

无锁队列的潜在优势
描述
无锁队列
先大致介绍一下无锁队列。无锁队列的根本是CAS函数——CompareAndSwap,即比较并交换,函数功能可以用C++函数来说明:
{
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
return old_reg_val;
}
它将reg的值与oldval的值进行对比,若相同则将reg赋新值。注意以上操作是原子操作。大部分语言都有提供CAS支持,不过函数原型可能有些微的不同,许多语言(包括go)中CAS的返回值是标识是否赋值成功的bool值。
无锁队列则是以CAS来实现同步的一种队列,我的具体实现这里就不贴出来了,有点冗长,文末给出了源码地址。这里仅仅大致给出实现思路,网上关于无锁队列的资料很多,这里就不详细说了。
{
q = new record();
q->value = x;
q->next = NULL;
p = tail;
oldp = p
do {
while (p->next != NULL)
p = p->next;
} while( CAS(p.next, NULL, q) != TRUE); //如果没有把结点链在尾上,再试
CAS(tail, oldp, q); //置尾结点
}
DeQueue() //出队列
{
do{
p = head;
if (p->next == NULL){
return ERR_EMPTY_QUEUE;
}
while( CAS(head, p, p->next) != TRUE );
return p->next->value;
}
自旋锁
自旋锁是加锁失败时接着循环请求加锁,直到成功。它的特点是不会释放CPU,故也没有互斥锁那种内核态切换操作,但缺点也很明显,就是会一直占用CPU,理论上适用于临界区小、不需要长时间加锁的场景。 这里只贴锁的相关代码,队列的实现就不贴了:
type spinMutex struct {
mutex int32
}
const locked = 1
const unlocked = 0
func (spin *spinMutex) lock() {
for !atomic.CompareAndSwapInt32(&spin.mutex, unlocked, locked) {}
}
func (spin *spinMutex) unlock() {
atomic.SwapInt32(&spin.mutex, unlocked)
}
互斥锁
这个没什么好说的,用的golang自带的互斥锁sync.Mutex。
测试
下面将分2种场景进行测试:分别是高并发和低并发。高并发我用4个协程往队列中push数据,4个协程从队列中pop数据(虽然不是很高,但足以区分性能,就没测太高并发了,毕竟测一次等的太久也累);低并发不好模拟,于是我干脆极端点改为无并发——先顺序写,再顺序读。
无并发
大致测试代码结构如下(删减了不关键的语句):
for i := 1; i <= dataNum; i++ {
suc := queue.PushBack(i)
}
queue.Disable()
for {
val, enable := queue.PopFront()
if !enable {
break
}
}
fmt.Println("用时:", time.Since(t1))
为了方便对比,我特地还增加了不加锁的队列的测试结果。测试结果如下:(左侧为dataNum数据量)
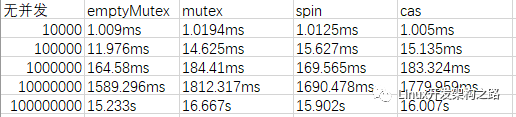
添加图片注释,不超过 140 字(可选)
可以看到数据量小的时候性能差别还不明显,甚至cas还有少许的优势。但数据量一大就很明显的看出自旋锁的效率会高一点,cas次之。不过它们差别都不大。
高并发
这里用4个生产者4个消费者共用一个队列来模拟高并发。测试代码结构如下:
wgr := sync.WaitGroup{}
wgw := sync.WaitGroup{}
t1 := time.Now()
for i := 0; i < 4; i++ {
wgr.Add(1)
go reader(i*1000000, &wgr)
}
for i := 0; i < 4; i++ {
wgw.Add(1)
go writter(&wgw)
}
wgr.Wait()
queue.Disable()
wgw.Wait()
fmt.Println("用时:", time.Since(t1))
}
func reader(startNum int, wg *sync.WaitGroup) {
for i := 0; i < dataNum; i++ {
suc := queue.PushBack(startNum + i)
for !suc {
suc = queue.PushBack(startNum + i)
}
}
wg.Done()
}
func writter(wg *sync.WaitGroup) {
for {
r, enable := queue.PopFront()
if enable == false {
break
}
if r == defaultVal {
continue
}
}
wg.Done()
}
这种情况下就没法测试无锁队列了,数据都不完整(已验证)。测试结果如下,左侧为读/写协程数*dataNum数据量(下面读/写协程数为4指总共开了8个协程):

