

为什么需要分布式共识算法
描述
分布式共识算法
首先我们先明确这个问题:为什么需要分布式共识算法?
这就要从当前的分布式系统设计的缺陷来看了,假设我们的集群现在有两个客户端和三个服务端,如下图:

在这个分布式系统的设计中,往往要满足CAP理论,而分布式共识算法解决的就是CAP理论中的一致性问题。整个一致性问题分为三种问题:
- 顺序一致性
- 线性一致性
- 因果一致性
顺序一致性
顺序一致性是1979年Lamport 在论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs 》中提出::假设执行结果与这些处理器以某一串行顺序执行的结果相同,同时每个处理器内部操作的执行看起来又与程序描述的顺序一致。满足该条件的多处理器系统我们就认为是顺序一致的。实际上,处理器可以看做一个进程或者一个线程,甚至是一个分布式系统。
这句话并不是很好理解,我们看一下分布式系统中顺序一致性的一个例子:
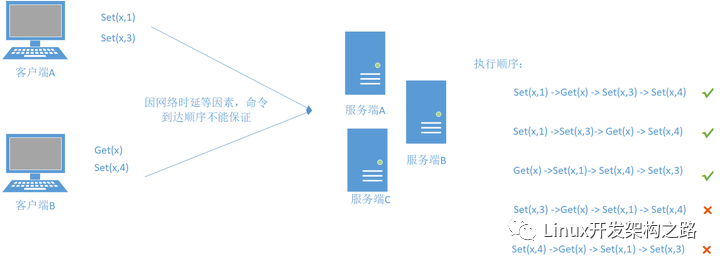
假设客户端A有两条命令:
command2:set(x,3)
客户端B有一下两条命令:
command4:set(x,4)
那么如果服务端那边收到的节点只要满足command2在command1后面执行并且comand4在command3后面执行我们就认为其满足顺序一致性。
线性一致性
线性一致性或称原子一致性或严格一致性,指的是程序在执行顺序组合中存在可线性化点P的执行模型,这意味着一个操作将在程序的调用和返回之间的某个点P生效,之后被系统中并发运行的所有其他线程所感知。线性一致性概念是1990年 Maurice Herlihy · Jeannette M Wing 在论文《Linearizability: A Correctness Condition for Concurrent Objects》中提出。
通俗来讲,线性一致性可以说是顺序一致性的升级版。其会有一个全局时钟,假设还是上面发送的命令,只不过加上了时间信息:
客户端A发送的命令如下:
[14:02]command2:set(x,3)
客户端B发送的命令如下:
[14:04]command4:set(x,4)
注:这里假设时延可能是几分钟级别的,所以有可能是command3在command1之前到
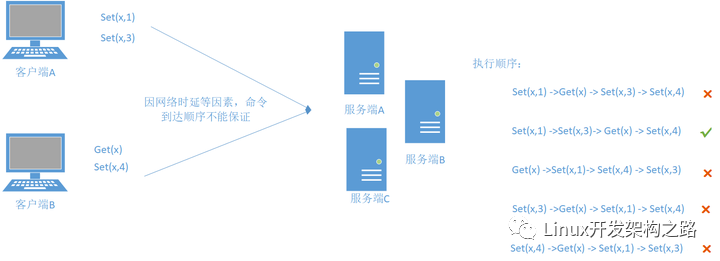
所以,假设初始值x = 0,而我们到达的顺序如下:
command1->command3->command4->command2
...
