况。为了确保翻译前后的准确性,本文采取了以下做法,首先,提取翻译后答案中的所有数学公式,然后与原英文数据集中的公式进行比较,如果它们匹配,就认为翻译是准确的。如果某一数据连续五次出现翻译错误,将删除该数据。这样做有助于确保翻译的准确性。
MSVAMP测试集
为了更近一步测试当前LLMs在多语言数学推理任务上的鲁棒性,本文在现有的SVAMP数据集的基础上构建了out-of-domain(OOD)多语言数学推理测试集MSVAMP。
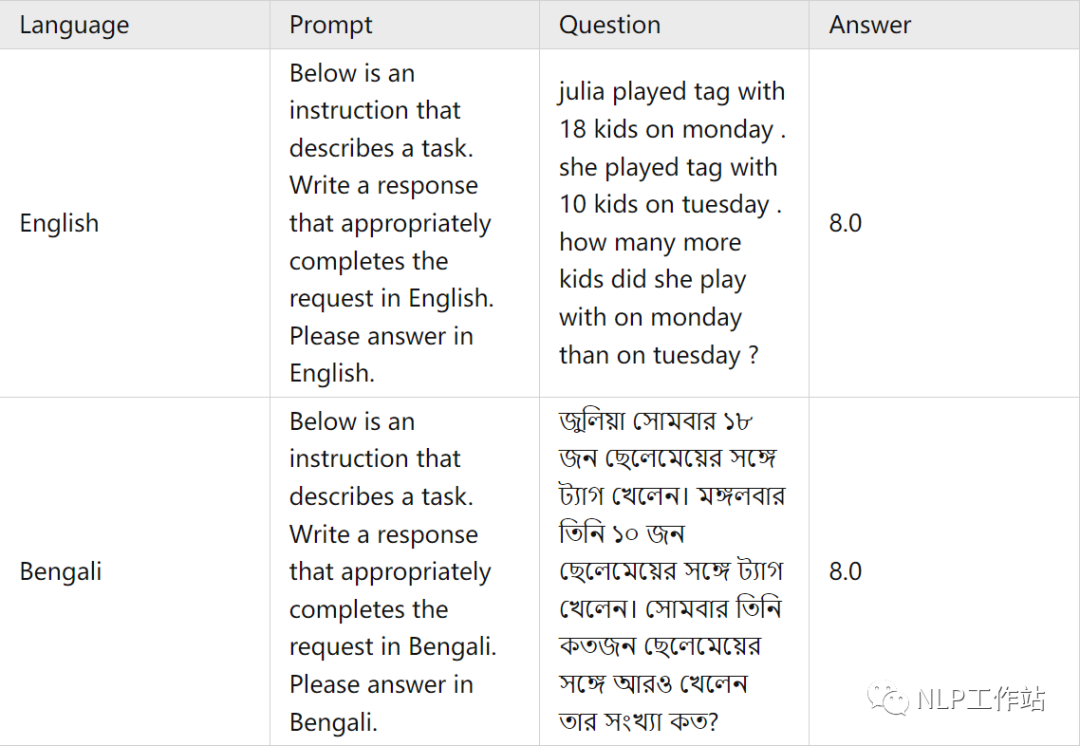
测试集语料样例
翻译
由于这个数据集的答案只包含最终的数字答案而不包括chain-of-thought(COT)过程,所以我们使用google翻译系统仅对问题进行翻译,本文将SVAMP测试集中1000条数据翻译成和训练集中对应的语言。
校对
为了确保翻译的质量:首先,翻译后的句子再次被翻译回英文,以检查是否存在翻译上的差异。此外,还有三名专业的人员对翻译前后的意思是否一致进行了审查,进一步确保翻译的准确性。
MathOctopus
本文基于MGSM8KInstruct,为了让模型拥有更多样化的能力,本文提出了两种不同的训练方式。
为了使模型更好地理解问题与答案,本文提出的第一种方法是parallel-training,即问题与回答是相同的语言。
为了帮助模型融汇贯通不同的语言,本文提出的第二种方法是cross-training,即问题是英语,回答是别的语言,这可以使模型更好地解决多语言问题。
实验结果与分析
