

自动驾驶公开数据集的现状与挑战
汽车电子
描述
随着数据采集设备的优化升级,自动驾驶数据集也在不断升级迭代。国内外各大自动驾驶公司、研究所都先后推出自动驾驶数据集,为未来自动驾驶领域的技术发展提供重要研究材料。 《自动驾驶开源数据体系:现状与未来》一文系统性地梳理自动驾驶开源数据集,对于助推产业生态良性循环有着重要意义。该文章是由上海人工智能实验室联合上海交大、复旦大学、百度、比亚迪、蔚来等多个单位,发布的自动驾驶开源数据集综述。该综述首次系统性梳理了国内外七十余种开源自动驾驶数据集,对如何构建高质量数据集、数据在算法闭环体系中发挥的核心作用、如何利用生成式大模型规模化生产数据等进行了总结。在此基础上,对未来第三代自动驾驶数据集所应具有的特征、数据规模、需要解决的关键科学和技术问题展开深入分析与讨论。
概述
自动驾驶作为人工智能重要应用领域之一,有望重塑现有的交通和运输模式,极大提升交通效率和安全性,对未来城市和社会发展产生深远影响。目前,国内的智能网联汽车产业已经迈入商业化的试水和起步阶段。道路测试和示范应用场景趋于成熟,自动驾驶功能技术加速迭代,车联网应用场景日益丰富,各层面相关法规政策加速出台,共同推动市场进入高速发展期。 一方面,自动驾驶技术需要大量数据来训练算法模型,以识别和理解道路环境,从而做出正确的决策和行动,实现准确、稳定和安全的驾驶体验,数据的建设对于自动驾驶技术的发展至关重要。另一方面,自然语言处理和通用视觉领域大模型的出现,更加印证了海量高质量数据的重要性,给予自动驾驶的数据集建设以启发! 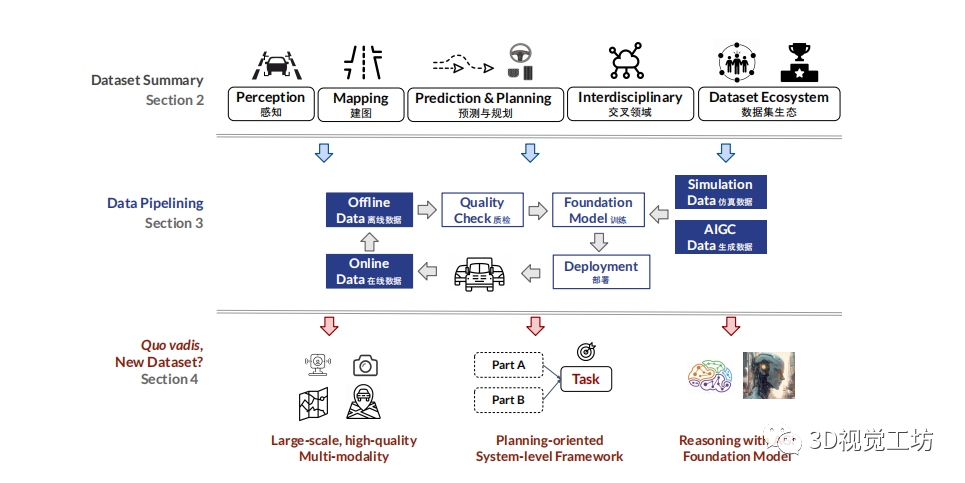 综述文章架构
综述文章架构
自动驾驶数据集
该综述把目前开源的近百种数据集分为两代:第一代数据集以 KITTI 为标志,该数据集于2012年提出,输入传感模态由单目摄像头与激光雷达构成,并提出了一系列综合感知任务。第二代数据集以 nuScenes 及 Waymo 数据集为代表,传感模态复杂度变高,环视相机、激光雷达、定位信息以及高精地图成为常见组成部分,下游任务面向感知、建图、预测与路径规划综合任务。
传感器模态复杂度逐渐提高:环视相机,激光雷达,高精地图,超声波雷达传感器,GPS、IMU、HD Map等。
数据集规模与多样性日益增长:在数据丰富度方面,主流自动驾驶数据集的采集时长由最初的10小时左右逐渐提升至100小时,随着自动标注技术及标注工具的演进,近些年也出现了超过 1000 小时的数据集。驾驶场景的多样性也是自动驾驶系统表现的另一关键因素。为了提高算法在特定场景下的表现能力,部分数据集分别在多个大洲多个城市进行采集。
