

LLM作用下的成分句法分析基础研究
描述
作者:cola
自训练已被证明是一种有效的针对跨域任务的方法。传统的自训练方法依赖于有限且低质量的源语料库。为克服这一限制,本文提出用大型语言模型(LLM)增强自训练,以迭代地生成特定领域的语料库。并针对句法成分解析,引入了指导LLM生成源语料库的语法规则,建立了选择伪实例的标准。
背景介绍
成分解析作为NLP中的一项基本任务,已经在领内基准上取得了显著的进展,这表明解析器在捕获底层语法结构方面的能力日益增强。然而,开放域句法成分解析具仍具有挑战。在不同的开放域中,成分解析面临的复杂性超出了定义明确的任务。解决这些挑战对于其现实世界的NLP应用至关重要。
为了解决域偏移问题,基于自训练的无监督域适应已经成为一种有效的方法。例如在每次迭代过程中利用源域模型自动标注来自目标域的大规模源语料,然后选择置信度高的伪数据作为额外的训练数据,以提高目标域性能。然而,在低资源领域,源语料库的质量和数量往往无法保证,这限制了自训练方法的使用。而LLM具有强大的生成能力,可以作为解决目标域源语料库数量和质量挑战的潜在解决方案。
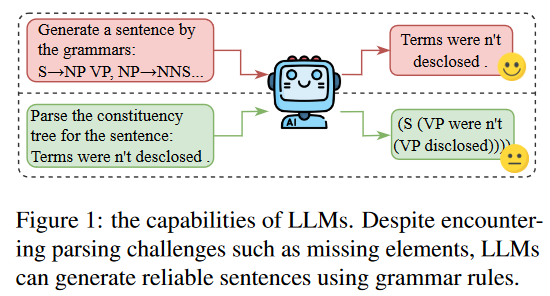
在生成句子时解决LLM的灵活性和幻觉问题面临挑战,我们采用语法规则作为LLM生成目标域句子的指令。语法规则与句法成分解析密切相关。
方法
采用伯克利神经解析器(Berkeley Neural Parser)作为方法的基础。该解析器是一种基于图表的方法,采用自注意力编码器和图表解码器,利用预训练的嵌入作为输入来增强解析过程。由于融合了预训练语言模型,伯克利神经解析器天生具有跨域句法分析能力。这使得解析器可以在源域上进行训练,可直接应用于目标域。
自训练
自训练的主要目标是为目标域生成高质量的训练实例,然后使用这些实例训练目标域模型。具体来说,在基础方法的每次迭代中,都进行了三个主要步骤:
训练解析器:使用源域成分树训练伯克利神经解析器。
解析源语料库:用训练好的模型来解析来自目标域的源文本,生成解析树,作为下一步的候选伪树。
伪数据选择:选择高置信度的伪树作为额外的训练实例,然后用于增强模型在目标域上的性能。
通过迭代地重复这些步骤,自训练方法使解析器适应目标域,利用源注释树生成高质量的伪树。
