

Linux内核中的各种锁介绍
描述
首先得搞清楚,不同锁的作用对象不同。
下面分别是作用于临界区、CPU、内存、cache 的各种锁的归纳:
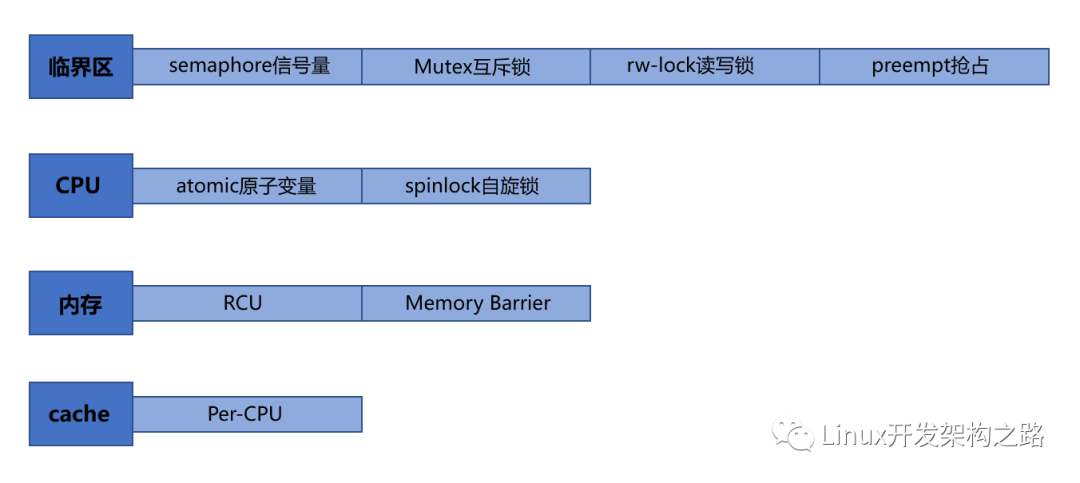
一、atomic原子变量/spinlock自旋锁 — —CPU
既然是锁CPU,那就都是针对多核处理器或多CPU处理器。单核的话,只有发生中断会使任务被抢占,那么可以进入临界区之前先关中断,但是对多核CPU光关中断就不够了,因为对当前CPU关了中断只能使得当前CPU不会运行其它要进入临界区的程序,但其它CPU还是可能执行进入临界区的程序。
原子变量:
在x86多核环境下,多核竞争数据总线的时候,提供Lock指令锁住总线,保证“读-修改-写”操作在芯片级的原子性。这个好说,我们一般对某个被多线程会访问的变量设置为atomic类型的即可,比如atomic_int x;或atomic x;
自旋锁:
当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取。使用实例如下:
#include < linux/spinlock.h >
// 定义自旋锁
spinlock_t my_lock;
void my_function(void)
{
spin_lock(&my_lock);
// 访问共享资源的操作
spin_unlock(&my_lock);
}
互斥锁中,要是当前线程没拿到锁,就会出让CPU;而自旋锁中,要是当前线程没有拿到锁,当前线程在CPU上忙等待直到锁可用,这是为了保证响应速度更快。但是这种线程多了,那意味着多个CPU核都在忙等待,使得系统性能下降。
因此一定不能自旋太久,所以用户态编程里用自旋锁保护临界区的话,这个临界区一定要尽可能小,锁的粒度得尽可能小。
为什么自旋锁的响应速度会比互斥锁更快?
自旋锁是通过 CPU 提供的 CAS 函数(Compare And Swap), =在「 用户态 」完成加锁和解锁操作= **,不会主动产生线程上下文切换,所以相比互斥锁来说,会快一些,开销也小一些。**
而互斥锁则不是,前面说互斥锁加锁失败,线程会出让CPU,这个过程其实是由内核来完成线程切换的,因此加锁失败时,1)首先从用户态切换至内核态,内核会把线程的状态从「运行」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运行;2)当互斥锁可用时,之前「睡眠」状态的线程会变为「就绪」状态(要进入就绪队列了),之后内核会在合适的时间,把 CPU 切换给该线程运行。
然后返回用户态。
这个过程中,不仅有用户态到内核态的切换开销,还有两次线程上下文切换的开销。
线程的上下文切换主要是线程栈、寄存器、线程局部变量等。
而自旋锁在当前线程获取锁失败时不会进行线程的切换,而是一直循环等待直到获取锁成功。因此,自旋锁不会切换至内核态,也没有线程切换开销。
所以如果这个锁被占有的时间很短,或者说各个线程对临界区是快进快出,那么用自旋锁是开销最小的!
