

异步IO框架iouring介绍
描述
前言
Linux内核5.1支持了新的异步IO框架iouring,由Block IO大神也即Fio作者Jens Axboe开发,意在提供一套公用的网络和磁盘异步IO,不过io_uring目前在磁盘方面要比网络方面更加成熟。
目录
- 背景简介
- io_uring
- 系统API
- liburing
- 高级特性
- 编程示例
- 性能对比
- 模式对比
- 线上应用
背景简介
熟悉Linux系统编程的同学都清楚,Linux并没有提供完善的异步IO(网络IO、磁盘IO)机制。
在网络编程中,我们通常使用epoll IO多路复用来处理网络IO,然而epoll也并不是异步网络IO,仅仅是内核提供了IO复用机制,epoll回调通知的是数据可以读取或者写入了,具体的读写操作仍然需要用户去做,而不是内核代替完成。
在存储IO栈中,做存储的同学大都使用过libaio,然而那是一个巨难用啊Linux AIO这个奇葩。首先只能在DIO下使用,用不了pagecache;其次用户的数据地址空间起始地址和大小必须页大小对齐;然后在submit_io时仍然可能因为文件系统、pagecache、sync发生阻塞,除此之外,我们在使用libaio的时候会设置io_depth的大小,还可能因为内核的/sys/block/sda/queue/nr_requests(128)设置的过小而发生阻塞;而且libaio提供的sync命令关键还不起作用,想要sync数据还得依赖fsync/fdatasync,真的是心塞塞,libaio想说爱你不容易啊。
所以Linux迫切需要一个完善的异步机制。同时在Linux平台上跑的大多数程序都是专用程序,并不需要内核的大多数功能,而且这几年也流行kernel bypass,intel也发起的用户态IO DPDK、SPDK。但是这些用户态IO API不统一,使用成本过高,所以内核便推出了io_uring来统一网络和磁盘的异步IO,提供一套统一完善的异步API,也支持异步、轮询、无锁、zero copy。真的是姗姗来迟啊,不过也算是在高性能IO方面也算是是扳回了一城。
io_uring
io_uring的设计目标是提供一个统一、易用、可扩展、功能丰富、高效的网络和磁盘系统接口。其高性能依赖于以下几个方面:
- 用户态和内核态共享提交队列(submission queue)和完成队列(completion queue)。
- 用户态支持Polling模式,不依赖硬件的中断,通过调用IORING_ENTER_GETEVENTS不断轮询收割完成事件。
- 内核态支持Polling模式,IO 提交和收割可以 offload 给 Kernel,且提交和完成不需要经过系统调用(system call)。
- 在DirectIO下可以提前注册用户态内存地址,减小地址映射的开销。
系统API
io_uring提供了3个系统调用API,虽然只有3个,但是直接使用起来还是蛮复杂的。
- io_uring_setup
entries:queue depth,表示队列深度。
io_uring_params:初始化时候的参数。