LLM增强自训练
如图2所示,动态嵌入LLM作为迭代自训练过程中的一个关键组件。在每次迭代中,我们基于上一步更新的树,利用LLM为目标域生成源语料库。语法规则(GRs)从树中提取,对指导目标域源语料的LLMs生成起着至关重要的作用。
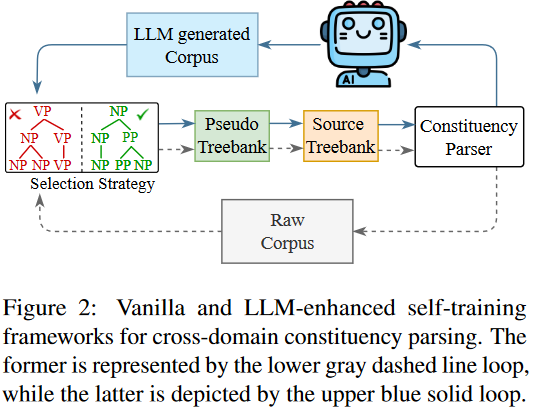
在每次迭代中,LLM增强的自训练句法成分解析可划分为6个详细步骤:
LLM生成:利用LLM为目标域生成一个源语料库。
解析训练:用源树库和目标域选择的伪树来训练成分解析器。初始化时,伪树为空,解析器仅在源域数据上进行训练。
域解析:我们用训练过的解析器来解析生成的源语料库,产生一组候选解析树。
树的选择:从生成的解析树中,选择一个高质量解析树的子集来组成伪树库。
更新树库:通过添加选定的伪树库来更新源树库。
GRs抽取:从更新的树库中抽取语法规则。
LLM增强的自训练过程不断迭代,直到收敛。
实例选择
本文提出了一种基于语法规则的伪数据选择准则。与之前仅关注任务的自训练选择标准不同,该标准同时考虑了任务和LLM 生成语料库的特征,确保所选择的伪数据适用于使用自训练的跨域解析。
给定源集和候选实例(候选集),与之间的距离为: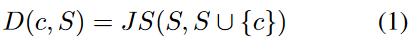 然后,在自训练过程中选择最接近源域集的前个候选集作为额外的训练实例。
然后,在自训练过程中选择最接近源域集的前个候选集作为额外的训练实例。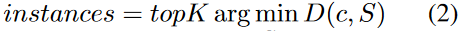 距离计算可以在token级进行,也可以在语法规则级进行,通过调整集合来分别表示token分布和语法规则分布。实例选择过程包含三个层次的标准:token、置信度和语法规则。并结合两个表现最好的标准,即基于置信度的选择和基于语法规则的选择,从而产生了一个更有效的标准,用于识别高质量实例以适应目标领域。
距离计算可以在token级进行,也可以在语法规则级进行,通过调整集合来分别表示token分布和语法规则分布。实例选择过程包含三个层次的标准:token、置信度和语法规则。并结合两个表现最好的标准,即基于置信度的选择和基于语法规则的选择,从而产生了一个更有效的标准,用于识别高质量实例以适应目标领域。