自旋锁的缺点前面也说了,就是如果自旋久了或者自旋的线程数量多了,CPU的利用率就下降了,因为上面执行的每个线程都在忙等待— —占用了CPU但什么事都没做。
二、信号量/互斥锁 — —临界区
信号量:
信号量(信号灯)本质是一个计数器,是描述临界区中可用资源数目的计数器。
信号量为3,表示可用资源为3。加入初始信号量为3,某时刻信号量为1,说明可用资源数为1,那么有2个进程/线程在使用资源或者说有两个资源被消耗了(具体资源是什么得看具体情况)。进程对信号量有PV操作,P操作就是进入共享资源区前-1,V操作就是离开共享资源后+1(这个时候信号量就表明还可以允许多少个进程进入该临界区)。
信号量进行多线程通信编程的时候,往往初始化信号量为0,然后用两个函数做线程间同步:
sem_wait():等待信号量,如果信号量的值大于0,将信号量的值减1,立即返回。如果信号量的值为0,则线程阻塞。
sem_post():释放资源,信号量+1 ,相当于unlock,这样执行了sem_wait()的线程就不阻塞了。
要注意:信号量本身也是个共享资源,它的++操作(释放资源)和--操作(获取资源)也需要保护。其实就是用的自旋锁保护的。如果有中断的话,会把中断保存到eflags寄存器,待操作完成,就去该寄存器上读取,然后执行中断。
struct semaphore {
spinlock_t lock; // 自旋锁
unsigned int count;
struct list_head wait_list;
};
互斥锁:
信号量的话表示可用资源的数量,是允许多个进程/线程在临界区的。但是互斥锁不是,它的目的就是只让一个线程进入临界区,其余线程没拿到锁,就只能阻塞等待。线程互斥的进入临界区,这就是互斥锁名字由来。
另外提一下std::timed_mutex睡眠锁,它和互斥锁的区别是:
互斥锁中,没拿到锁的线程就一直阻塞等待,而睡眠锁则是设置一定的睡眠时间比如2s,线程睡眠2s,如果过了之后还没拿到锁,那就放弃拿锁(可以输出获取锁失败),如果拿到了,那就继续做事。比如 用成员函数try_lock_for()
std::timed_mutex g_mutex;
//先睡2s再去抢锁
if(g_mutex.try_lock_for(std::chrono::seconds(2)))){
// do something
}
else{
// 没抢到
std::cout< < "获取锁失败";
}
三、读写锁/抢占 — —临界区
读写锁:
用于读操作比写操作更频繁的场景,让读和写分开加锁,这样可以减小锁的粒度,提高程序的性能。
它允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这可以提高并发性能,因为读操作通常比写操作频繁得多。读写锁这种就属于高阶锁了,它的实现就可以用自旋锁。
抢占:
抢占必须涉及进程上下文的切换,而中断则是涉及中断上下文的切换。
内核从2.6开始就支持内核抢占,之前的内核不支持抢占,只要进程在占用CPU且时间片没用完,除非有中断,否则它就能一直占用CPU;
抢占的情况:
比如某个优先级高的任务(进程),因为需要等待资源,就主动让出CPU(又或者因为中断被打断了),然后低优先级的任务先占用CPU,当资源到了,内核就让该优先级高的任务抢占那个正在CPU上跑的任务。也就是说,当前的优先级低的进程跑着跑着,时间片没用完,也没发生中断,但是自己被踢掉了。
为了支持内核抢占,内核引入了preempt_count字段,该计数初始值为0,每当使用锁时+1,释放锁时-1。当preempt_count为0时,表示内核可以安全的抢占,大于0时,则禁止内核抢占
Per-CPU— —作用于cache
per-cpu变量用于解决各个CPU里L2 cache和内存间的数据不一致性。
四、RCU机制/内存屏障 — —内存
RCU机制是read copy update,即读 复制 更新。
和读写锁一样,RCU机制也是允许多个读者同时读,但更新数据的时候,需要先复制一份副本,在副本上完成修改,然后再一次性地替换旧数据。
比如链表里修改某个节点的数据,先拷贝该节点出来,修改里面的值,然后把节点前的指针指向拷贝出的节点
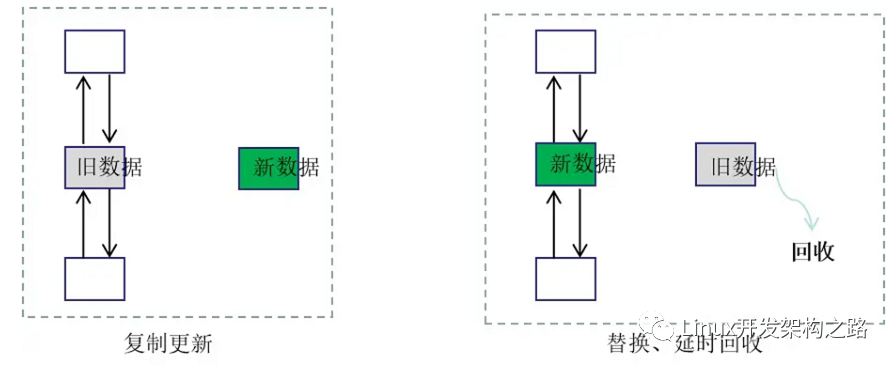
等到旧数据没有人要读的时,就把该内存回收。
