

C++异步日志实践
描述
一个高效可拓展的异步C++日志库:RING LOG,本文分享了了其设计方案与技术原理等内容
导论
同步日志与缺点
传统的日志也叫同步日志,每次调用一次打印日志API就对应一次系统调用write写日志文件,在日志产生不频繁的场景下没什么问题
可是,如果日志打印很频繁,同步日志有什么问题?
- 一方面,大量的日志打印陷入等量的write系统调用,有一定系统开销
- 另一方面,使得打印日志的进程附带了大量同步的磁盘IO,影响性能
那么,如何解决如上的问题?就是
异步日志与队列实现的缺点
异步日志,按我的理解就是主线程的日志打印接口仅负责生产日志数据(作为日志的生产者),而日志的落地操作留给另一个后台线程去完成(作为日志的消费者),这是一个典型的生产-消费问题,如此一来会使得:
主线程调用日志打印接口成为非阻塞操作,同步的磁盘IO从主线程中剥离出来,有助于提高性能
对于异步日志,我们很容易借助队列来一个实现方式:主线程写日志到队列,队列本身使用条件变量、或者管道、eventfd等通知机制,当有数据入队列就通知消费者线程去消费日志
但是,这样的异步队列也有一定的问题:
- 生产者线程产生N个日志,对应后台线程就会被通知N次,频繁日志写入会造成一定性能开销
- 不同队列实现方式也各有缺点:
- 用数组实现:空间不足时,队列内存不易拓展
- 用链表实现:每条消息的生产消费都对应内存的创建销毁,有一定开销
好了,可以开始正文了
简介
RING LOG是一个适用于C++的异步日志, 其特点是效率高(实测每秒支持125+万日志写入)、易拓展,尤其适用于频繁写日志的场景
一句话介绍原理:
使用多个大数组缓冲区作为日志缓冲区,多个大数组缓冲区以双循环链表方式连接,并使用两个指针p1和p2指向链表两个节点,分别用以生成数据、与消费数据
生产者可以是多线程,共同持有p1来生产数据,消费者是一个后台线程,持有p2去消费数据
大数组缓冲区 + 双循环链表的设计,使得日志缓冲区相比于队列有更强大的拓展能力、且避免了大量内存申请释放,提高了异步日志在海量日志生成下的性能表现
此外,RING LOG还优化了每条日志的UTC格式时间的生成,明显提高日志性能
具体工作原理
数据结构
Ring Log的缓冲区是若干个cell_buffer以双向、循环的链表组成
cell_buffer是简单的一段缓冲区,日志追加于此,带状态:
- FREE:表示还有空间可追加日志
- FULL:表示暂时无法追加日志,正在、或即将被持久化到磁盘;
Ring Log有两个指针:
- Producer Ptr:生产者产生的日志向这个指针指向的cell_buffer里追加,写满后指针向前移动,指向下一个cell_buffer;Producer Ptr永远表示当前日志写入哪个cell_buffer,被多个生产者线程共同持有
- Consumer Ptr:消费者把这个指针指向的cell_buffer里的日志持久化到磁盘,完成后执行向前移动,指向下一个cell_buffer;Consumer Ptr永远表示哪个cell_buffer正要被持久化,仅被一个后台消费者线程持有