下图是模型在MGSM测试集上的表现,MathOctopusP 和 MathOctopusC 指的是模型训练方式分别为parallel-training和cross-training,xRFT 指的是多语言数学推理的拒绝采样,LLaMA 指的是只在英语GSM8K上训练,RFT 指的是在英语GSM8K上训练后,进行拒绝采样。
下图是模型在MGSM测试集上的表现
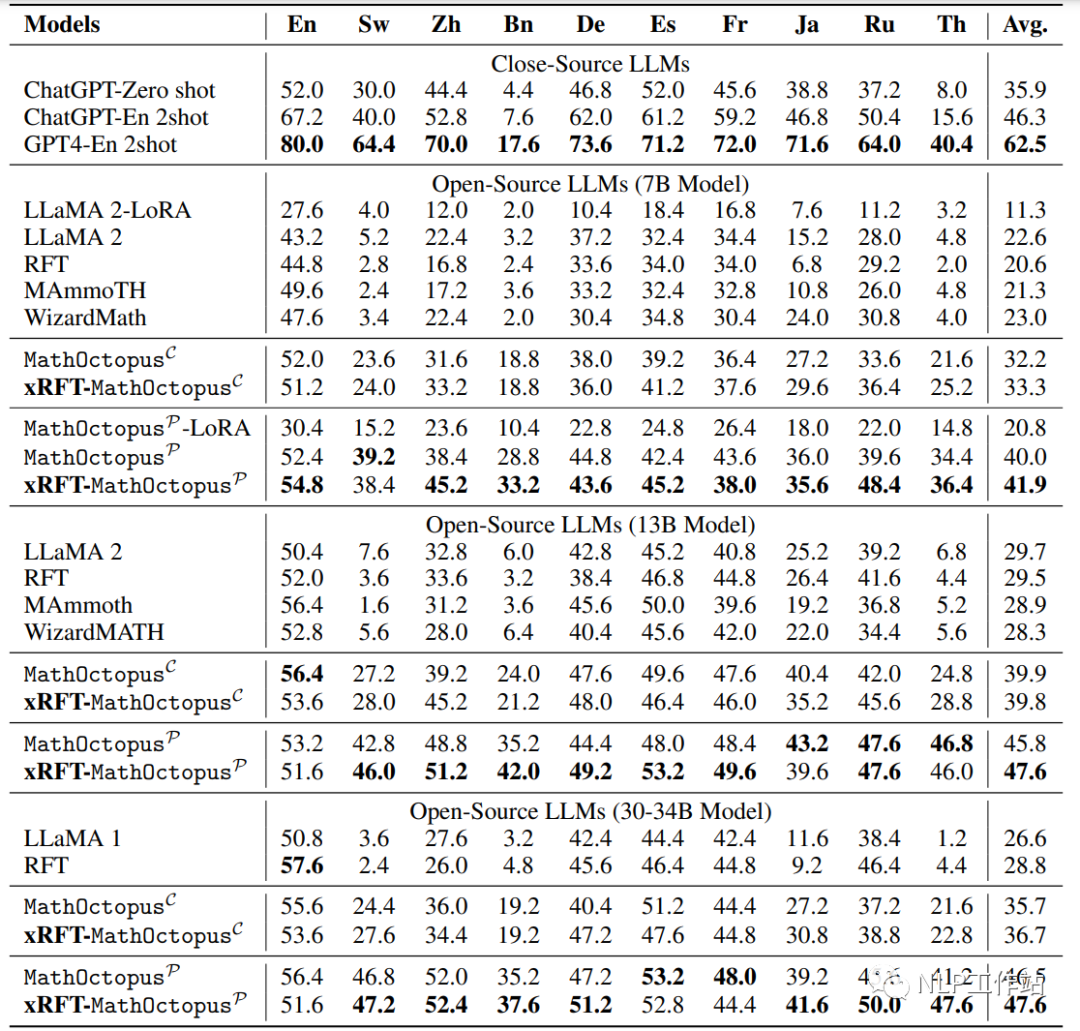
下图是模型在MSVAMP测试集上的表现
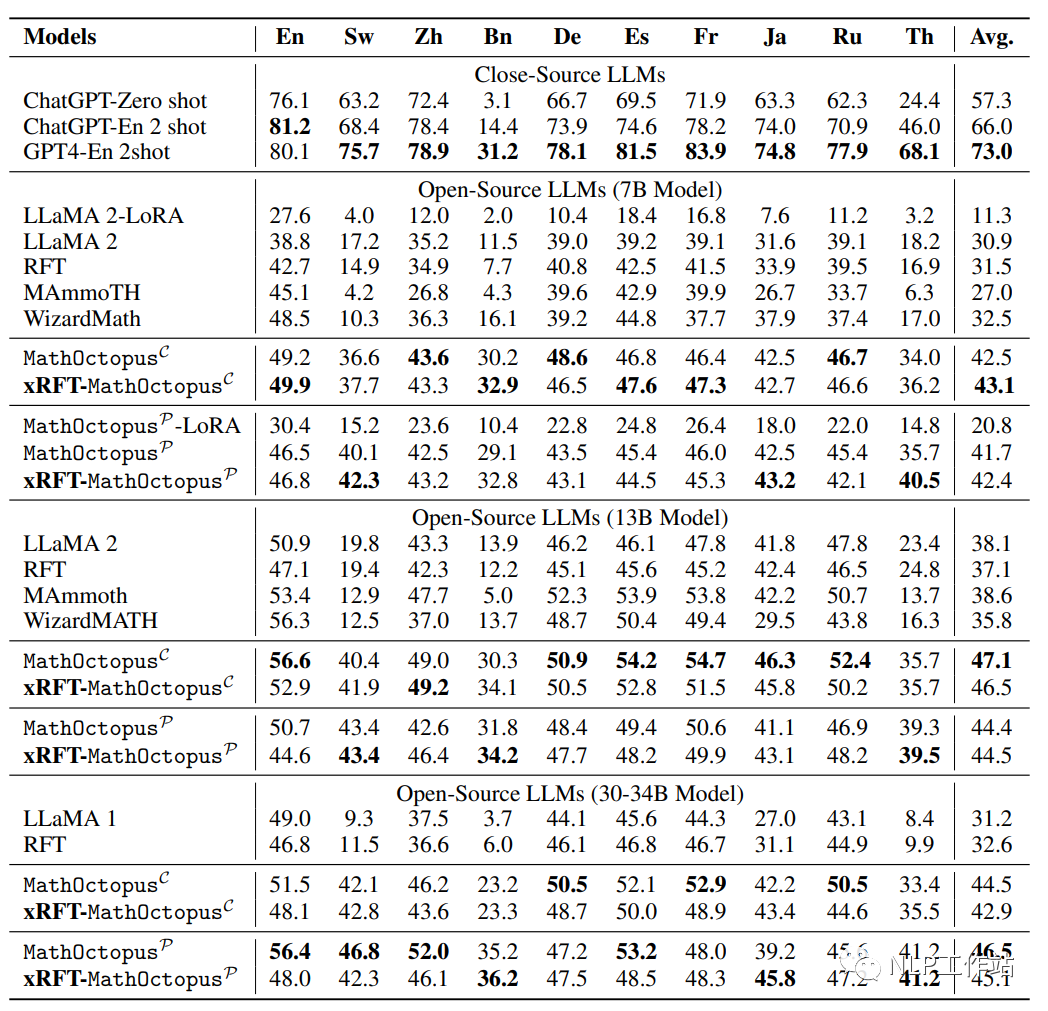
根据实验结果,本文有以下发现:
MathOctopus不论是在平行训练语料还是交叉训练语料上训练的结果都远超于其他开源的LLMs。例如,在7B模型上,MathOctopus在MGSM上的准确率从22.6%提升到41.9%,MathOctopusP-13B在MGSM上的准确率超过了ChatGPT。
MathOctopusP在in-domain测试集MGSM中表现效果更好,相反MathOctopusC在out-of-domain测试集MSVAMP中体现了更强的泛化能力。
多语言拒绝采样在多语言数学推理任务中,对MathOctopus带来的提升有限。
下图展示了在GSM8K训练集上训练的LLaMA2和用MGSM8KInstruct训练的MathOctopus在GSM8K测试集和SVAMP上的表现
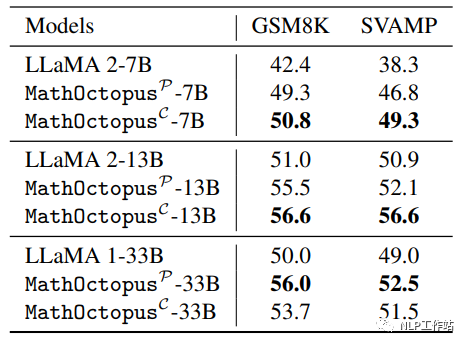