所以RCU机制的核心有两个:1)复制后更新;2)延迟回收内存
有RCU机制的话,读写就不需要做同步,也不会发生读写竞争了,因为读者是对原来的数据进行读,而写者是对拷贝出来的那份内存进行修改,读写可以并行。
他们的读写是根据内存的指针来进行的,写者写完之后,就把旧读者的指针赋值为新的数据的指针,指针的赋值操作是原子的,这样新的读者将访问新数据。
旧内存由一个线程专门负责回收。
内存屏障:
内存屏障则是用于控制内存访问顺序,确保指令的执行顺序符合预期。
因为代码往往不是看我们写的这种顺序被执行的,它有两个层面的乱序:
1)编译器层面的。因为编译器的优化往往会对代码的汇编指令进行重排
2)CPU层面的。多 CPU 间存在内存乱序访问的情况。
内存屏障就是让编译器或CPU对内存的访问有序。
编译时的乱序访问:
int x, y, r;
void f()
{
x = r;
y = 1;
}
开了优化选项后编译,得到的汇编可能是y = 1先执行,再x =r执行。可以用g++ -O2 -S test.cpp生成汇编代码,查看开了-O2优化后的汇编:
我们可以使用内核提供的宏函数barrier()来避免编译器的这种乱序:
#define barrier() __asm__ __volatile__("" ::: "memory")
int x, y, r;
void f()
{
x = r;
__asm__ __volatile__("" ::: "memory");
y = 1;
}
或者将涉及到的相关变量x和y用volatile关键字修饰:
volatile int x, y;
注意,C++里的volatile关键字只能避免编译期的指令重排,对于多CPU的指令重排不起作用,所以实际上代码真正运行的时候,可能又是乱序的。而Java的volatile关键字好像具有编译器、CPU两个层面的内存屏障作用。
多CPU乱序访问内存:
在单 CPU 上,不考虑编译器优化导致乱序的前提下,多线程执行不存在内存乱序访问的问题。因为单个CPU获取指令是有序的(队列FIFO),返回指令执行的结果至寄存器也是有序的(也是通过队列)
但是在多CPU处理器中,因为每个 CPU 都存有 cache,当数据x第一次被一个 CPU 获取时,x显然不在 该CPU 的 cache 中(这就是 cache miss)。cache miss发生那意味着 CPU 需要从内存中获取数据,然后数据x将被加载到 CPU 的 cache 中,这样后续就能直接从 cache 上快速访问。
当某个 CPU 进行写操作时,它必须确保其他的 CPU 已经将数据x从它们的 cache 中移除(以便保证一致性),只有在移除操作完成后此 CPU 才能安全的修改数据。
显然,存在多个 cache 时,我们必须通过 cache 的一致性协议来避免数据不一致的问题,而这个通讯的过程就可能导致乱序访问的出现。
CPU级别的内存屏障有三种:
- 通用 barrier,保证读写操作都有序的,mb() 和 smp_mb() //
mb即memory barrier - 写操作 barrier,仅保证写操作有序的,wmb() 和 smp_wmb()
- 读操作 barrier,仅保证读操作有序的,rmb() 和 smp_rmb()
上述这些函数也是有宏定义的比如mb(),用在上述的编译期间乱序的例子中就是加个mfence:
#define mb() _asm__volatile("mfence":::"memory")
void f()
{
x = 1;
__asm__ __volatile__("mfence" ::: "memory");
r1 = y;
}
// GNU中的内存屏障#define mfence() _asm__volatile_("mfence": : :"memory")
注意,所有的 CPU级别的 Memory Barrier(除了数据依赖 barrier 之外)都隐含了编译器 barrier。
而且,实际上很多线程同步机制,都在底层有内存屏障作为支撑,比如原子锁和自旋锁都是依赖CPU提供的CAS操作实现。CAS即Compare and Swap,它的基本思想是:
在多线程环境下,如果需要修改共享变量的值,先读取该变量的值,然后修改该变量的值,最后将新值与旧值进行比较,如果相同,则修改成功,否则修改失败,需要重新执行该操作。