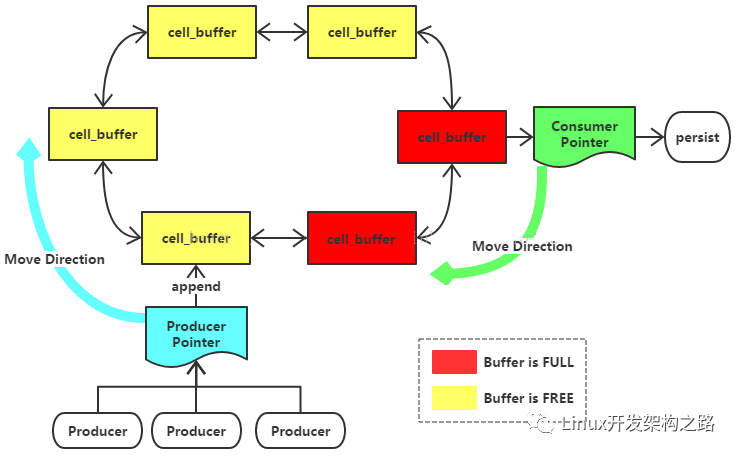
起始时刻,每个cell_buffer状态均为FREE Producer Ptr与Consumer Ptr指向同一个cell_buffer
整个Ring Log被一个互斥锁mutex保护
大致原理
消费者
后台线程(消费者)forever loop:
1.上锁,检查当前Consumer Ptr:
- 如果对应cell_buffer状态为FULL,释放锁,去STEP 4;
- 否则,以1秒超时时间等待条件变量cond;
2.再次检查当前Consumer Ptr:
- 若cell_buffer状态为FULL,释放锁,去STEP 4;
- 否则,如果cell_buffer无内容,则释放锁,回到STEP 1;
- 如果cell_buffer有内容,将其标记为FULL,同时Producer Ptr前进一位;
3.释放锁
4.持久化cell_buffer
5.重新上锁,将cell_buffer状态标记为FREE,并清空其内容;Consumer Ptr前进一位;
6.释放锁
生产者
1.上锁,检查当前Producer Ptr对应cell_buffer状态:
如果cell_buffer状态为FREE,且生剩余空间足以写入本次日志,则追加日志到cell_buffer,去STEP X;
2.如果cell_buffer状态为FREE但是剩余空间不足了,标记其状态为FULL,然后进一步探测下一位的next_cell_buffer:
- 如果next_cell_buffer状态为FREE,Producer Ptr前进一位,去STEP X;
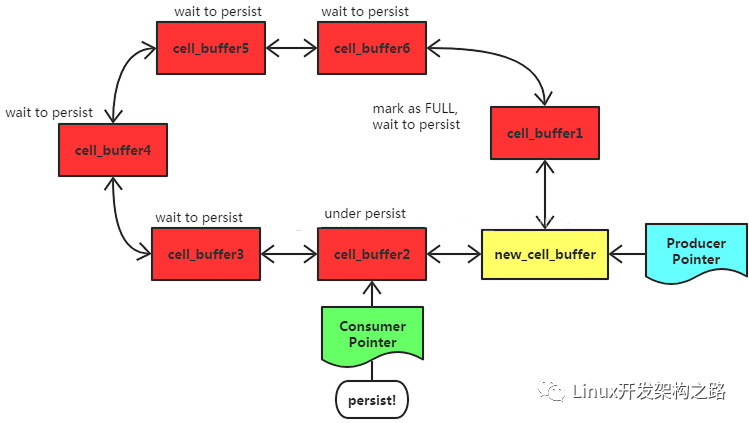
- 如果next_cell_buffer状态为FULL,说明Consumer Ptr = next_cell_buffer,Ring Log缓冲区使用完了;则我们继续申请一个new_cell_buffer,将其插入到cell_buffer与next_cell_buffer之间,并使得Producer Ptr指向此new_cell_buffer,去STEP X;
3.如果cell_buffer状态为FULL,说明此时Consumer Ptr = cell_buffer,丢弃日志;
4.释放锁,如果本线程将cell_buffer状态改为FULL则通知条件变量cond
在大量日志产生的场景下,Ring Log有一定的内存拓展能力;实际使用中,为防止Ring Log缓冲区无限拓展,会限制内存总大小,当超过此内存限制时不再申请新cell_buffer而是丢弃日志
图解各场景
初始时候,Consumer Ptr与Producer Ptr均指向同一个空闲cell_buffer1
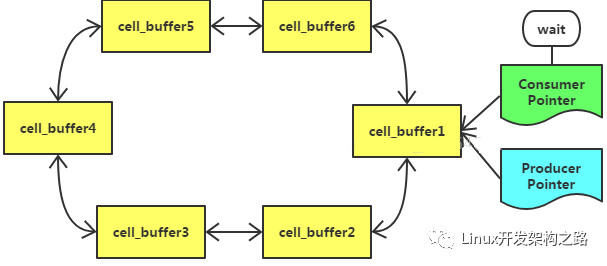