这个顺序确实是满足顺序一致性,但是我们get(x)获得的值可谓是千奇百怪,可能是0,1,3 。为了解决顺序一致性的不足,所以才提出的线性一致性。其要求命令满足全局时钟的时序性。所以很容易就知道,满足线性一致性的一定满足顺序一致性;相反,满足顺序一致性的不一定会满足线性一致性。
因果一致性
线性一致性要求所有线程的操作按照一个绝对的时钟顺序执行,这意味着线性一致性是限制并发的,否则这种顺序性就无法保证。由于在真实环境中很难保证绝对时钟同步,因此线性一致性是一种理论。实现线性一致性的代价也最高,但是实战中可以弱化部分线性一致性:只保证有因果关系的事件的顺序,没有因果关系的事件可以并发执行,其指的是假设有两个事件:A事件和B事件,如果A发生在B后面,那么就称A和B具有因果关系。
Raft 算法
Paxos和Raft这些分布式共识算法就是用来多个节点之间达成共识的,其可以解决一定的一致性问题。其中Paxos难以理解,所以这篇博客以介绍Raft算法为主。
Raft是工程上使用较为广泛的强一致性、去中心化、高可用的分布式协议。遵从此协议的分布式集群会对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。
原理概览
遵循Raft算法的分布式集群中每个节点扮演以下三种角色之一:
- leader:领导者,其负责和客户端通信,接收来自客户端的命令并将其转发给follower
- follower:跟随者,其一丝不苟的执行来自leader的命令
- candidate:候选者,当follower长时间没收到 leader的消息就会揭竿而起成为候选者,抢夺成为leader的资格
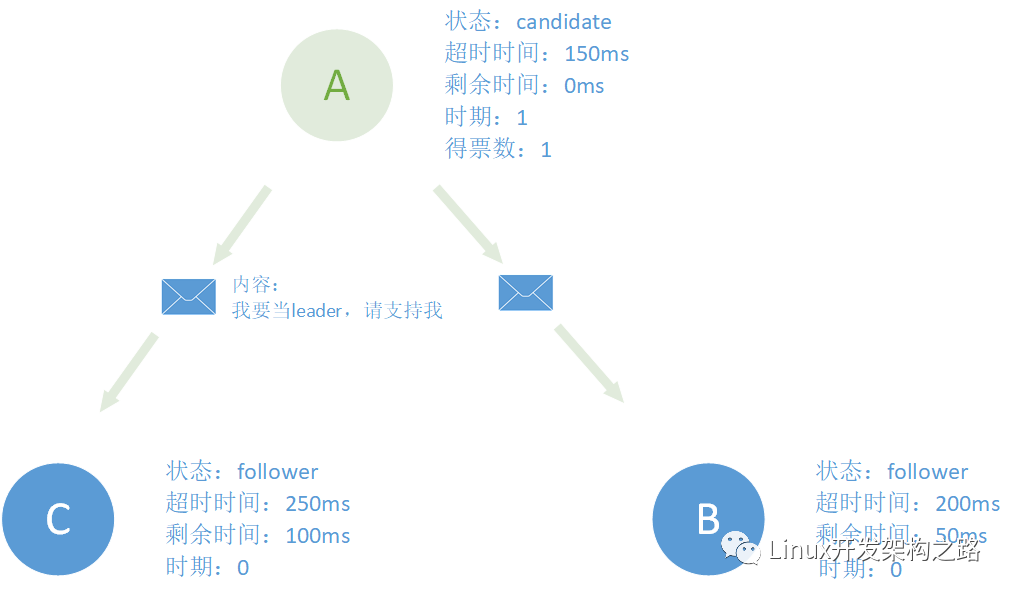
从上面的描述我们可以看到节点的角色不是固定的,其会在三个角色中转换。我们举个例子来说,假设我们有三个节点A、B、C,它们的基本信息如下图中。一开始所有的节点都是follower状态,并且处于时期0这个状态。

注:在Raft算法中,所有节点会被分配不同的超时时间,时间限定在150ms~300ms之间。为什么这么设置是因为如果设置相同的超时时间就会导致所有节点同时过期会导致迟迟选不出leader,看到后面就会明白。
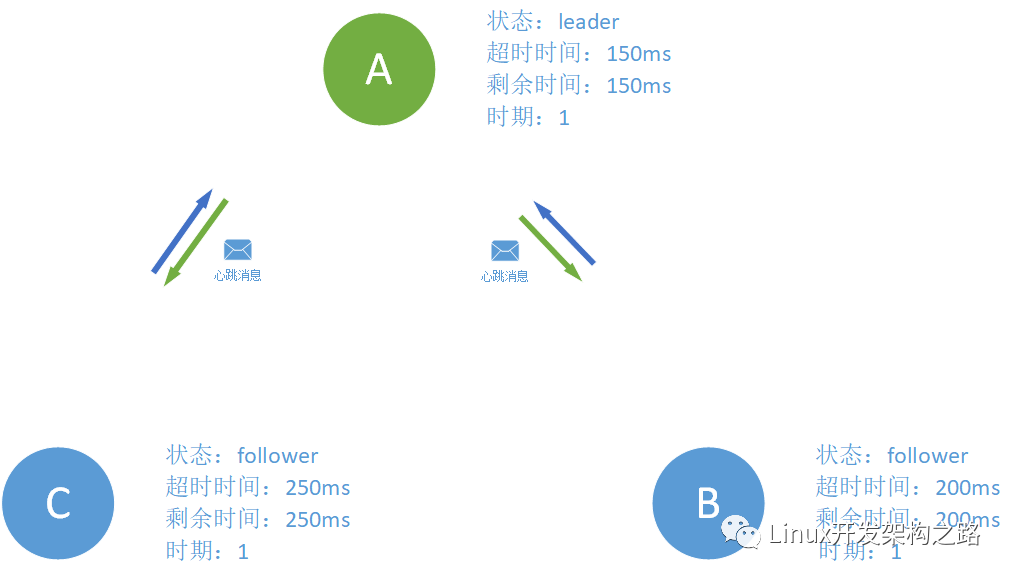