本文发现,和只在单语言上训练的LLMs相比,MathOctopus在英语数据测试中也取得了更好的效果。为了进一步探索在其他语言上是否有相同的现象,本文进行了以下实验:
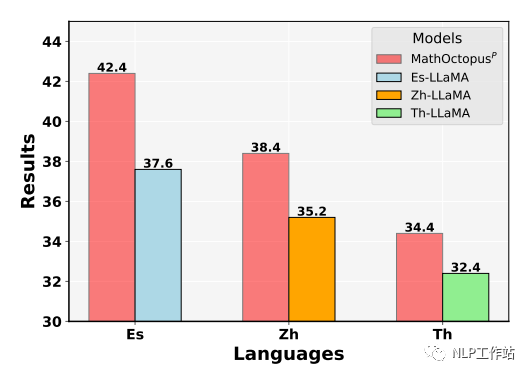
随机从训练集中挑选三种语言,分别是西班牙语,中文,泰语。使用它们对应的训练语料分别训练三个模型,分别命名为 ES-LLaMA,CN-LLaMA,Th-LLaMA。下图展示了这几个模型在他们对应训练语言下的测试结果。由图可见,在单一语言上,MathOctopus的表现仍然超过了单语SFT模型的结果。这表明,在数学推理任务中,多语言训练比单语言训练有更好的效果。
多语言拒绝采样
《Scaling relationship on learning mathematical reasoning with large language models》表明,拒绝采样rejection sampling(RFT)可以大幅提升模型的表现。为了探究在多语言训练的场景下拒绝采样对模型的提升效果,本文在得到多语言SFT模型后,采样模型在MGSM8KInstruct数据集上的推理结果,对采样到的推理过程进行验证,如果符合要求则将其并入到原本的数据集。具体做法如下:
为了采样到多样化的推理答案,本文从MathOctopus-7B和MathOctopus-13B中分别采样25条推理路径,即每种语言总共采样50次。
为了确保推理路径的准确性,本文提取推理路径中的所有公式并对公式进行验算,如果答案正确那么就认为推理路径是正确的。
