

epoll和select使用区别
描述
epoll 和select
相比于select,epoll最大的好处在于它不会随着监听fd数目的增长而降低效率。因为在内核中的select实现中,它是采用轮询来处理的,轮询的fd数目越多,自然耗时越多。
并且,在linux/posix_types.h头文件有这样的声明:
#define __FD_SETSIZE 1024
表示select最多同时监听1024个fd,当然,可以通过修改头文件再重编译内核来扩大这个数目,但这似乎并不治本。
一、IO多路复用的select
IO多路复用相对于阻塞式和非阻塞式的好处就是它可以监听多个 socket ,并且不会消耗过多资源。当用户进程调用 select 时,它会监听其中所有 socket 直到有一个或多个 socket 数据已经准备好,否则就一直处于阻塞状态。select的缺点在于单个进程能够监视的文件描述符的数量存在最大限制,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的的开销也线性增长。同时,由于网络响应时间的延迟使得大量的tcp链接处于非常活跃状态,但调用select()会对所有的socket进行一次线性扫描,所以这也浪费了一定的开销。不过它的好处还有就是它的跨平台特性。
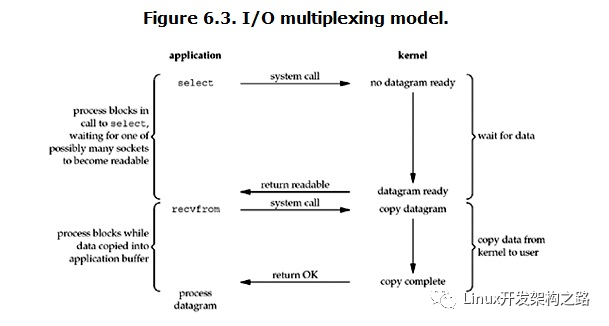
二、 epoll
epoll的ET是必须对非阻塞的socket才能工作,LT对于阻塞的socket也可以
所有I/O多路复用操作都是同步的,涵盖select/poll。
阻塞/非阻塞是相对于同步I/O来说的,与异步I/O无关。
select/poll/epoll本身是同步的,可以阻塞也可以不阻塞。
(阻塞和非阻塞 与同步不同步不同;阻塞与否 是自身,异步与否是与外部协作的关系)
skater:
无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间(epoll应该是从mmap),过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。

EPOLLIN : 表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT: 表示对应的文件描述符可以写;
EPOLLPRI: 表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR: 表示对应的文件描述符发生错误;
EPOLLHUP: 表示对应的文件描述符被挂断;
epoll高效的核心是:1、用户态和内核太共享内存mmap。2、数据到来采用事件通知机制(而不需要轮询)。
epoll的接口
epoll的接口非常简单,一共就三个函数:
(1)epoll_create系统调用
epoll_create在C库中的原型如下。
int epoll_create(int size);
epoll_create返回一个句柄,之后 epoll的使用都将依靠这个句柄来标识。参数 size是告诉 epoll所要处理的大致事件数目。不再使用 epoll时,必须调用 close关闭这个句柄。
注意:size参数只是告诉内核这个 epoll对象会处理的事件大致数目,而不是能够处理的事件的最大个数。在 Linux最新的一些内核版本的实现中,这个 size参数没有任何意义。
(2)epoll_ctl系统调用
epoll_ctl在C库中的原型如下。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event);
epoll_ctl向 epoll对象中添加、修改或者删除感兴趣的事件,返回0表示成功,否则返回–1,此时需要根据errno错误码判断错误类型。epoll_wait方法返回的事件必然是通过 epoll_ctl添加到 epoll中的。
参数:
epfd: epoll_create返回的句柄,
op:的意义见下表:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd;
fd:需要监听的socket句柄fd,
event:告诉内核需要监听什么事的结构体,struct epoll_event结构如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
__uint32_t events就要监听的事件(感兴趣的事件):
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里

typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
可见,这个 data成员还与具体的使用方式相关。例如,ngx_epoll_module模块只使用了联合中的 ptr成员,
作为指向 ngx_connection_t连接的指针。我们在项目中一般使用的也是 ptr成员,因为它可以指向任意的结构
体地址。
- int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll_wait在C库中的原型如下:
int epoll_wait(int epfd,struct epoll_event* events,int maxevents,int timeout);
收集在 epoll监控的事件中已经发生的事件,如果 epoll中没有任何一个事件发生,则最多等待timeout毫秒后返回。epoll_wait的返回值表示当前发生的事件个数,如果返回0,则表示本次调用中没有事件发生,如果返回–1,则表示出现错误,需要检查 errno错误码判断错误类型。
epfd:epoll的描述符。
events:分配好的 epoll_event结构体数组,epoll将会把发生的事件复制到 events数组中(events不可以是空指针,内核只负责把数据复制到这个 events数组中,不会去帮助我们在用户态中分配内存。内核这种做法效率很高)。
maxevents:表示本次可以返回的最大事件数目,通常 maxevents参数与预分配的events数组的大小是相等的。
timeout:表示在没有检测到事件发生时最多等待的时间(单位为毫秒),如果 timeout为0,则表示 epoll_wait在 rdllist链表中为空,立刻返回,不会等待。
epoll有两种工作模式:LT(水平触发)模式和ET(边缘触发)模式。
默认情况下,epoll采用 LT模式工作,这时可以处理阻塞和非阻塞套接字,而上表中的 EPOLLET表示可以将一个事件改为 ET模式。ET模式的效率要比 LT模式高,它只支持非阻塞套接字。
(水平触发LT:当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait()时,它还会通知你在上次没读写完的文件描述符上继续读写
边缘触发ET:当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你
此可见,水平触发时如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率,而边缘触发,则不会充斥大量你不关心的就绪文件描述符,从而性能差异,高下立见。)
如何来使用epoll
1、包含一个头文件#include
2、create_epoll(int maxfds)来创建一个epoll的句柄,其中maxfds为你epoll所支持的最大句柄数。这个函数会返回一个新的epoll句柄,之后的所有操作将通过这个句柄来进行操作。在用完之后,记得用close()来关闭这个创建出来的epoll句柄。
3、之后在你的网络主循环里面,每一帧的调用epoll_wait(int epfd, epoll_event events, int max events, int timeout)来查询所有的网络接口,看哪一个可以读,哪一个可以写了。基本的语法为:
nfds = epoll_wait(kdpfd, events, maxevents, -1);
其中kdpfd为用epoll_create创建之后的句柄,events是一个epoll_event*的指针,当epoll_wait这个函数操作成功之后,epoll_events里面将储存所有的读写事件。max_events是当前需要监听的所有socket句柄数。
最后一个timeout:是epoll_wait的超时,
为0的时候表示马上返回,
为-1的时候表示一直等下去,直到有事件返回,
为任意正整数的时候表示等这么长的时间,如果一直没有事件,则返回。
一般如果网络主循环是单独的线程的话,可以用-1来等,这样可以保证一些效率,如果是和主逻辑在同一个线程的话,则可以用0来保证主循环的效率。
epoll_wait范围之后应该是一个循环,遍利所有的事件。
epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据结构实现?B+树)。把原先的select/poll调用分成了3个部分:
1)调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源)
2)调用epoll_ctl向epoll对象中添加这100万个连接的套接字
3)调用epoll_wait收集发生的事件的连接
epoll程序框架
几乎所有的epoll程序都使用下面的框架:
伪代码:
listenfd为全局变量,服务端监听的套接字的fd。
void test(int epollfd)
{
struct epoll_event events[MAX_EVENT_NUMBER];
int number;
while (1)
{
number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
printf("number : %2dnn", number);
for (i = 0; i < number; i++)
{
sockfd = events[i].data.fd;
if (sockfd == listenfd)
{/*用户上线*/
}
else if (events[i].events & EPOLLIN)
{/*有数据可读*/
}
else if (events[i].events & EPOLLOUT)
{/*有数据可写*/
}
else
{/*出错*/
}
}
}
}
通过测试发现epoll_wait返回值number是不会大于MAX_EVENT_NUMBER的。
测试过程中,连接的客户端数远大于MAX_EVENT_NUMBER,由此可以推论:epoll_wait()每次返回的是活跃客户端的个数,每次并将这些活跃的客户端信息加入到events[MAX_EVENT_NUMBER]。
由此可见,活跃客户端的个数相同的情况下,events[MAX_EVENT_NUMBER]越大,epoll_wait()函数执行次数越少,但是events[MAX_EVENT_NUMBER]越大越消耗存储资源。
所以,MAX_EVENT_NUMBER的选择应该在效率和资源间取一个平衡点。
示例代码
{
nfds = epoll_wait(epfd,events,20,500);
for(i=0;i {
if(events[i].data.fd==listenfd) //服务端监听的套接字listenfd上有新的连接
{
connfd = accept(listenfd,(sockaddr *)&clientaddr, &clilen); //accept这个连接
ev.data.fd=connfd; //把[这个新连接的fd]加入ev
ev.events=EPOLLIN|EPOLLET; //[关注该连接的EPOLLIN事件,EPOLLET边缘触发]加入ev
epoll_ctl(epfd,EPOLL_CTL_ADD,connfd,&ev); //ev添加到epoll的监听队列中
}
else if( events[i].events&EPOLLIN ) //接收到数据,读socket
{
n = read(sockfd, line, MAXLINE)) < 0 //读
ev.data.ptr = md; //md为自定义类型,添加数据
ev.events=EPOLLOUT|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);//修改标识符,等待下一个循环时发送数据,异步处理的精髓
//epfd 就是epoll_create()返回的epfd
}
else if(events[i].events&EPOLLOUT) //有数据待发送,写socket
{
struct myepoll_data* md = (myepoll_data*)events[i].data.ptr; //取数据
sockfd = md->fd;
send( sockfd, md->ptr, strlen((char*)md->ptr), 0 ); //发送数据
ev.data.fd=sockfd;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev); //修改标识符,等待下一个循环时接收数据
}
else
{
//其他的处理
}
}
};++i)
大致流程
listenfd = socket(AF_INET, SOCK_STREAM, 0);
if(0 != bind(listenfd, (struct sockaddr *)
if(0 != listen(listenfd, LISTENQ)) //LISTENQ 定义了宏//#define LISTENQ 20
ev.data.fd = listenfd; //设置与要处理的事件相关的文件描述符
ev.events = EPOLLIN | EPOLLET; //设置要处理的事件类型EPOLLIN :表示对应的文件描述符可以读,EPOLLET状态变化才通知
epfd = epoll_create(256); //生成用于处理accept的epoll专用的文件描述符
//注册epoll事件
epoll_ctl(epfd, EPOLL_CTL_ADD, listenfd, &ev); //epfd epoll实例ID,EPOLL_CTL_ADD添加,listenfd:socket,ev事件(监听listenfd)
nfds = epoll_wait(epfd, event_list, EVENT_MAX_COUNT, TIMEOUT_MS); //等待epoll事件的发生
- 首先熟悉下epoll的三个接口
int epoll_create(int size);
创建epoll相关数据结构,其最重要的是
- 红黑树, 用于存储需要监控的文件句柄以及事件
- 就绪链表,用于存储被触发的文件句柄以及事件
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
用于设定,修改,或者删除 监控的文件句柄以及事件
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
阻塞等待timeout时间,如果文件句柄上相关事件被触发,则epoll_wait退出,并将触发的事件 写入出参 events参数,触发的事件个数作为返回值返回
- 如何使用这三个接口写一个server
- 首先使用epoll_create 创建epoll相关数据结构
- 其次创建TCP socket 文件句柄acceptfd,绑定(ip:port),然后开启监听,并使用epoll_ctl 注册到epoll中,监听acceptfd句柄的EPOLL_IN事件(即可读事件)
- 调用epoll_wait 开始进行阻塞等待
- 如果有客户端连接过来,则触发acceptfd上的EPOLL_IN事件,epoll_wait返回后,可以得到触发事件的信息, 这些信息其实就是一个struct epoll_event对象, 我们可以判断这个epoll event对象fd是否和acceptfd一致,如果一致在认为有新连接进来,则获得新连接对应的clientfd, 并使用epoll_ctl注册到epoll, 监控clientfd上的epoll_in事件,这个时候这个客户端和服务器的连接就建立了
void *ptr;
int fd; //可以用fd, 也可以用ptr来保存事件对应的文件句柄
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
- 用户在客户端输入命令,将会触发服务器端 clientfd上的epoll_in事件,epoll_wait返回触发的event, 读取event对应的clientfd内核缓冲区中的数据,解析协议,执行命令,得到返回结果,这个返回结果要返回给客户端,则再使用epoll_ctl注册clientfd的epoll_out事件到epoll,这个时候,我们会注意到clientfd上既有epoll_in,也有epoll_out,这样其实没有必要,客户端在这个时候等待返回结果,不会再输入命令,所以需要使用epoll_ctl把epoll_out删除掉
- 如果clientfd内核缓冲区可写,epoll_wait这个时候会返回,并返回epoll_out事件,此时把返回的结果数据写入clientfd, 返回给客户端
实例源码
原文有相当多的如错误:
需要增加到头文件和错误修改
//bzero() 替换为memset (注意二者参数不一样,bzero将前n个字节设为0,memset将前n 个字节的值设为值 c)
//local_addr 由char* 改为 string
#include
#include //atoi
#include //memset