在io_uring_setup返回的时候就已经初始化好了 SQ 和 CQ,此外,还有内核还提供了一个 Submission Queue Entries(SQEs)数组。
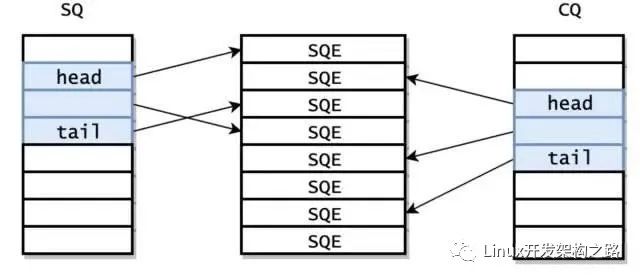
之所以额外采用了一个数组保存 SQEs,是为了方便通过 RingBuffer 提交内存上不连续的请求。SQ 和 CQ 中每个节点保存的都是 SQEs 数组的偏移量,而不是实际的请求,实际的请求只保存在 SQEs 数组中。这样在提交请求时,就可以批量提交一组 SQEs 上不连续的请求。但由于 SQ,CQ,SQEs 是在内核中分配的,所以用户态程序并不能直接访问。io_setup 的返回值是一个 fd,应用程序使用这个 fd 进行 mmap,和 kernel 共享一块内存。这块内存共分为三个区域,分别是 SQ,CQ,SQEs。kernel 返回的 io_sqring_offset 和 io_cqring_offset 分别描述了 SQ 和 CQ 的指针在 mmap 中的 offset。而 SQEs 则直接对应了 mmap 中的 SQEs 区域。mmap 的时候需要传入 MAP_POPULATE 参数,以防止内存被 page fault。
- io_uring_enter
io_uring_enter即可以提交io,也可以来收割完成的IO,一般IO完成时内核会自动将SQE 的索引放入到CQ中,用户可以遍历CQ来处理完成的IO。
IO 提交的做法是找到一个空闲的 SQE,根据请求设置 SQE,并将这个 SQE 的索引放到 SQ 中。SQ 是一个典型的 RingBuffer,有 head,tail 两个成员,如果 head == tail,意味着队列为空。SQE 设置完成后,需要修改 SQ 的 tail,以表示向 RingBuffer 中插入一个请求。
io_uring_enter 被调用后会陷入到内核,内核将 SQ 中的请求提交给 Block 层。to_submit 表示一次提交多少个 IO。
如果 flags 设置了 IORING_ENTER_GETEVENTS,并且 min_complete > 0,那么这个系统调用会同时处理 IO 收割。这个系统调用会一直 block,直到 min_complete 个 IO 已经完成。
这个流程貌似和 libaio 没有什么区别,IO 提交的过程中依然会产生系统调用。
但 io_uring 的精髓在于,提供了 submission offload 模式,使得提交过程完全不需要进行系统调用。
如果在调用 io_uring_setup 时设置了 IORING_SETUP_SQPOLL 的 flag,内核会额外启动一个内核线程,我们称作 SQ 线程。这个内核线程可以运行在某个指定的 core 上(通过 sq_thread_cpu 配置)。这个内核线程会不停的 Poll SQ,除非在一段时间内没有 Poll 到任何请求(通过 sq_thread_idle 配置),才会被挂起。
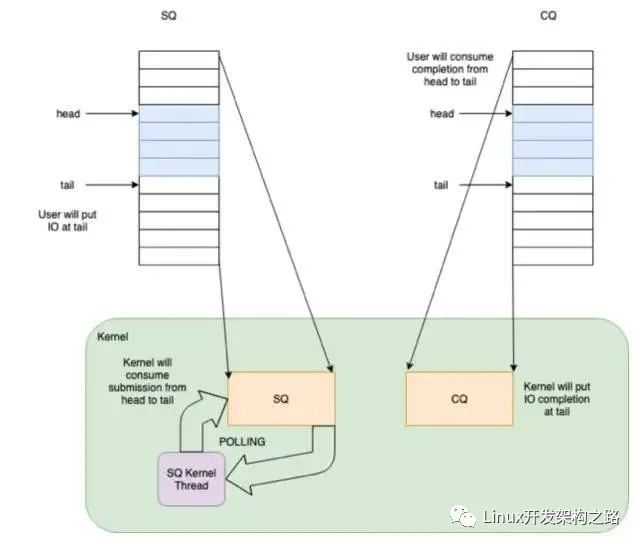