150ms过去之后,A发现怎么leader没跟我联络联络感情,是不是leader已经寄了?王侯将相宁有种乎!于是A成为候选人给自己投了一票并开创自己的时代时期 1,并给其他还没过期的follower发送信息请求它们支持自己当leader。
节点B和C在收到来自A的消息之后,又没有收到其他要求称王者的信息,于是就选择支持A节点,加入A的时代并刷新自己的剩余时间。
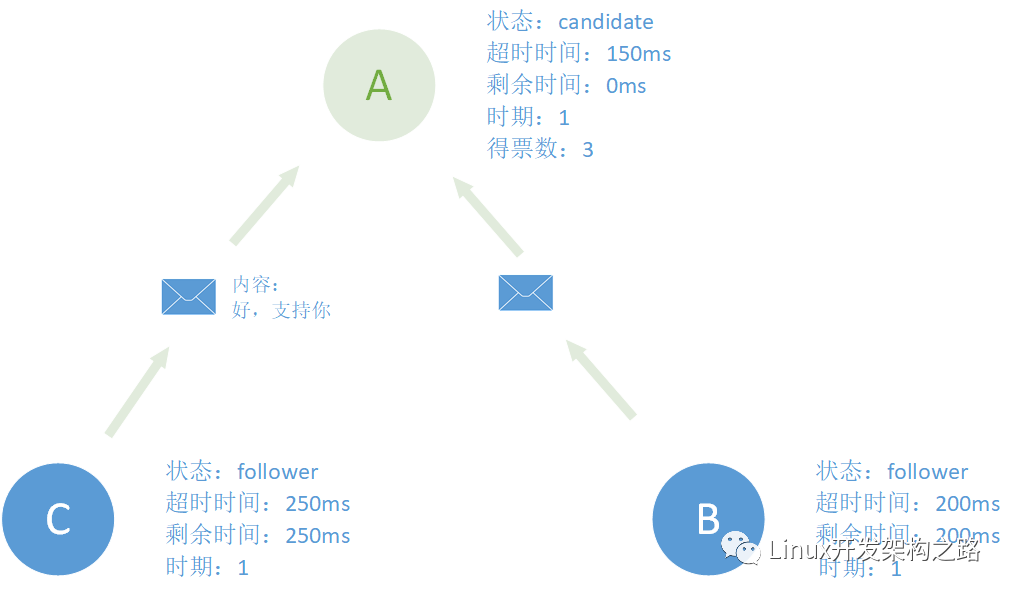
之后 A得到了超过一半的节点支持,成为leader,并定时给B和C联络联络感情(心跳信息)目的是防止有节点因为长时间收不到开始反叛成candidate。
之后整个分布式集群就可以和客户端开始通信了,客户端会发送消息给leader,之后leader会保证集群的一致性并且当整个集群中的一半节点都完成客户端发送的命令之后才会真正的返回给客户端,表示完成此次命令。
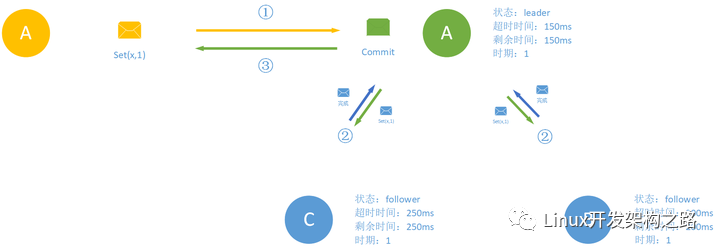
但是这只是个概况,我们还缺了亿点点细节:
- 选举机制
- 日志复制
选举机制
刚刚我们讲了最普通的一个选举过程,但是我们可能还会遇到一些特殊情况:
- 新加入节点
- leader 掉线
- 多个follower同时超时
新节点加入