#include //std:cout 等
修正后的源码C++ lnux:
#include
#include
#include
#include
#include
#include
#include
#include
//'/0'->'�'
//bzero() 替换为memset (注意二者参数不一样,bzero将前n个字节设为0,memset将前n 个字节的值设为值 c)
//local_addr 由char* 改为 string
#include
#include //atoi
#include //memset
#include //std:cout 等
using namespace std;
#define MAXLINE 255 //读写缓冲
#define OPEN_MAX 100
#define LISTENQ 20 //listen的第二个参数 定义TCP链接未完成队列的大小(linux >2.6 则表示accpet之前的队列)
#define SERV_PORT 5000
#define INFTIM 1000
#define TIMEOUT_MS 500
#define EVENT_MAX_COUNT 20
void setnonblocking(int sock)
{
int opts;
opts = fcntl(sock, F_GETFL);
if(opts < 0)
{
perror("fcntl(sock,GETFL)");
exit(1);
}
opts = opts | O_NONBLOCK;
if(fcntl(sock, F_SETFL, opts) < 0)
{
perror("fcntl(sock,SETFL,opts)");
exit(1);
}
}
int main(int argc, char *argv[])
{
int i, maxi, listenfd, connfd, sockfd, epfd, nfds, portnumber;
ssize_t n;
char line_buff[MAXLINE];
if ( 2 == argc )
{
if( (portnumber = atoi(argv[1])) < 0 )
{
fprintf(stderr, "Usage:%s portnumber/r/n", argv[0]);
//fprintf()函数根据指定的format(格式)(格式)发送信息(参数)到由stream(流)指定的文件
//printf 将内容发送到Default的输出设备,通常为本机的显示器,fprintf需要指定输出设备,可以为文件,设备。
//stderr
return 1;
}
}
else
{
fprintf(stderr, "Usage:%s portnumber/r/n", argv[0]);
return 1;
}
//声明epoll_event结构体的变量,ev用于注册事件,数组用于回传要处理的事件
struct epoll_event ev, event_list[EVENT_MAX_COUNT];
//生成用于处理accept的epoll专用的文件描述符
epfd = epoll_create(256); //生成epoll文件描述符,既在内核申请一空间,存放关注的socket fd上是否发生以及发生事件。size既epoll fd上能关注的最大socket fd数。随你定好了。只要你有空间。
struct sockaddr_in clientaddr;
socklen_t clilenaddrLen;
struct sockaddr_in serveraddr;
listenfd = socket(AF_INET, SOCK_STREAM, 0);//Unix/Linux“一切皆文件”,创建(套接字)文件,id=listenfd
if (listenfd < 0)
{
printf("socket error,errno %d:%srn",errno,strerror(errno));
}
//把socket设置为非阻塞方式
//setnonblocking(listenfd);
//设置与要处理的事件相关的文件描述符
ev.data.fd = listenfd;
//设置要处理的事件类型
ev.events = EPOLLIN | EPOLLET; //EPOLLIN :表示对应的文件描述符可以读,EPOLLET状态变化才通知
//ev.events=EPOLLIN;
//注册epoll事件
epoll_ctl(epfd, EPOLL_CTL_ADD, listenfd, &ev); //epfd epoll实例ID,EPOLL_CTL_ADD添加,listenfd:socket,ev事件(监听listenfd)
memset(&serveraddr, 0, sizeof(serveraddr));
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr=htonl(INADDR_ANY); /*IP,INADDR_ANY转换过来就是0.0.0.0,泛指本机的意思,也就是表示本机的所有IP*/
serveraddr.sin_port = htons(portnumber);
if(0 != bind(listenfd, (struct sockaddr *)&serveraddr, sizeof(serveraddr)))
{
printf("bind error,errno %d:%srn",errno,strerror(errno));
}
if(0 != listen(listenfd, LISTENQ)) //LISTENQ 定义了宏
{
printf("listen error,errno %d:%srn",errno,strerror(errno));
}
maxi = 0;
for ( ; ; )
{
//等待epoll事件的发生
nfds = epoll_wait(epfd, event_list, EVENT_MAX_COUNT, TIMEOUT_MS); //epoll_wait(int epfd, struct epoll_event * event_list, int maxevents, int timeout),返回需要处理的事件数目
//处理所发生的所有事件
for(i = 0; i < nfds; ++i)
{
if(event_list[i].data.fd == listenfd) //如果新监测到一个SOCKET用户连接到了绑定的SOCKET端口,建立新的连接。
{
clilenaddrLen = sizeof(struct sockaddr_in);//在调用accept()前,要给addrLen赋值,这样才不会出错,addrLen = sizeof(clientaddr);或addrLen = sizeof(struct sockaddr_in);
connfd = accept(listenfd, (struct sockaddr *)&clientaddr, &clilenaddrLen);//(accpet详解:https://blog.csdn.net/David_xtd/article/details/7087843)
if(connfd < 0)
{
//perror("connfd<0:connfd= %d",connfd);
printf("connfd<0,accept error,errno %d:%srn",errno,strerror(errno));
exit(1);
}
//setnonblocking(connfd);
char *str = inet_ntoa(clientaddr.sin_addr);//将一个32位网络字节序的二进制IP地址转换成相应的点分十进制的IP地址
cout << "accapt a connection from " << str << endl;
//设置用于读操作的文件描述符
ev.data.fd = connfd;
//设置用于注测的读操作事件
ev.events = EPOLLIN | EPOLLET;
//ev.events=EPOLLIN;
//注册ev
epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, &ev); //将accpet的句柄添加进入(增加监听的对象)
}
else if(event_list[i].events & EPOLLIN) //如果是已经连接的用户,并且收到数据,那么进行读入。
{
cout << "EPOLLIN" << endl;
if ( (sockfd = event_list[i].data.fd) < 0)
continue;
if ( (n = read(sockfd, line_buff, MAXLINE)) < 0) //read时fd中的数据如果小于要读取的数据,就会引起阻塞?