数据集任务从感知延伸至预测与规划:2016 年推出的 Cityscapes 与 Mapillary 等数据集下游任务聚焦于动态物体检测。2019 年推出的 SemanticKITTI 、DrivingStereo等数据集引入语义分割、深度估计、光流估计等任务。在传统预测与规划模块一般应用数值计算、优化、搜索等方法求解。2019 年前后提出的 nuScenes、Waymo 、Argoverse V2 等数据集,不仅包括感知任务还涵盖预测与规划任务,实现了在同一数据集上进行多种任务研究,同时引领社区在传统多个模块范式下端到端自动驾驶研究的潮流。 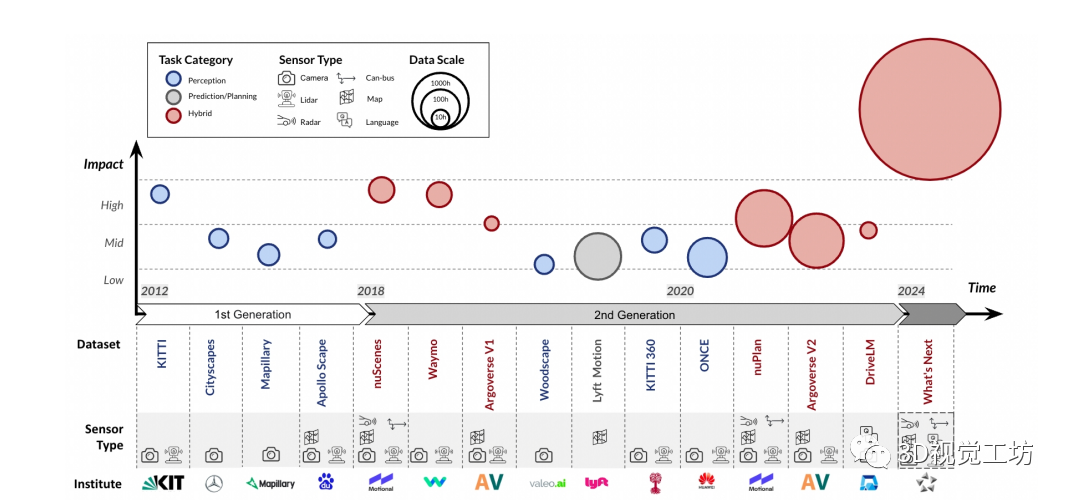 自动驾驶开源数据集影响力估计
自动驾驶开源数据集影响力估计
数据算法闭环体系
模块化自动驾驶系统包括感知、决策、规划、控制等组件,其中大部分功能是通过数据驱动的神经网络模型实现的。对于这些模块来说,海量和高质量的数据是确保模块性能的必要条件。 首先,海量数据的引入对于解决现存自动驾驶系统中的各种问题都很有必要。自动驾驶工程中一直存在的问题是长尾问题。其产生原因在于训练模型的数据量不足而导致存在少量情况未被模型学习,而在模型推理阶段,模型并不能对这些边缘场景给出正确的结果。另外,对于基于规则的模块,现有的方式是通过人工设计各种规则来使模块输出符合人为设计逻辑的结果。这个方法耗时耗力,并且难以覆盖所有情况,有可能导致自动驾驶系统在某些未见场景下失效。而使用数据驱动的神经网络代替这些模块是一个可能的解决方案。 同时,在神经网络学习过程中,数据噪声的引入会不可避免地对优化过程产生负面影响,并降低模型性能。数据质量不仅包括传感器数据的分辨率和同步性等,还包括标签的准确性。在这两个方面中,任意一个方面存在质量问题都直接影响着自动驾驶系统的性能和安全性。 综上,海量和高质量的数据成为构建自动驾驶系统必不可少的一个环节。
大模型时代下的新一代自动驾驶数据集
当前基础大模型在自然语言处理、计算机视觉等领域取得了举世瞩目的成果,但目前市面上还没有面向自动驾驶垂直领域的大模型。以其他领域的大模型作为参照,新一代数据集至少应将数据量提升至与其他领域相近才能够赋能自动驾驶大模型。 在保证数据数量的前提下,场景丰富度对算法性能更为重要。自动驾驶车辆在真实世界中会不可避免地遇到训练数据之外的场景大规模地应用自动驾驶技术必然要求模型能够在罕见场景中做出正确行为,避免发生危险或功能失效的情况。对于绝大多数交通场景来说,并不需要十分大量的数据就能够覆盖,而更需要关注的是长尾场景,由于某些交通场景十分罕见,如撞车等,数据的缺失会对自动驾驶系统的性能影响巨大。