然后生产者在1s内写满了cell_buffer1,Producer Ptr前进,通知后台消费者线程持久化
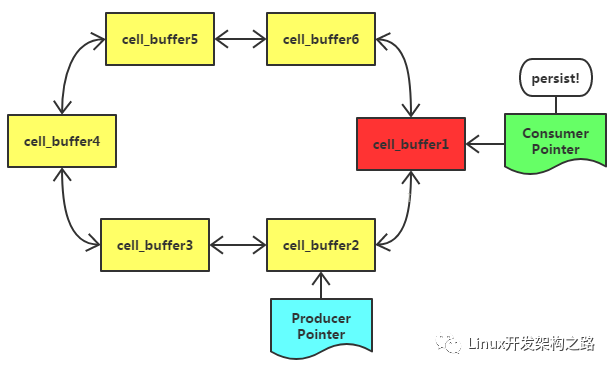
消费者持久化完成,重置cell_buffer1,Consumer Ptr前进一位,发现指向的cell_buffer2未满,等待
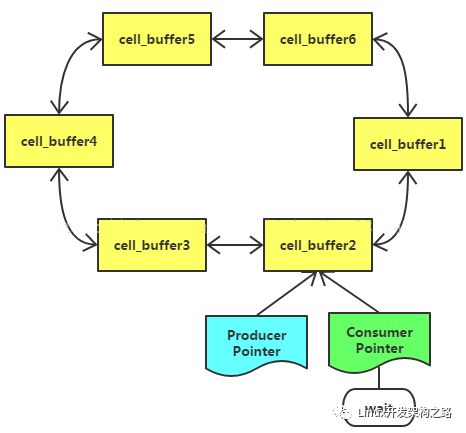
超过一秒后cell_buffer2虽有日志,但依然未满:消费者将此cell_buffer2标记为FULL强行持久化,并将Producer Ptr前进一位到cell_buffer3
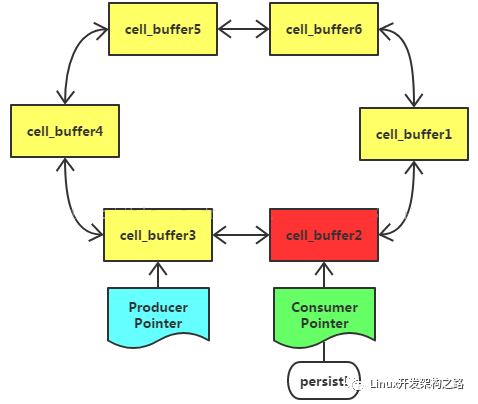
消费者在cell_buffer2的持久化上延迟过大,结果生产者都写满cell_buffer3456,已经正在写cell_buffer1了
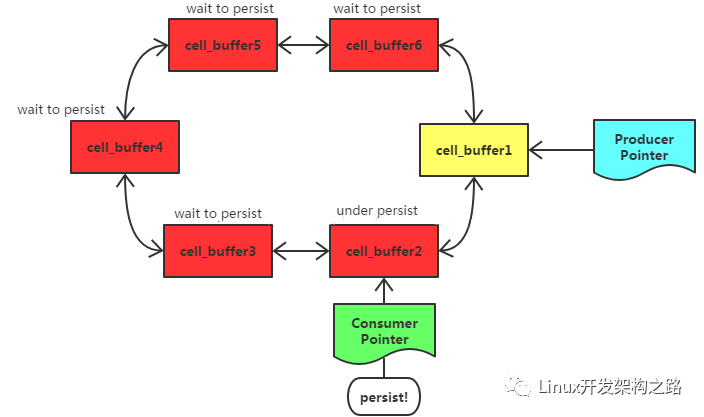
生产者写满写cell_buffer1,发现下一位cell_buffer2是FULL,则拓展换冲区,新增new_cell_buffer
UTC时间优化
每条日志往往都需要UTC时间:yyyy-mm-dd hh:mm:ss(PS:Ring Log提供了毫秒级别的精度)
Linux系统下本地UTC时间的获取需要调用localtime函数获取年月日时分秒
在localtime调用次数较少时不会出现什么性能问题,但是写日志是一个大批量的工作,如果每条日志都调用localtime获取UTC时间,性能无法接受
在实际测试中,对于1亿条100字节日志的写入,未优化locatime函数时 RingLog写内存耗时245.41s,仅比传统日志写磁盘耗时292.58s快将近一分钟;而在优化locatime函数后,RingLog写内存耗时79.39s,速度好几倍提升
策略
为了减少对localtime的调用,使用以下策略
RingLog使用变量_sys_acc_sec记录写上一条日志时,系统经过的秒数(从1970年起算)、使用变量_sys_acc_min记录写上一条日志时,系统经过的分钟数,并缓存写上一条日志时的年月日时分秒year、mon、day、hour、min、sec,并缓存UTC日志格式字符串
每当准备写一条日志:
- 调用gettimeofday获取系统经过的秒tv.tv_sec,与_sys_acc_sec比较;
- 如果tv.tv_sec 与 _sys_acc_sec相等,说明此日志与上一条日志在同一秒内产生,故年月日时分秒是一样的,直接使用缓存即可;
- 否则,说明此日志与上一条日志不在同一秒内产生,继续检查:tv.tv_sec/60即系统经过的分钟数与_sys_acc_min比较;
- 如果tv.tv_sec/60与_sys_acc_min相等,说明此日志与上一条日志在同一分钟内产生,故年月日时分是一样的,年月日时分 使用缓存即可,而秒sec = tv.tv_sec%60,更新缓存的秒sec,重组UTC日志格式字符串的秒部分;