当程序在用户态设置完 SQE,并通过修改 SQ 的 tail 完成一次插入时,如果此时 SQ 线程处于唤醒状态,那么可以立刻捕获到这次提交,这样就避免了用户程序调用 io_uring_enter 这个系统调用。如果 SQ 线程处于休眠状态,则需要通过调用 io_uring_enter,并使用 IORING_SQ_NEED_WAKEUP 参数,来唤醒 SQ 线程。用户态可以通过 sqring 的 flags 变量获取 SQ 线程的状态。
if (IO_URING_READ_ONCE(*ring->sq.kflags) & IORING_SQ_NEED_WAKEUP) {
*flags |= IORING_ENTER_SQ_WAKEUP;
return true;
}
- io_uring_register
主要包含IORING_REGISTER_FILES、IORING_REGISTER_BUFFERS,在高级特性章节会描述。
liburing
我们知道io_uring虽然仅仅提供了3个系统API,但是想要用好还是有一定难度的,所提fio大神本人封装了一个Liburing,简化了io_uring的使用,通过使用liburing,我们很容易写出异步IO程序。
代码位置:github.com/axboe/liburi,在使用的时候目前仍然需要拉取代码,自己编译,估计之后将会融入内核,在用户程序中需要包含#include "liburing.h"。
列举一些比较常用的封装的API:github.com/axboe/liburi
extern int io_uring_queue_init(unsigned entries, struct io_uring *ring, unsigned flags);
// 非系统调用,清理io_uring
extern void io_uring_queue_exit(struct io_uring *ring);
// 非系统调用,获取一个可用的 submit_queue_entry,用来提交IO
extern struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring);
// 非系统调用,准备阶段,和libaio封装的io_prep_writev一样
static inline void io_uring_prep_writev(struct io_uring_sqe *sqe, int fd,const struct iovec *iovecs, unsigned nr_vecs, off_t offset)
// 非系统调用,准备阶段,和libaio封装的io_prep_readv一样
static inline void io_uring_prep_readv(struct io_uring_sqe *sqe, int fd, const struct iovec *iovecs, unsigned nr_vecs, off_t offset)
// 非系统调用,把准备阶段准备的data放进 submit_queue_entry
static inline void io_uring_sqe_set_data(struct io_uring_sqe *sqe, void *data)
// 非系统调用,设置submit_queue_entry的flag