在实现CAS操作时,需要使用内存屏障来保证操作的顺序和一致性。例如,在Java中,使用Atomic类的compareAndSet方法实现CAS操作时,会自动插入内存屏障来保证操作的正确性。
对于应用层的编程而言,C++11引入了内存模型,它确保了多线程程序中的同步和一致性。内存屏障(CPU级别)就是内存模型的一部分,用于确保特定的内存操作顺序,X86-64下仅支持一种指令重排:Store-Load ,即读操作可能会重排到写操作前面。
内存屏障有两种类型:store和load,使用示例如下:
// store屏障
std::atomic< int > x;
x.store(1, std::memory_order_release); // store屏障确保之前的写操作在之后的写操作之前完成
// load屏障
std::atomic< int > y;
int val = y.load(std::memory_order_acquire); // load屏障确保之前的读操作在之后的读操作之前完成
CPU级别的内存屏障除了保证指令顺序外,还要保证数据的可见性,不可见就会导致数据的不一致性。
所以上述代码中也用到了acquire和release语义分别对读和写设置屏障:
acquire:保证acquire后的读写操作不会发生在acquire动作之前
release:保证release前的读写操作不会发生在release动作之后
除了上面的atomic的load和store,C++11还提供了单独的内存屏障函数std::atomic_thread_fence,其用法和上述的类似:
#include < atomic >
std::atomic_thread_fence(std::memory_order_acquire);
std::atomic_thread_fence(std::memory_order_release);
五、内核中使用这些锁的示例
进程调度:内核锁用于保护调度器的数据结构,以避免多个CPU同时修改它们而导致错误。
// 自旋锁
spin_lock(&rq- >lock);
...
spin_unlock(&rq- >lock);
文件系统:内核锁用于保护文件系统的元数据,如inode、dentry等数据结构,以避免多个进程同时访问它们而导致错误。
spin_lock(&inode- >i_lock);
...
spin_unlock(&inode- >i_lock);
网络协议栈:内核锁用于保护网络协议栈的数据结构,如套接字、路由表等,以避免多个进程同时访问它们而导致错误。
read_lock(&rt_hash_lock);
...
read_unlock(&rt_hash_lock);
内存管理:内核锁用于保护内存管理的数据结构,如页表、内存映射等,以避免多个进程同时访问它们而导致错误
spin_lock(&mm- >page_table_lock);
...
spin_unlock(&mm- >page_table_lock);
-
如何理解Linux内核中的PCIe驱动2026-04-11 1666
-
Linux内核测试技术2024-08-13 2770
-
使用 PREEMPT_RT 在 Ubuntu 中构建实时 Linux 内核2024-04-12 5326
-
Linux内核中RCU的用法2023-12-27 3817
-
Linux读写锁逻辑解析—Linux为何会引入读写锁?2023-12-04 2145
-
linux内核中的driver_register介绍2023-07-14 4909
-
介绍一下Linux内核中的各种锁2023-05-16 6467
-
Linux内核结构介绍2023-04-14 2335
-
Linux中的伤害/等待互斥锁介绍2021-11-06 3685
-
Linux内核同步机制的自旋锁原理是什么?2020-03-31 1303
-
Linux内核中有哪些锁2020-02-24 4146
-
Linux内核开发工具介绍2016-12-29 10029
-
Linux内核同步机制的自旋锁原理2010-06-08 1573
-
Linux内核学习起步课件2009-04-10 826
全部0条评论

快来发表一下你的评论吧 !