{
//当read()或者write()返回-1时,一般要判断errno
if (errno == ECONNRESET)//与客户端的Socket被客户端强行被断开,而服务器还企图read
{
close(sockfd);
event_list[i].data.fd = -1;
}
else
std::cout << "readline error" << std::endl;
}
else if (n == 0) //返回的n为0时,说明客户端已经关闭
{
close(sockfd);
event_list[i].data.fd = -1;
}
line_buff[n] = '�';
cout << "read " << line_buff << endl;
//设置用于写操作的文件描述符
ev.data.fd = sockfd;
//设置用于注测的写操作事件
ev.events = EPOLLOUT | EPOLLET; //EPOLLOUT:表示对应的文件描述符可以写;
//修改sockfd上要处理的事件为EPOLLOUT
//epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);
}
else if(event_list[i].events & EPOLLOUT) // 如果有数据发送
{
sockfd = event_list[i].data.fd;
write(sockfd, line_buff, n);
//设置用于读操作的文件描述符
ev.data.fd = sockfd;
//设置用于注测的读操作事件
ev.events = EPOLLIN | EPOLLET;
//修改sockfd上要处理的事件为EPOLIN
epoll_ctl(epfd, EPOLL_CTL_MOD, sockfd, &ev);
}
}
}
return 0;
}
编译命令
linux下编译:g++ epoll.cpp -o epoll
命令行简单测试
curl 192.168.0.250:5000 -d "phone=123456789&name=Hwei"
相关知识
如何动态的改变listen监听的个数呢?
如果指定值在源代码中是一个常值,那么增长其大小需要重新编译服务器程序。那么,我们可以为它设定一个缺省值,不过允许通过命令行选项或者环境变量来覆写该值。
{
char *ptr;
if((ptr = getenv("LISTENQ")) != NULL)
backlog = atoi(ptr);
if(listen(fd, backlog) < 0)
printf("listen errorn");
}
队列已满的情况,如何处理?
当一个客户SYN到达时,若这个队列是满的,TCP就忽略该分节,也就是不会发送RST。
这么做的原因在于,队列已满的情况是暂时的,客户TCP如果没收收到RST,就会重发SYN,在队列有空闲的时候处理该请求。如果服务器TCP立即响应一个RST,客户的connect调用就会立即返回一个错误,强制应用进程处理这种情况,而不会再次重发SYN。而且客户端也不无区别该套接口的状态,是“队列已满”还是“该端口没有在监听”。
SYN泛滥攻击
向某一目标服务器发送大量的SYN,用以填满一个或多个TCP端口的未完成队列。每个SYN的源IP地址都置成随机数(IP欺骗),这样防止攻击服务器获悉黑客的真实IP地址。通过伪造的SYN装满未完成连接队列,使得合法的SYN不能排上队,导致针对合法用户的服务被拒绝。
防御方法:
- 针对服务器主机的方法。增加连接缓冲队列长度和缩短连接请求占用缓冲队列的超时时间。该方式最简单,被很多操作系统采用,但防御性能也最弱。
- 针对路由器过滤的方法。由于DDoS攻击,包括SYN-Flood,都使用地址伪装技术,所以在路由器上使用规则过滤掉被认为地址伪装的包,会有效的遏制攻击流量。
- 针对防火墙的方法。在SYN请求连接到真正的服务器之前,使用基于防火墙的网关来测试其合法性。它是一种被普遍采用的专门针对SYN-Flood攻击的防御机制。
SYN:同步序列编号(Synchronize Sequence Numbers)
SYN表示建立连接,
FIN表示关闭连接,
ACK表示响应,
PSH表示有
DATA数据传输,
RST表示连接重置。
SYN(synchronous建立联机)
ACK(acknowledgement 确认)
PSH(push传送)
FIN(finish结束)
RST(reset重置)
URG(urgent紧急)
Sequence number(顺序号码)
Acknowledge number(确认号码)
三次握手:
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。完成三次握手,客户端与服务器开始传送数据.