- 否则,说明此日志与上一条日志不在同一分钟内产生,调用localtime重新获取UTC时间,并更新缓存的年月日时分秒,重组UTC日志格式字符串
小结:如此一来,localtime一分钟才会调用一次,频繁写日志几乎不会有性能损耗
性能测试
对比传统同步日志、与RingLog日志的效率(为了方便,传统同步日志以sync log表示)
1. 单线程连续写1亿条日志的效率
分别使用Sync log与Ring log写1亿条日志(每条日志长度为100字节)测试调用总耗时,测5次,结果如下:

单线程运行下,Ring Log写日志效率是传统同步日志的近3.7倍,可以达到每秒127万条长为100字节的日志的写入
2、多线程各写1千万条日志的效率
分别使用Sync log与Ring log开5个线程各写1千万条日志(每条日志长度为100字节)测试调用总耗时,测5次,结果如下:

多线程(5线程)运行下,Ring Log写日志效率是传统同步日志的近3.8倍,可以达到每秒135.5万条长为100字节的日志的写入
2. 对server QPS的影响
现有一个Reactor模式实现的echo Server,其纯净的QPS大致为19.32万/s
现在分别使用Sync Log、Ring Log来测试:echo Server在每收到一个数据就调用一次日志打印下的QPS表现
对于两种方式,分别采集12次实时QPS,统计后大致结果如下:

传统同步日志sync log使得echo Server QPS从19.32w万/s降低至11.42万/s,损失了40.89%RingLog使得echo Server QPS从19.32w万/s降低至16.72万/s,损失了13.46%
TODO
- 日志本身缓存大小的配置
- 程序正常退出、异常退出,此时在buffer中缓存的日志会丢失
- 第N天23:59:59秒产生的日志有时会被刷写到第N+1天的日志文件中
-
C++代码需要遵循的10个最佳实践2022-10-18 1720
-
现代C++项目的最佳实践2022-09-29 2021
-
写好C++代码需要遵循的10个最佳实践2022-09-19 1242
-
在NDK开发中C++的代码中怎么实现日志输出2021-09-30 1765
-
Visual C++ 串口通信技术与工程实践2019-08-19 2009
-
C++程序设计教程之C++的初步知识的详细资料说明2019-03-14 1459
-
《Visual C++编程基础与实践》中文电子教材详细资料免费下载2018-07-09 1393
-
Visual C++小波变换技术与工程实践2018-02-15 3530
-
C++程序设计原理与实践2017-02-28 1117
-
Visual C++数字图像模式识别技术及工程实践2015-11-06 679
-
《C++程序设计原理与实践》(C++之父最新力作)2012-08-19 7436
-
C++课件、习题及答案2008-09-08 812
全部0条评论

快来发表一下你的评论吧 !