当有一个节点加入当前的分布式集群的时候,leader会检测并发现它并给他发送消息。使其加入此分布式集群。
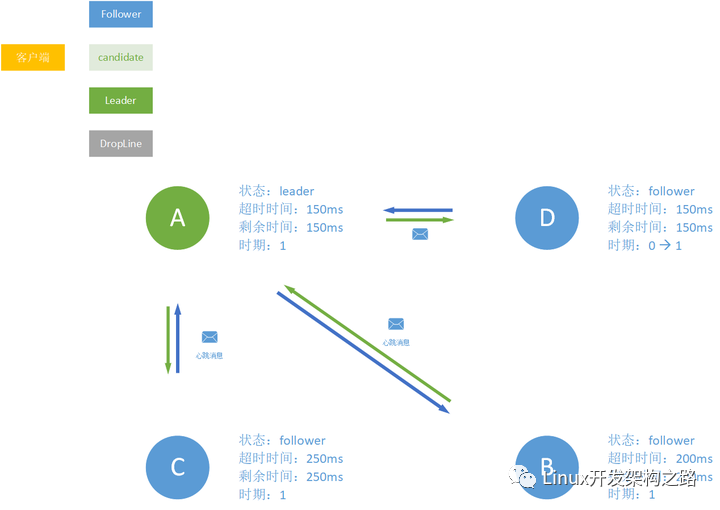
leader 掉线处理
假设我们现在的服务器A掉线,由于没有leader维持心跳消息,这个时候服务器B和C会进入超时倒计时的状态。

200ms过去,服务器B开始超时了,这个时候它揭竿而起成为candidate,并向节点C发送消息请求其支持自己成为leader。
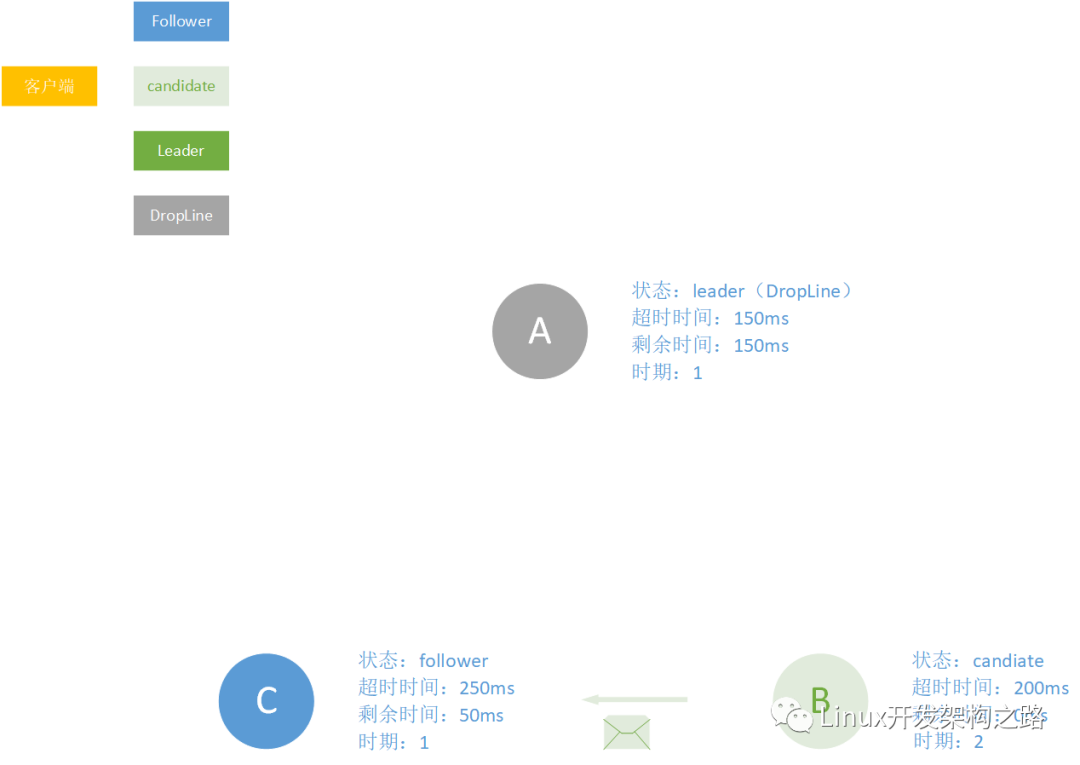
之后,在一系列判断条件之后(后面会讲),节点C会回复节点B的请求信息。插句题外话哈,在B还没收到C的回复消息之前,假设A只是刚刚网络不通畅,现在死而复生,给B发送消息了。那么B发现A的时期比自己落后了,这还等什么?!苍天已死,黄天当立,之后反手将其收为小弟。
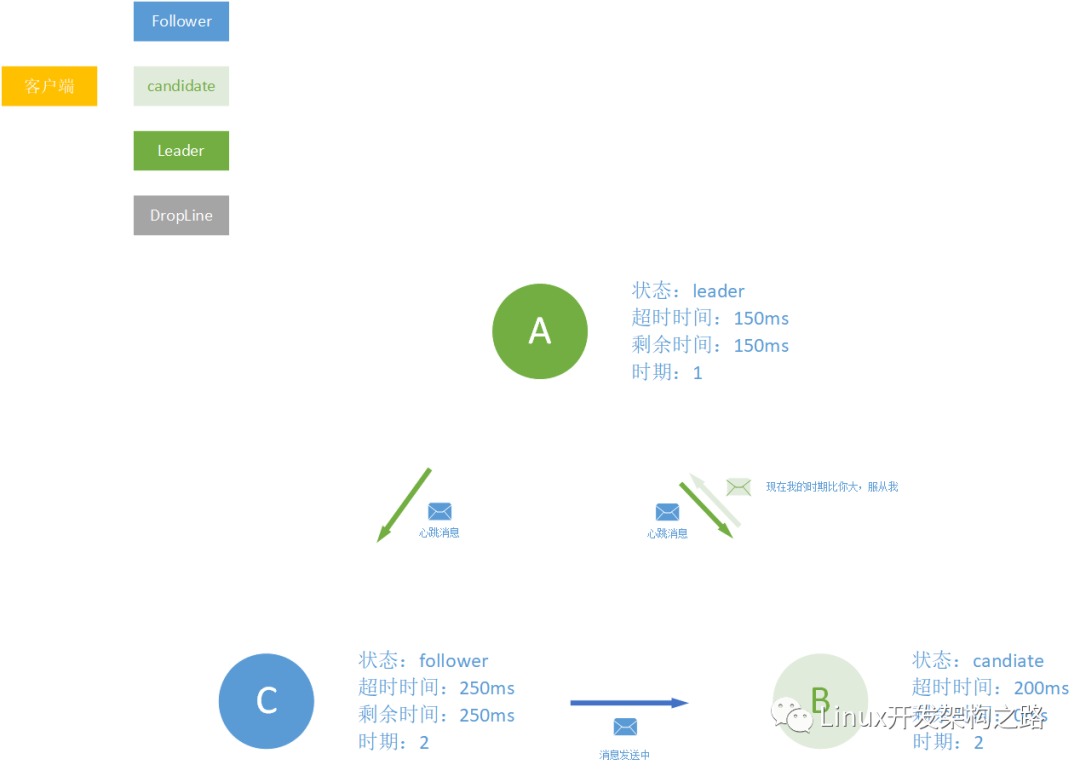
之后节点B顺利成为leader。
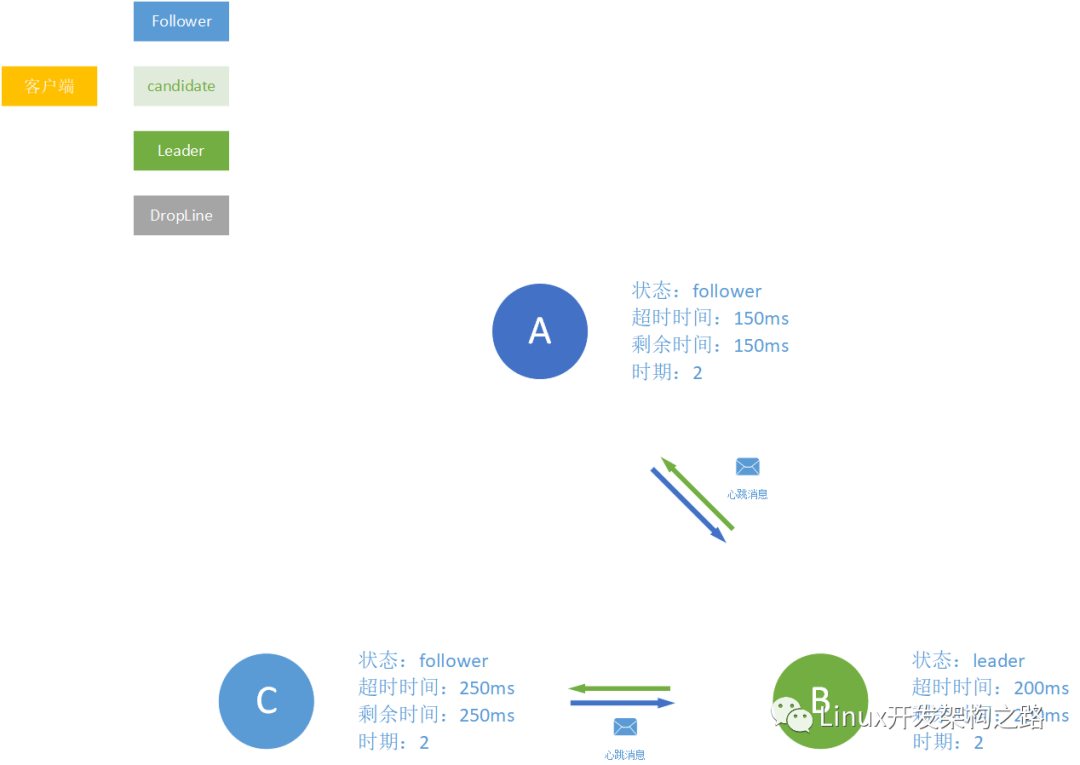
多个 follower 同时掉线
现在假设有4个节点:A、B、C、D。其中A和D的超时时间是相同的。