第一次握手:主机A发送位码为syn=1,随机产生seq number=1234567的数据包到服务器,主机B由SYN=1知道,A要求建立联机;
第二次握手:主机B收到请求后要确认联机信息,向A发送ack number=(主机A的seq+1),syn=1,ack=1,随机产生seq=7654321的包;
第三次握手:主机A收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ack是否为1,若正确,主机A会再发送ack number=(主机B的seq+1),ack=1,主机B收到后确认seq值与ack=1则连接建立成功。
实例代码二
多进程Epoll:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define PROCESS_NUM 10
static int
create_and_bind (char *port)
{
int fd = socket(PF_INET, SOCK_STREAM, 0);
struct sockaddr_in serveraddr;
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);
serveraddr.sin_port = htons(atoi(port));
bind(fd, (struct sockaddr*)&serveraddr, sizeof(serveraddr));
return fd;
}
static int
make_socket_non_blocking (int sfd)
{
int flags, s;
flags = fcntl (sfd, F_GETFL, 0);
if (flags == -1)
{
perror ("fcntl");
return -1;
}
flags |= O_NONBLOCK;
s = fcntl (sfd, F_SETFL, flags);
if (s == -1)
{
perror ("fcntl");
return -1;
}
return 0;
}
#define MAXEVENTS 64
int
main (int argc, char *argv[])
{
int sfd, s;
int efd;
struct epoll_event event;
struct epoll_event *events;
sfd = create_and_bind("1234");
if (sfd == -1)
abort ();
s = make_socket_non_blocking (sfd);
if (s == -1)
abort ();
s = listen(sfd, SOMAXCONN);
if (s == -1)
{
perror ("listen");
abort ();
}
efd = epoll_create(MAXEVENTS);
if (efd == -1)
{
perror("epoll_create");
abort();
}
event.data.fd = sfd;
//event.events = EPOLLIN | EPOLLET;
event.events = EPOLLIN;
s = epoll_ctl(efd, EPOLL_CTL_ADD, sfd, &event);
if (s == -1)
{
perror("epoll_ctl");
abort();
}
/* Buffer where events are returned */
events = calloc(MAXEVENTS, sizeof event);
int k;
for(k = 0; k < PROCESS_NUM; k++)
{
int pid = fork();
if(pid == 0)
{
/* The event loop */
while (1)
{
int n, i;
n = epoll_wait(efd, events, MAXEVENTS, -1);
printf("process %d return from epoll_wait!n", getpid());
/* sleep here is very important!*/
//sleep(2);
for (i = 0; i < n; i++)
{
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP)
|| (!(events[i].events & EPOLLIN)))
{
/* An error has occured on this fd, or the socket is not
ready for reading (why were we notified then?) */
fprintf (stderr, "epoll errorn");
close (events[i].data.fd);
continue;
}
else if (sfd == events[i].data.fd)
{
/* We have a notification on the listening socket, which
means one or more incoming connections. */
struct sockaddr in_addr;
socklen_t in_len;
int infd;
char hbuf[NI_MAXHOST], sbuf[NI_MAXSERV];
in_len = sizeof in_addr;
infd = accept(sfd, &in_addr, &in_len);
if (infd == -1)
{
printf("process %d accept failed!n", getpid());
break;
}
printf("process %d accept successed!n", getpid());
/* Make the incoming socket non-blocking and add it to the
list of fds to monitor. */
close(infd);
}
}
}
}
}
int status;
wait(&status);
free (events);
close (sfd);
return EXIT_SUCCESS;
}
建立2000+个链接的测试代码
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
const int MAXLINE = 5;
int count = 1;
static int make_socket_non_blocking(int fd)
{
int flags, s;
flags = fcntl (fd, F_GETFL, 0);
if (flags == -1)
{
perror ("fcntl");
return -1;
}
flags |= O_NONBLOCK;
s = fcntl (fd, F_SETFL, flags);
if (s == -1)
{
perror ("fcntl");
return -1;
}
return 0;
}
void sockconn()
{
int sockfd;
struct sockaddr_in server_addr;
struct hostent *host;
char buf[100];
unsigned int value = 1;
host = gethostbyname("127.0.0.1");
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("socket errorrn");
return;
}
//setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &value, sizeof(value));
//make_socket_non_blocking(sockfd);
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(8080);
server_addr.sin_addr = *((struct in_addr*) host->h_addr);
int cn = connect(sockfd, (struct sockaddr *) &server_addr,
sizeof(server_addr));
if (cn == -1) {
printf("connect error errno=%drn", errno);
return;
}
// char *buf = "h";
sprintf(buf, "%d", count);
count++;
write(sockfd, buf, strlen(buf));
close(sockfd);
printf("client send %srn", buf);
return;
}
int main(void) {
int i;
for (i = 0; i < 2000; i++)
{
sockconn();
}
return 0;
}
关于ET、LT两种工作模式
水平触发LT:
其中LT就是与select和poll类似,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait()时,它还会通知你在上次没读写完的文件描述符上继续读写
边缘触发ET:
当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你
水平触发:只要缓冲区有数据就会一直触发
边沿触发:只有在缓冲区增加数据的那一刻才会触发
由此可见,水平触发时如果系统中有大量你不需要读写的就绪文件描述符(有些fd有数据,但是你不处理那些fd),而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率,而边缘触发,则不会充斥大量你不关心的就绪文件描述符,从而性能差异,高下立见。
4、关于ET、LT两种工作模式
可以得出这样的结论:
ET模式仅当状态发生变化的时候才获得通知,这里所谓的状态的变化并不包括缓冲区中还有未处理的数据,也就是说,如果要采用ET模式,需要一直read/write直到出错为止,很多人反映为什么采用ET模式只接收了一部分数据就再也得不到通知了,大多因为这样;而LT模式是只要有数据没有处理就会一直通知下去的.