static inline void io_uring_sqe_set_flags(struct io_uring_sqe *sqe, unsigned flags)
// 非系统调用,提交sq的entry,不会阻塞等到其完成,内核在其完成后会自动将sqe的偏移信息加入到cq,在提交时需要加锁
extern int io_uring_submit(struct io_uring *ring);
// 非系统调用,提交sq的entry,阻塞等到其完成,在提交时需要加锁。
extern int io_uring_submit_and_wait(struct io_uring *ring, unsigned wait_nr);
// 非系统调用 宏定义,会遍历cq从head到tail,来处理完成的IO
#define io_uring_for_each_cqe(ring, head, cqe)
// 非系统调用 遍历时,可以获取cqe的data
static inline void *io_uring_cqe_get_data(const struct io_uring_cqe *cqe)
// 非系统调用 遍历完成时,需要调整head往后移nr
static inline void io_uring_cq_advance(struct io_uring *ring, unsigned nr)
高级特性
io_uring里面提供了polling机制:IORING_SETUP_IOPOLL可以让内核采用 Polling 的模式收割 Block 层的请求;IORING_SETUP_SQPOLL可以让内核新起线程轮询提交sq的entry。
IORING_REGISTER_FILES
这个的用途是避免每次 IO 对文件做 fget/fput 操作,当批量 IO 的时候,这组原子操作可以避免掉。
IORING_REGISTER_BUFFERS
如果应用提交到内核的虚拟内存地址是固定的,那么可以提前完成虚拟地址到物理 pages 的映射,避免在 IO 路径上进行转换,从而优化性能。用法是,在 setup io_uring 之后,调用 io_uring_register,传递 IORING_REGISTER_BUFFERS 作为 opcode,参数是一个指向 iovec 的数组,表示这些地址需要 map 到内核。在做 IO 的时候,使用带 FIXED 版本的opcode(IORING_OP_READ_FIXED /IORING_OP_WRITE_FIXED)来操作 IO 即可。
内核在处理 IORING_REGISTER_BUFFERS 时,提前使用 get_user_pages 来获得 userspace 虚拟地址对应的物理 pages。在做 IO 的时候,如果提交的虚拟地址曾经被注册过,那么就免去了虚拟地址到 pages 的转换。
IORING_SETUP_IOPOLL
这个功能让内核采用 Polling 的模式收割 Block 层的请求。当没有使用 SQ 线程时,io_uring_enter 函数会主动的 Poll,以检查提交给 Block 层的请求是否已经完成,而不是挂起,并等待 Block 层完成后再被唤醒。使用 SQ 线程时也是同理。