添加图片注释,不超过 140 字(可选)
可以看到cas有巨大的性能优势,甚至达到了3到5倍的性能差距,说明这个思路还是可行的!(先开始被chan打击到了)反倒是自旋锁的性能最差,这个倒有些出乎我的意料,按照我的理解在这种频繁加锁解锁的情况下自旋锁的性能应该更好才对,若有知情人士望告知。
分析
为了对这几种锁的性能特点有更深入的分析,这里还补充了几组测试,分别用了不同的协程数和数据量进行补充测试:

添加图片注释,不超过 140 字(可选)
可以很明显的看到一个趋势——随着并发度增加,自旋锁的性能急剧下降,由无并发时的与cas性能几乎一样到最后与cas将近7倍的效率差。而mutex和cas情况下,随着并发度增加,性能影响并不大,下面将前面的测试数据重新组织一下方便对比:

添加图片注释,不超过 140 字(可选)
可以看到总数据量不变的情况下,并发协程数对mutex和cas的影响非常小,基本在波动范围以内。相较之下自旋锁就比较惨了。
总结
**根据上面的结果来说的话,当实际竞争特别小的时候,可以考虑用自旋锁;而并发大的时候,用无锁队列这种结构有很大潜在优势。**之所以说潜在的是因为我也仅仅是简单的实现某种结构,肯定有考虑不全的地方,我写这个无锁例子主要用于测试,也没打算用于实际场景中。但是我尽量保证了同样的代码结构下,最大化各个锁结构对性能的影响。总的来说,本文测试结果仅作参考,希望能有抛砖引玉的效果。
最后,再附上源码地址:https://github.com/HandsomeRosin/lockfree
更新:
针对自旋锁效率低下的问题我仔细想了想,应该是原子操作cas耗时的问题(毕竟在无并发情况下,cas和真正不加锁还是有很大的性能差距)。于是对自旋锁的代码进行了微调,减少了CAS的调用次数:(被注释掉的是原本的代码逻辑)
// for !atomic.CompareAndSwapInt32(&spin.mutex, unlocked, locked) {}
BEGINING:
for spin.mutex != unlocked {}
if !atomic.CompareAndSwapInt32(&spin.mutex, unlocked, locked) {
goto BEGINING
}
}
事实证明,这样做效率确实提高了约1/4,不过还是改变不了它的大趋势(与cas和mutex的性能差距依旧巨大),所以就没更新前面的测试数据了。
不过这也佐证了CAS也是比较耗时的一个操作,平时还是不能肆意使用。
-
使用USB进行测量应用的优势和潜在危险2009-05-11 510
-
AWorks软件设计,邮箱、消息队列和自旋锁使用方法2018-06-13 13615
-
利用CAS技术实现无锁队列2021-01-11 3273
-
关于CAS等原子操作介绍 无锁队列的链表实现方法2022-05-18 4418
-
怎么设计实现一个无锁高并发的环形连续内存缓冲队列2023-02-15 2652
-
RTOS消息队列的应用2023-05-29 1241
-
发烧友实测 | i.MX8MP 编译DPDK源码实现rte_ring无锁环队列进程间通信2022-01-10 3835
-
固态电池(SSBs)的潜在优势2023-09-25 1610
-
如何实现一个多读多写的线程安全的无锁队列2023-11-08 2737
-
无锁队列解决的问题2023-11-10 2128
全部0条评论

快来发表一下你的评论吧 !