epoll中读写数据 的注意事项
在一个非阻塞的socket上调用read/write函数,返回EAGAIN或者EWOULDBLOCK(注:EAGAIN就是EWOULDBLOCK)。
从字面上看,意思是:
EAGAIN: 再试一次
EWOULDBLOCK:如果这是一个阻塞socket, 操作将被block
perror输出:Resource temporarily unavailable
总结:
这个错误表示资源暂时不够,可能read时, 读缓冲区没有数据, 或者write时,写缓冲区满了。
遇到这种情况,如果是阻塞socket、 read/write就要阻塞掉。而如果是非阻塞socket、 read/write立即返回-1, 同 时errno设置为EAGAIN。
所以对于阻塞socket、 read/write返回-1代表网络出错了。但对于非阻塞socket、read/write返回-1不一定网络真的出错了。可能是Resource temporarily unavailable。这时你应该再试,直到Resource available。
本文主要讲述epoll模型(不完全是针对epoll)下读写数据接口使用的注意事项
1、read write
函数原型如下:
ssize_t read(int filedes, void* buf, size_t nbytes)
ssize_t write(int filedes, const void* buf, size_t nbytes)
其中,read返回实际读取到的字节数。但实际读取的字节很有可能少于指定要读取的字节数nbytes。因此会分为:
①返回值大于0。 读取正常,返回实际读取到的字节数
②返回值等于0。 读取异常,读取到文件filedes结尾处了。这里逻辑上要理解为read已经读取完数据
③返回值小于0(-1)。 读取出错,在处理网络请求时可能是网络异常。着重注意当返回-1,此时errno的值EAGAIN、EWOULLDBLOCK,表示内核对应的读缓冲区为空
而write返回的实际写入字节数正常情况是与制定写入的字节数nbytes相同的,不相等说明写入异常了,着重注意,此时errno的值EAGAIN、EWOULLDBLOCK,表示内核对应的写缓冲区为空。注,EAGAIN等同于EWOULLDBLOCK。
总之,这个错误表示资源暂时不够,可能read时读缓冲区没有数据, 或者write时写缓冲区满了。遇到这种情况,如果是阻塞socket、 read/write就要阻塞掉。而如果是非阻塞socket、 read/write立即返回-1, 同时errno设置为EAGAIN。
所以对于阻塞socket、 read/write返回-1代表网络出错了。但对于非阻塞socket、read/write返回-1不一定网络真的出错了。可能支持缓冲区空或者满,这时应该再试,直到Resource available。
综上,对于非阻塞的socket,正确的读写操作为:
LT模式
读: 忽略掉errno = EAGAIN的错误,下次继续读;
写:忽略掉errno = EAGAIN的错误,下次继续写。
对于select和epoll的LT模式,这种读写方式是没有问题的。但对于epoll的ET模式,这种方式还有漏洞。
下面来介绍下epoll事件的两种模式LT(水平触发)和ET(边沿触发),根据可以理解为,文件描述符的读写状态发生变化才会触发epoll事件,具体说来如下:二者的差异在于 level-trigger 模式下只要某个 socket 处于 readable/writable 状态,无论什么时候进行 epoll_wait 都会返回该 socket;而 edge-trigger 模式下只有某个 socket 从 unreadable 变为 readable,或从unwritable 变为writable时,epoll_wait 才会返回该 socket。如下两个示意图:
从socket读数据:

往socket写数据:

所以在epoll的ET模式下,正确的读写方式为:
读: 只要可读, 就一直读,直到返回0,或者 errno = EAGAIN写:只要可写, 就一直写,直到数据发送完,或者 errno = EAGAIN
这里的意思是,对于ET模式,相当于我们要自己重写read和write,使其像”原子操作“一样,保证一次read 或 write能够完整的读完缓冲区的数据或者写完要写入缓冲区的数据。因此,实现为用while包住read和write即可。但是对于select或者LT模式,我们可以只使用一次read和write,因为在主程序中会一直while,而事件再下一次select时还会被获取到。但也可以实现为用while包住read和write。从逻辑上讲,一次性把数据读取完整可以保证数据的完整性。
下面来说明这种”原子操作“read和write
while(1)
{
nread = read(fd, buf + n, BUFSIZ - 1); //读时,用户进程指定的接收数据缓冲区大小固定,一般要比数据大
if(nread < 0)
{
if(errno == EAGAIN || errno == EWOULDBLOCK)
{
continue;
}
else
{
break; //or return;
}
}
else if(nread == 0)
{
break; //or return. because read the EOF
}
else
{
n += nread;
}
}
int data_size = strlen(buf);
int n = 0;
while(1)
{
nwrite = write(fd, buf + n, data_size);//写时,数据大小一直在变化
if(nwrite < data_size)
{
if(errno == EAGAIN || errno == EWOULDBLOCK)
{
continue;
}
else
{
break;//or return;
}
}
else
{
n += nwrite;
data_size -= nwrite;
}
}
正确的accept,accept 要考虑 2 个问题:
(1) LT模式下或ET模式下,阻塞的监听socket, accept 存在的问题
accept每次都是从已经完成三次握手的tcp队列中取出一个连接,考虑这种情况: TCP 连接被客户端夭折,即在服务器调用 accept 之前,客户端主动发送 RST 终止连接,导致刚刚建立的连接从就绪队列中移出,如果套接口被设置成阻塞模式,服务器就会一直阻塞在 accept 调用上,直到其他某个客户建立一个新的连接为止。但是在此期间,服务器单纯地阻塞在accept 调用上,就绪队列中的其他描述符都得不到处理。
解决办法是:把监听套接口设置为非阻塞,当客户在服务器调用 accept 之前中止某个连接时,accept 调用可以立即返回 -1, 这时源自 Berkeley 的实现会在内核中处理该事件,并不会将该事件通知给 epoll,而其他实现把 errno 设置为 ECONNABORTED 或者 EPROTO 错误,我们应该忽略这两个错误。
(2) ET 模式下 accept 存在的问题
考虑这种情况:多个连接同时到达,服务器的 TCP 就绪队列瞬间积累多个就绪连接,由于是边缘触发模式,epoll 只会通知一次,accept 只处理一个连接,导致 TCP 就绪队列中剩下的连接都得不到处理。
解决办法是:将监听套接字设置为非阻塞模式,用 while 循环抱住 accept 调用,处理完 TCP 就绪队列中的所有连接后再退出循环。如何知道是否处理完就绪队列中的所有连接呢? accept 返回 -1 并且 errno 设置为 EAGAIN 就表示所有连接都处理完。
综合以上两种情况,服务器应该使用非阻塞地 accept, accept 在 ET 模式下 的正确使用方式为:
(size_t *)&addrlen)) > 0) {
handle_client(conn_sock);
}
if (conn_sock == -1) {
if (errno != EAGAIN && errno != ECONNABORTED
&& errno != EPROTO && errno != EINTR)
perror("accept");
}
一道腾讯后台开发的面试题:
使用Linux epoll模型,水平触发模式;当socket可写时,会不停的触发 socket 可写的事件,如何处理?