第一、二代自动驾驶数据集已经不能够继续满足自动驾驶系统的发展需求,新一代数据集的建设亟待提上日程。在大模型时代,大数据成为新一代数据集不可缺少的一个特点。同时,模块化设计的自动驾驶系统在落地过程遇到迭代成本高、性能上界受限等问题,端到端自动驾驶架构逐步受到业界的青睐。除此之外,多模态传感器、高质量标注、模型逻辑推理能力等方面也需要得到重视。基于此,该综述总结归纳了新一代数据集的发展目标:面向多模态、保质保量;面向端到端、决策导向;面向智能化、逻辑推理。
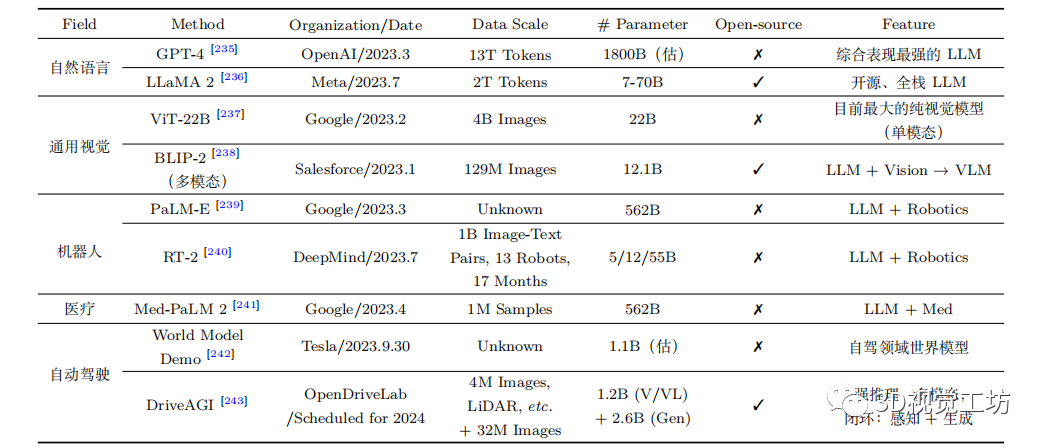 大模型时代下的自动驾驶数据集展望
大模型时代下的自动驾驶数据集展望
结论
该综述全面回顾了自动驾驶公开数据集的现状与挑战。针对数据算法闭环体系,结合当前大模型发展趋势,提出了下一代自动驾驶数据集的愿景与规划。该综述系统性地总结了自动驾驶发展历程中所使用的数据集,并展示了通过挑战赛与榜单促进社区发展的重要性;概括性地分析了自动驾驶数据算法闭环体系,并总结其中各个重要环节的作用,最后通过应用案例展现对数据算法闭环体系的使用方法。
编辑:黄飞
-
自动驾驶领域的数据集汇总2024-01-19 1891
-
语音数据集在自动驾驶中的应用与挑战2023-12-25 1422
-
自动驾驶公开数据集的现状与挑战2023-11-09 1795
-
最全自动驾驶数据集分享系列一:目标检测数据集2023-06-06 870
-
自动驾驶OS市场的现状及未来 精选资料推荐2021-07-27 2544
-
自动驾驶车辆中AI面临的挑战2021-02-22 2694
-
自动驾驶AI芯片现状分析2020-12-04 2812
-
自动驾驶系统要完成哪些计算机视觉任务?2020-07-30 2270
-
Waymo公开无人驾驶汽车数据集2020-03-20 4625
-
自动驾驶汽车的处理能力怎么样?2019-08-07 2930
-
Waymo公开大型自动驾驶数据集 传感器同步效果增强2019-06-19 5193
-
如何让自动驾驶更加安全?2019-05-13 3788
-
自动驾驶的到来2017-06-08 7479
-
自动驾驶真的会来吗?2016-07-21 14605
全部0条评论

快来发表一下你的评论吧 !