为了确保推理路径的多样化,本文采用的策略是,只有当前推理路径和先前的路径中没有相同的公式时,才将此路径放入数据集中。
下图展示了不同的采样次数下,每种语言生成的不同推理路径的个数
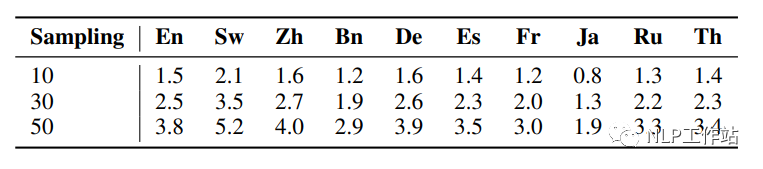
本文发现,通过多语言拒绝采样(xRFT)增加的数据对模型的提升效果有限,主要表现在以下几点:
在MGSM测试集上,多语言拒绝采样只能提升MathOctopusP模型1%-2%的效果。
在MSVAMP测试集上,多语言拒绝采样的提升效果不到1%。
多语言拒绝采样对MathOctopusC的提升效果更小,在MGSM数据集上的表现反而有所下降。
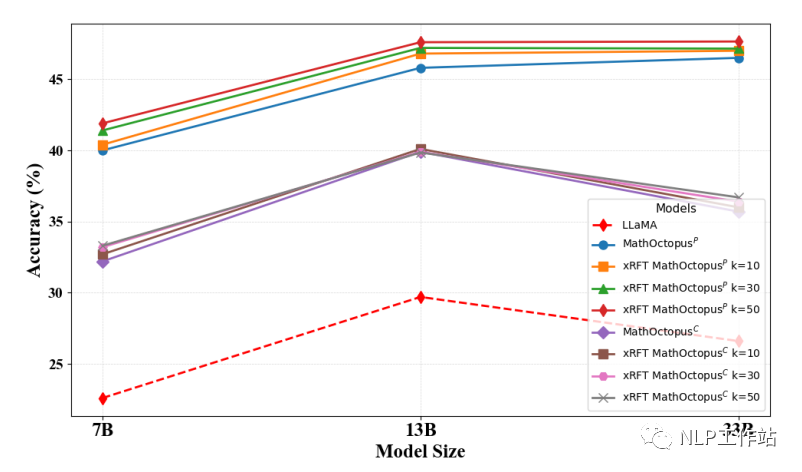
为了探究xRFT生成的数据量对模型的影响,本文在三个不同的采样次数(10,30,50)下分别探究对应的模型在测试集上的表现。
下图是不同采样次数下模型在MGSM数据集上的表现
下图是不同采样次数下模型在MSVAMP数据集上的表现
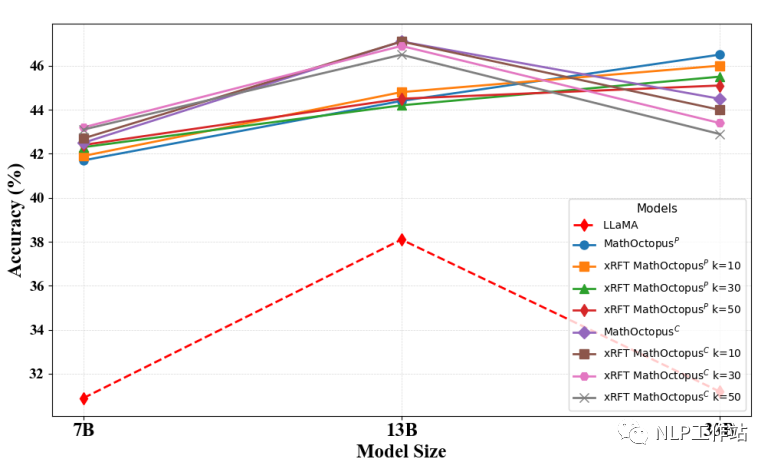
可以发现,在MGSM测试集上,当拒绝采样的次数越多,训练语料越多时,MathOctopusP的表现也略微变好。与之相反,在MSVAMP数据集上,当拒绝采样的次数越多,训练语料越多时,MathOctopusC的表现反而有所下降。
总结