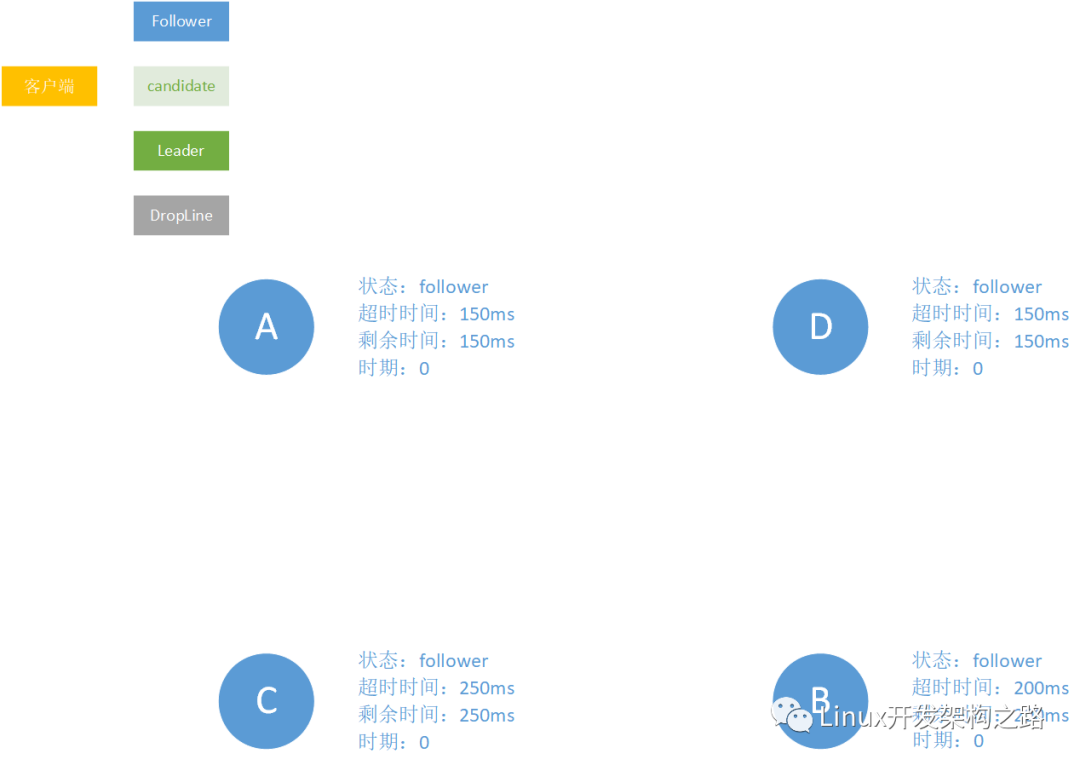
150ms过后,A和D同时成为candidate,争相为了成为leader给B和C发消息。
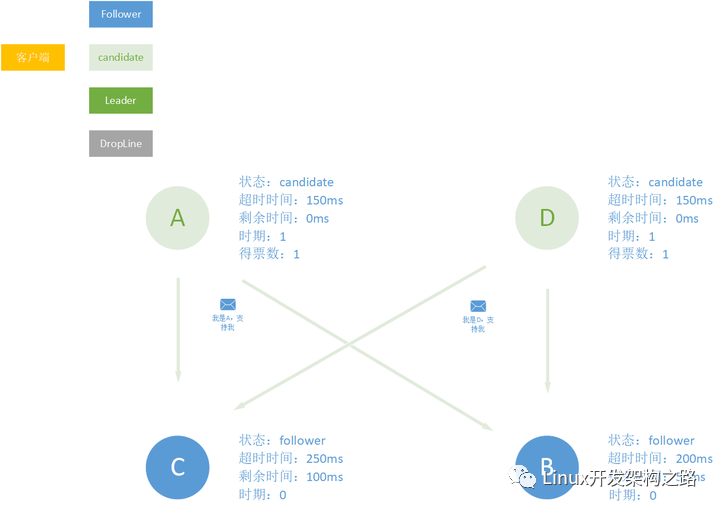
这个时候有对于B和C有两个选择,一个是它们一起支持两个中的一次,也就是要么支持A要么支持D,这样这样其中一个就会成为leader,我们假设它们两个都支持A。
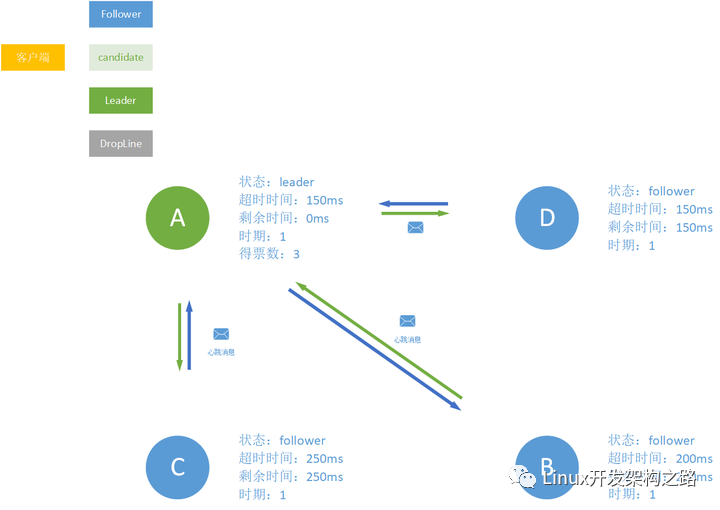
另外一种选择就是,A和D各的一票支持,它们的支持者跟进它们各自的leader的时期,然后本轮选举结束。

之后50ms过去之后,B的超时时间过期了,其获得candiate的资格,这个时候其会向其他follower发送消息请求支持。
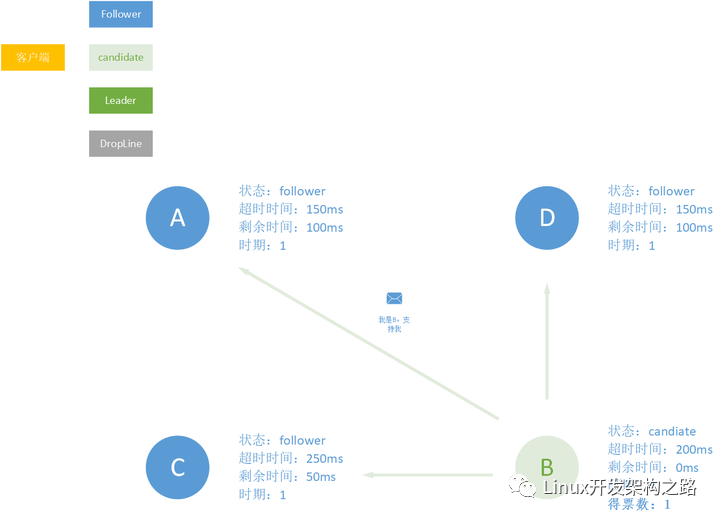
之后A、B、D 因为当前的B也没有支持者,所以就会支持B,B顺利成为leader。
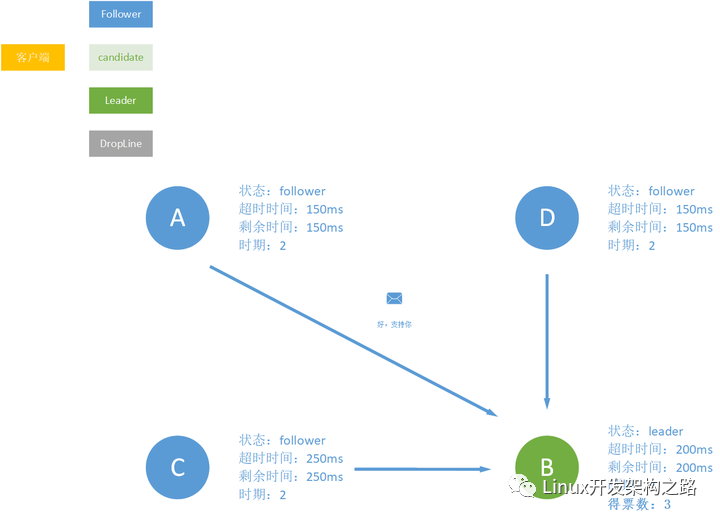
日志复制