编程示例
通过liburing使用起来还是比较方便的,不用操心内核的一些事情,简直爽歪歪啊。具体可参考ceph:github.com/ceph/ceph/bl
- io_uring_queue_init 来初始化 io_uring。IORING_SETUP_IOPOLL / IORING_SETUP_SQPOLL。
- io_uring_submit 来提交 IO,在这个函数里面会判断是否需要调用系统调用io_uring_enter。设置了IORING_SETUP_SQPOLL则不需要调用,没有设置则需要用户调用。
- io_uring_for_each_cqe 来收割完成的IO,这是一个for循环宏定义,后面直接跟 {} 就可以。
性能对比
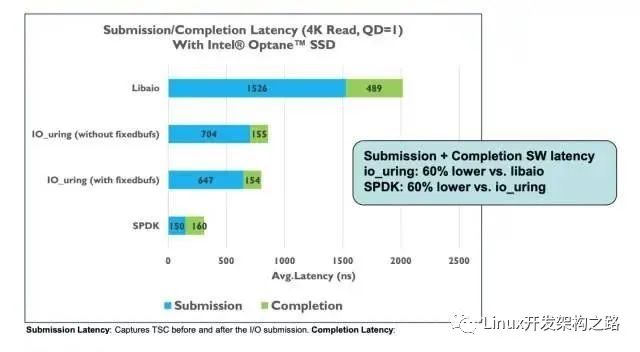
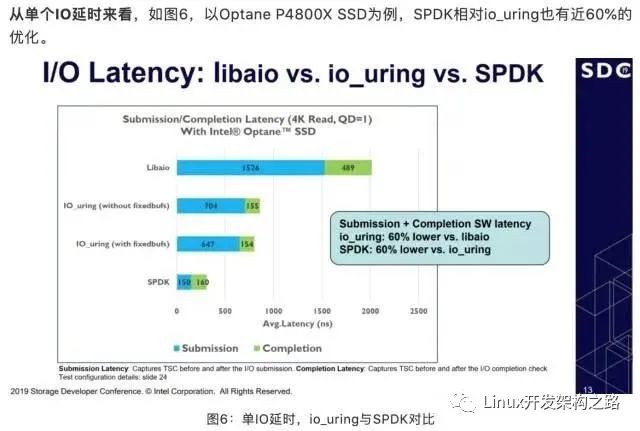
intel团队测试结果
可以看出来intel自己测试的结果表明延迟方面spdk比io_uring要低60%。使用了自己带的perf的测试工具测的。
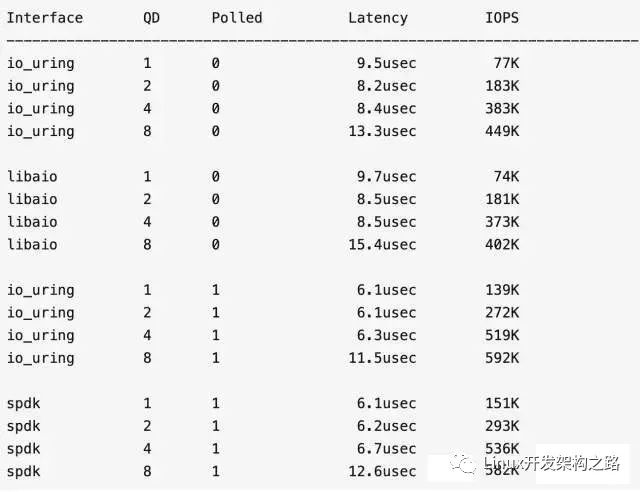
fio作者测试结果
4k randread,3D Xpoint 盘:
io_uring vs libaio,在非 polling 模式下,io_uring 性能提升不到 10%,好像并没有什么了不起的地方。
然而 io_uring 提供了 polling 模式。在 polling 模式下,io_uring 和 SPDK 的性能非常接近,特别是高 QueueDepth 下,io_uring 有赶超的架势,同时完爆 libaio。
模式对比
| 项目 | io_uring | spdk |
|---|---|---|
| 驱动程序 | 内核态驱动程序有锁 | 用户态驱动程序、无锁、轮询、线程绑定 |
| run_to_completion | 非rtc模型,可能会有上下文切换? | rtc模型,单线程撸到底 |
| 内存管理 | mmu、4k | 2MB大页 |
| 提交任务有无锁 | 无锁 | 无锁 |
| 系统调用 | 可有可无 | 无系统调用 |
| 用户内核态切换 | 轻量级的 | 无内核切换 |
| poll模型 | 可选 | polling |
线上应用
目前发现已经有几个项目在做尝试性的应用:rocksdb、ceph、spdk、第三方适配(nginx、redis、echo_server)
rocksdb
rocksdb官方实现了PosixRandomAccessFile::MultiRead()使用io_uring。
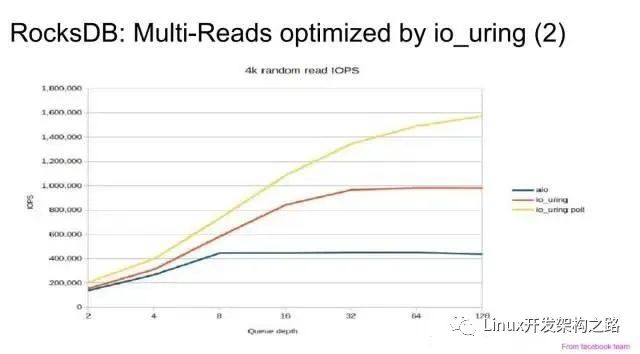
除此之外,tikv扩展了一些实现:openinx.github.io/ppt/i
- wal和sstbale的写入使用io_uring,但是测完之后性能提升不明显。
- compaction file write的时间降低了一半。
- 可用io_uring优化的点:参考 Conclusion & Future work 章节。
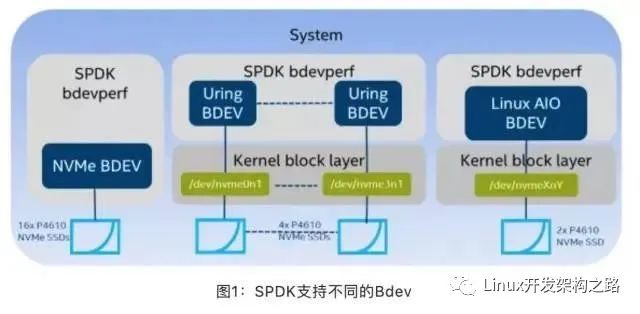