目前仅研究到33B模型,将来还可以在LLaMA2-70B的基础上探索更大的MathOctopus模型,除此之外,在这些更大的模型上使用多语言拒绝采样也是将来的研究点之一。由于MathOctopus只有十种训练语言,更多的训练语言是否会给模型带来更好的效果仍然有待研究。
编辑:黄飞
-
多语言开发的流程详解2023-11-30 2141
-
这个多语言包 怎么搜不到2024-03-24 5939
-
串口屏能否支持全球多语言功能?2019-03-27 1908
-
HarmonyOS低代码开发-多语言支持及屏幕适配2023-05-23 3239
-
多语言综合信息服务系统研究与设计2009-04-01 507
-
华硕 M3A78-EH主板多语言版说明书2010-02-03 419
-
SoC多语言协同验证平台技术研究2015-12-31 1060
-
Multilingual多语言预训练语言模型的套路2022-05-05 4311
-
蚂蚁集团开源高性能多语言序列化框架Fury解读2023-08-25 2490
-
如何在TSMaster面板和工具箱中实现多语言切换2023-11-11 2703
-
大语言模型(LLMs)如何处理多语言输入问题2024-03-07 1611
-
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型2024-10-12 2570
-
ChatGPT 的多语言支持特点2024-10-25 2599
-
Llama 3 语言模型应用2024-10-27 1481
-
京东多语言质量解决方案2026-01-13 1290
全部0条评论

快来发表一下你的评论吧 !