- 第一种最普遍的方式:
需要向 socket 写数据的时候才把 socket 加入 epoll ,等待可写事件。接受到可写事件后,调用 write 或者 send 发送数据。当所有数据都写完后,把 socket 移出 epoll。
这种方式的缺点是,即使发送很少的数据,也要把 socket 加入 epoll,写完后在移出 epoll,有一定操作代价。
- 一种改进的方式:
开始不把 socket 加入 epoll,需要向 socket 写数据的时候,直接调用 write 或者 send 发送数据。如果返回 EAGAIN,把 socket 加入 epoll,在 epoll 的驱动下写数据,全部数据发送完毕后,再移出 epoll。
这种方式的优点是:数据不多的时候可以避免 epoll 的事件处理,提高效率。
多路复用
如文初的说明表示,这三者都是 I/O 多路复用机制,且简要介绍了多路复用的定义,那么如何更加直观地了解多路复用呢?这里有张图:
对于网页服务器 Nginx 来说,会有很多连接进来, epoll 会把他们都监视起来,然后像拨开关一样,谁有数据就拨向谁,然后调用相应的代码处理。
一般来说以下场合需要使用 I/O 多路复用:
- 当客户处理多个描述字时(一般是交互式输入和网络套接口)
- 如果一个服务器既要处理 TCP,又要处理 UDP,一般要使用 I/O 复用
- 如果一个 TCP 服务器既要处理监听套接口,又要处理已连接套接口
为什么epoll可以支持百万级别的连接?
- 在server的处理过程中,大家可以看到其中重要的操作是,使用epoll_ctl修改clientfd在epoll中注册的epoll_event, 这个操作首先在红黑树中找到fd对应的epoll_event, 然后进行修改,红黑树是典型的二叉平衡树,其时间复杂度是log2(n), 1百万的文件句柄,只需要16次左右的查找,速度是非常快的,支持百万级别毫无压力
- 另外,epoll通过注册fd上的回调函数,回调函数监控到有事件发生,则准备好相关的数据放到到就绪链表里面去,这个动作非常快,成本也非常小
socket读写返回值的处理
在调用socket读写函数read(),write()时,都会有返回值。如果没有正确处理返回值,就可能引入一些问题
总结了以下几点
1当read()或者write()函数返回值大于0时,表示实际从缓冲区读取或者写入的字节数目
2当read()函数返回值为0时,表示对端已经关闭了 socket,这时候也要关闭这个socket,否则会导致socket泄露。netstat命令查看下,如果有closewait状态的socket,就是socket泄露了
当write()函数返回0时,表示当前写缓冲区已满,是正常情况,下次再来写就行了。
3当read()或者write()返回-1时,一般要判断errno
如果errno == EINTR,表示系统当前中断了,直接忽略
如果errno == EAGAIN或者EWOULDBLOCK,非阻塞socket直接忽略;如果是阻塞的socket,一般是读写操作超时了,还未返回。这个超时是指socket的SO_RCVTIMEO与SO_SNDTIMEO两个属性。所以在使用阻塞socket时,不要将超时时间设置的过小。不然返回了-1,你也不知道是socket连接是真的断开了,还是正常的网络抖动。一般情况下,阻塞的socket返回了-1,都需要关闭重新连接。
4.另外,对于非阻塞的connect,可能返回-1.这时需要判断errno,如果 errno == EINPROGRESS,表示正在处理中,否则表示连接出错了,需要关闭重连。之后使用select,检测到该socket的可写事件时,要判断getsockopt(c->fd, SOL_SOCKET, SO_ERROR, &err, &errlen),看socket是否出错了。如果err值为0,则表示connect成功;否则也应该关闭重连
5 在使用epoll时,有ET与LT两种模式。ET模式下,socket需要read或者write到返回-1为止。对于非阻塞的socket没有问题,但是如果是阻塞的socket,正如第三条中所说的,只有超时才会返回。所以在ET模式下千万不要使用阻塞的socket。那么LT模式为什么没问题呢?一般情况下,使用LT模式,我们只要调用一次read或者write函数,如果没有读完或者没有写完,下次再来就是了。由于已经返回了可读或者可写事件,所以可以保证调用一次read或者write会正常返回。
nread为-1且errno==EAGAIN,说明数据已经读完,设置EPOLLOUT。
网络状态查询命令
sar、iostat、lsof
问题记录
客户端
1、Cannot assign requested address

大致上是由于客户端频繁的连服务器,由于每次连接都在很短的时间内结束,导致很多的TIME_WAIT,以至于用光了可用的端 口号,所以新的连接没办法绑定端口,即“Cannot assign requested address”。是客户端的问题不是服务器端的问题。通过netstat,的确看到很多TIME_WAIT状态的连接。
client端频繁建立连接,而端口释放较慢,导致建立新连接时无可用端口。
tcp 0 0 e100069210180.zmf:49477 e100069202104.zmf.tbs:websm TIME_WAIT
tcp 0 0 e100069210180.zmf:49481 e100069202104.zmf.tbs:websm TIME_WAIT
tcp 0 0 e100069210180.zmf:49469 e100069202104.zmf.tbs:websm TIME_WAIT
……
解决办法
执行命令修改如下内核参数 (需要root权限)
- 调低端口释放后的等待时间,默认为60s,修改为15~30s:
sysctl -w net.ipv4.tcp_fin_timeout=30
- 修改tcp/ip协议配置, 通过配置/proc/sys/net/ipv4/tcp_tw_resue, 默认为0,修改为1,释放TIME_WAIT端口给新连接使用:
sysctl -w net.ipv4.tcp_timestamps=1
- 修改tcp/ip协议配置,快速回收socket资源,默认为0,修改为1:
sysctl -w net.ipv4.tcp_tw_recycle=1
- 允许端口重用:
sysctl -w net.ipv4.tcp_tw_reuse = 1
2、2.8万左右的链接,报错误(可能端口用尽)
如果没有TIME_WAIT 状态的连接,那有可能端口用尽,特别是长连接的时候,查看开放的端口范围:
net.ipv4.ip_local_port_range = 32768 60999
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.eth0.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
[root@VM_0_8_centos usr]#
60999 - 32768 = 28,231,刚好2.8万,长连接把端口用光了。修改端口开放范围:
vi /etc/sysctl.conf net.ipv4.ip_local_port_range = 10000 65535
执行sysctl -p 使得生效
服务端
影响链接不往上走的原因:
1、端口用完了 (客户端,
查看端口范围sysctl -a |grep port_range,返回:net.ipv4.ip_local_port_range = 32768 60999,所以可用端口是60999-32768 =2.8w )
2、文件fd用完了
3、内存用完了
4、网络
5、配置:fsfile-max = 1048576 #文件fd的最大值,
fd=open(),fd从3开始,0:stdin标准输入1:stdout标准输出 2:stderr错误输出
Epoll 难以解决的问题
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); 还是要从这个api说起,这个api 可以监听很多个fd,但是timeout 只有一个。 有这一个场景: 你想关注 fd == 10的这个描述符,你希望该描述符有数据到来的时候通知你,并且,如果一直没有数据来,那么希望20s之后能通知你。 你改怎么做?