spdk
SPDK与io_uring新异步IO机制,在其抽象的通用块层加入了io_uring的支持。
ceph
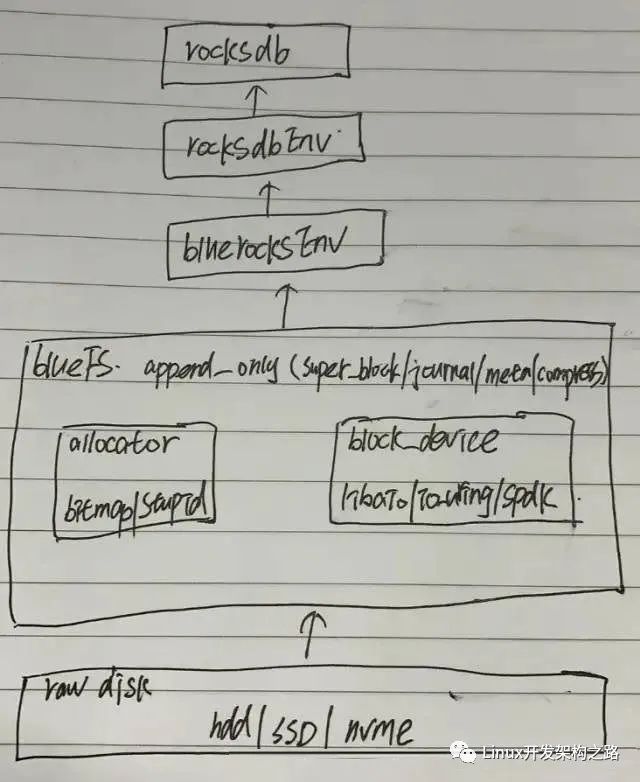
ceph的io_uring主要使用在block_device,抽象出了统一的块设备,直接操作裸设备,对上层提供统一的读写方法。
bluefs仅仅需要提供append only的写入即可,不需要提供随机写,大大简化了bluefs的实现。
第三方适配(nginx、redis、echo_server)
第三方io_uring适配(nginx、redis、echo_server)性能测试结果:
redis:
以下是 redis 在 event poll 和 io_uring 下的 qps 对比:
- 高负载情况下,io_uring 相比 event poll,吞吐提升 8%~11%。
- 开启 sqpoll 时,吞吐提升 24%~32%。这里读者可能会有个疑问,开启 sqpoll 额外使用了一个 CPU,性能为什么才提升 30% 左右?那是因为 redis 运行时同步读写就消耗了 70% 以上的 CPU,而 sq_thread 只能使用一个 CPU 的能力,把读写工作交给 sq_thread 之后,理论上 QPS 最多能提升 40% 左右(1/0.7 - 1 = 0.42),再加上 sq_thread 还需要处理中断以及本身的开销,因此只能有 30% 左右的提升。
nginx:
- 单 worker 场景,当连接数超过 500 时,QPS提升 20% 以上。
- connection 固定 1000,worker 数目在 8 以下时,QPS 有 20% 左右的提升。随着 worker 数目增大,收益逐渐降低。
- 短连接场景,io uring 相对于 event poll 非但没有提升,甚至在某些场景下有 5%~10% 的性能下降。究其原因,除了 io uring 框架本身带来的开销以外,还可能跟 io uring 编程模式下请求批量下发带来的延迟有关。
-
信号驱动IO与异步IO的区别2023-11-08 2381
-
多路IO复用模型和异步IO模型介绍2023-10-08 1939
-
网络编程框架netty io介绍2023-09-28 742
-
Linux驱动学习笔记:异步IO2023-06-12 1410
-
HarmonyOS多媒体框架介绍2023-01-03 1449
-
一个高性能异步计算框架介绍2022-10-25 1658
-
简单实用的框架,可用于快速增加或修改IO配置2022-05-17 1911
-
详解Netty高性能异步事件驱动的网络框架2022-03-16 3091
-
一文详细了解五种IO模型2022-02-14 6838
-
异步IO是什么2021-09-06 1156
-
异步传输和同步传输的区别介绍2018-03-02 11420
-
《Linux设备驱动开发详解》第9章、Linux设备驱动中的异步通知与异步IO2017-10-27 1060
-
android框架与应用开发介绍2017-10-24 879
全部0条评论

快来发表一下你的评论吧 !