当我们的集群leader 选举之后。Leader 接收所有客户端请求,然后转化为 log 复制命令,发送通知其他节点完成日志复制请求。每个日志复制请求包括状态机命令 & 任期号,同时还有前一个日志的任期号和日志索引。状态机命令表示客户端请求的数据操作指令,任期号表示 leader 的当前任期,任期也就是上图中的时期。
而当follower 收到日志复制命令会执行处理流程:
1、follower 会使用前一个日志的任期号和日志索引来对比自己的数据:
- 如果相同,接收复制请求,回复 ok;
- 否则回拒绝复制当前日志,回复 error;
2、leader 收到拒绝复制的回复后,继续发送节点日志复制请求,不过这次会带上更前面的一个日志任期号和索引;
3、如此循环往复,直到找到一个共同的任期号&日志索引。此时 follower 从这个索引值开始复制,最终和 leader 节点日志保持一致;
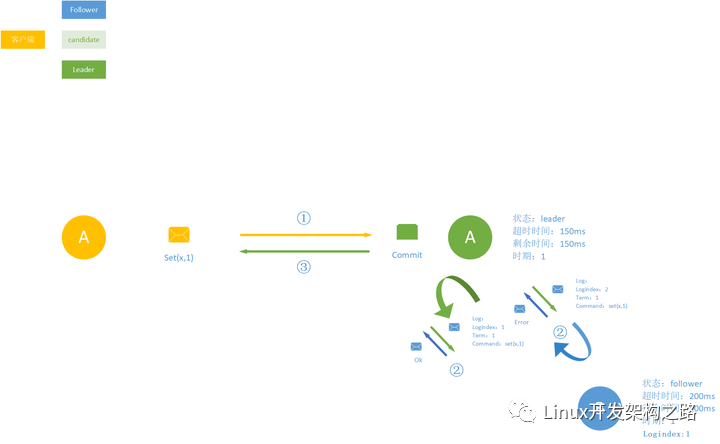
日志复制过程中,Leader 会无限重试直到成功。如果超过半数的节点复制日志成功,就可以任务当前数据请求达成了共识,即日志可以 commite 提交了;
注:这里要提到的一点就是,如果follower发现canidate的日志还没有自己的新(索引号没自己大),其是不会支持其成为leader的。
-
分布式软件系统2009-07-22 5365
-
分布式系统的优势是什么?2020-03-31 3118
-
求一种基于FPGA分布式算法的滤波器设计的实现方案2021-04-29 1861
-
请问一下基于分布式算法的FIR滤波器怎么实现2021-04-30 1490
-
如何设计基于分布式算法的FIR滤波器?2021-05-08 2224
-
各种分布式电源的电气特性2021-07-12 2017
-
基于DSP的分布式并行遗传算法2009-05-08 446
-
分布式协同过滤推荐算法2017-12-20 996
-
Spark分布式下的模糊C均值算法2017-12-23 862
-
区块链共识算法全面详解2019-01-04 16311
-
快速在线分布式对偶平均优化算法2019-01-22 1474
-
区块链的共识算法是什么共有哪些类型2019-03-12 6333
-
区块链的真正价值是实现高效有序的大规模分布式协作2019-09-01 2356
-
基于分布式编码的同步随机梯度下降算法2021-04-27 936
-
深入理解分布式共识算法 Raft2025-11-27 444
全部0条评论

快来发表一下你的评论吧 !