进一步假设,你希望关注 100 个fd, 并希望这个一百个fd,从他们加入监听队列的时候开始计算,20s后通知你超时
如果使用这个epoll_wait的话,是不是要自己记住所有fd的剩余超时时间呢?
libevent就解决了这个困扰。
配置和调试
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout 修改系默认的 TIMEOUT 时间
优化time_wait为啥要开syncookie呢? syncookie可以绕过seq queue的限制,跟优化time_wait没有关系
另外得打开timestamps,才能让reuse、recycle生效。
修改fin_timeout,如何调?调大调小呢?
//测试数据
单线程,峰值处理链接,貌似目前测试条件可以测试到2.9K
CONNECT: 2.9K/s
QPS : 27.6万
5万的链接。
QPS : 1.9万
客户端、服务端支持多少连接
客户端
现在我们终于可以得出更为正确的结论了,对于有1个Ip的客户端来说,受限于ip_local_port_range参数,也受限于65535。但单Linux可以配置多个ip,有几个ip,最大理论值就翻几倍
多张网卡不是必须的。即使只有一张网卡,也可以配置多ip。k8s就是这么干的,在k8s里,一台物理机上可以部署多个pod。但每一个pod都会被分配一个独立的ip,所以完全不用担心物理机上部署了过多的pod而影响你用的pod里的TCP连接数量。在ip给你的那一刻,你的pod就和其它应用隔离开了。
服务器端
一条TCP连接如果不发送数据的话,消耗内存是3.3K左右。如果有数据发送,需要为每条TCP分配发送缓存区,大小受你的参数net.ipv4.tcp_wmem配置影响,默认情况下最小是4K。如果发送结束,缓存区消耗的内存会被回收。
假设你只保持连接不发送数据,那么你服务器可以建立的连接最大数量 = 你的内存/3.3K。 假如是4GB的内存,那么大约可接受的TCP连接数量是100万左右。
这个例子里,我们考虑的前提是在一个进程下hold所有的服务器端连接。而在实际中的项目里,为了收发数据方便,很多网络IO模型还会为TCP连接再创建一个线程或协程。拿最轻量的golang来说,一个协程栈也需要2KB的内存开销。
结论
- TCP连接的客户端机:每一个ip可建立的TCP连接理论受限于ip_local_port_range参数,也受限于65535。但可以通过配置多ip的方式来加大自己的建立连接的能力。
- TCP连接的服务器机:每一个监听的端口虽然理论值很大,但这个数字没有实际意义。最大并发数取决你的内存大小,每一条静止状态的TCP连接大约需要吃3.3K的内存。
select、poll、epoll之间的区别(搜狗面试)
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
select:
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。
一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
poll:
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
epoll:
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无 论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll为什么要有EPOLLET触发模式?
如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边沿触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
select、poll、epoll 区别总结:
1、支持一个进程所能打开的最大连接数
select
单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
poll
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的
epoll
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接
2、FD剧增后带来的IO效率问题
select
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll
同上
epoll
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3、 消息传递方式
select
内核需要将消息传递到用户空间,都需要内核拷贝动作
poll
同上
epoll
epoll通过内核和用户空间共享一块内存来实现的。
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
今天对这三种IO多路复用进行对比,参考网上和书上面的资料,整理如下:
1、select实现
select的调用过程如下所示:

(1)使用copy_from_user从用户空间拷贝fd_set到内核空间
(2)注册回调函数__pollwait
(3)遍历所有fd,调用其对应的poll方法(对于socket,这个poll方法是sock_poll,sock_poll根据情况会调用到tcp_poll,udp_poll或者datagram_poll)
(4)以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。
(5)__pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。在设备收到一条消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时current便被唤醒了。
(6)poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。
(7)如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
(8)把fd_set从内核空间拷贝到用户空间。
总结:
select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024
2 poll实现
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构,其他的都差不多,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
3、epoll
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
-
Linux--IO多路复用(select,poll,epoll)2024-11-06 2244
-
教你如何区别select、poll、epoll?2023-11-21 5357
-
epoll源码分析2023-11-13 2312
-
epoll的基础数据结构2023-11-10 1921
-
epoll 的实现原理2023-11-09 1568
-
揭示EPOLL一些原理性的东西2022-08-24 1498
-
epoll LT和ET方式下的读写差别2022-07-07 3154
-
epoll使用方法与poll的区别2019-07-31 2381
-
Linux中epoll IO多路复用机制2019-05-16 1017
-
poll&&epoll之epoll实现2019-05-14 3320
-
我读过的最好的epoll讲解2018-05-12 9212
-
epoll的使用2018-05-11 2926
-
epoll和select的区别2017-11-10 23233
全部0条评论

快来发表一下你的评论吧 !