LLM提示
为了生成包含全面结构信息并与目标域句子风格密切相似的句子,本文提出了一个融合语法规则和目标域示例的LLM提示。在生成过程中,我们需要准备以下参数:1)从树库中提取的条语法规则,2)从目标领域中采样的个句子,3)生成句子的长度约束。
通过从树库句子长度的分布中采样来确定的值,并从中提取语法规则。注意,语法规则是直接从成分树中提取的,其中父节点对应于语法规则的左侧,所有子节点对应于右侧尾部。例如,如果树库是源域数据PTB,我们为平均长度引入高斯分布,记为,以获得条语法规则。
我们抽取了5个目标域句子。由于生成的句子的长度与语法规则数量密切相关,因此使用另一种正态分布来采样两个值和,这两个值定义了生成句子的长度限制。图3给出了一个具体的例子:

实验
数据:PTB-源数据,MCTB-目标数据。
主要结果
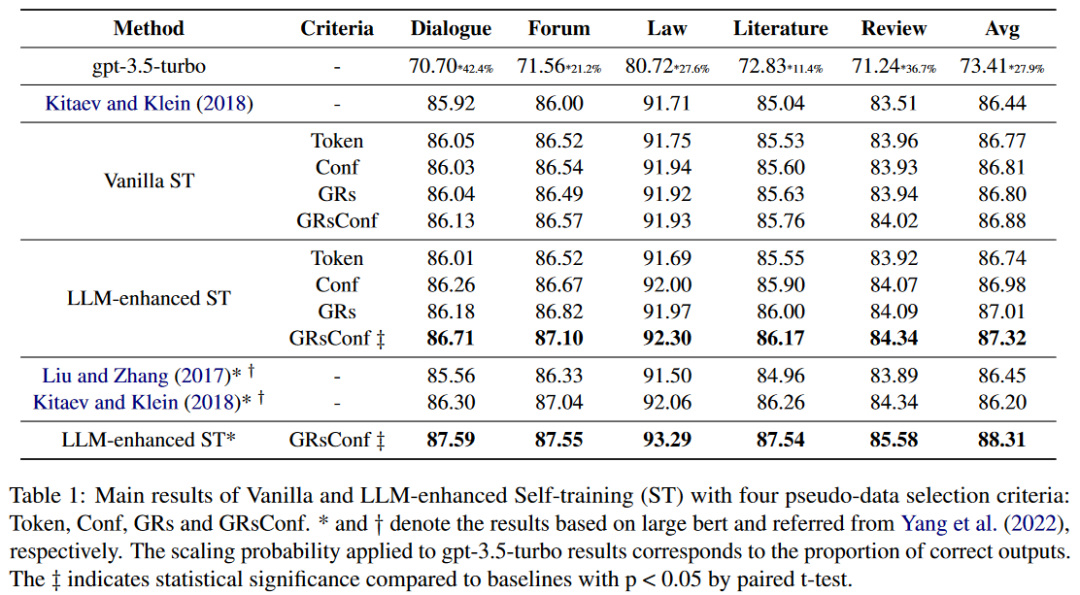
为方便起见,主要的对比实验采用bert-base-uncased进行,仅在bert-large-uncased上进行比较。表1报告了句法成分解析器在五个目标域上的性能。
分析
实例选择策略
首先研究了每次迭代的四种不同的选择策略:基于Token的、基于Conf的、基于GRs的和基于GRsConf的。图4中的折线图分为两个部分,说明了基本的和LLM增强的自训练成分解析在迭代期间的解析器性能。从图中可知,对于基础的方法,除GRsConf外,所有策略的性能都呈现出先上升后下降的趋势。这种趋势表明,经过几次迭代后,候选数据的特征偏差越来越大,越来越不适合域迁移。在评论领域,使用GRsConf选择的伪数据进行自训练取得了最好的性能。
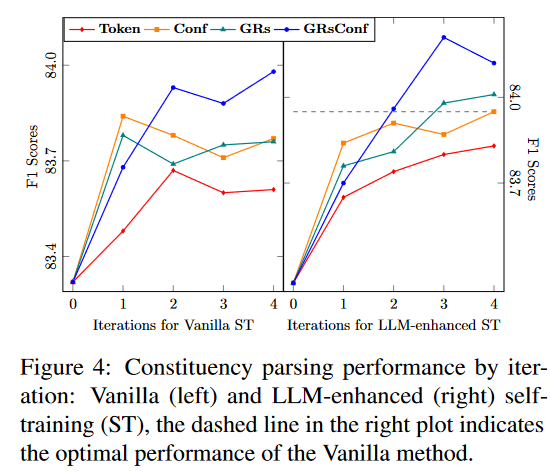
相比之下,LLM增强的自训练对所有选择策略都表现出一致的上升趋势,这表明所选择的数据是高质量的,适应过程是渐进的。这一结果突出了将LLM纳入自训练迭代过程的可行性和有效性,实现了从源域到目标域的更细粒度的迁移。
来自GRsConf的伪数据
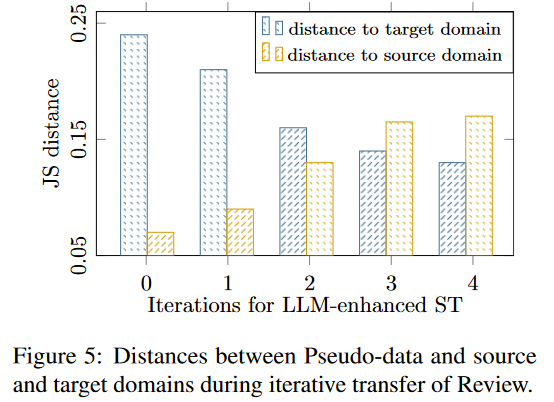
在基于LLM增强自训练的跨域句法成分解析中,性能提升的关键在于所选择的伪数据是否逐渐向目标域靠拢。LLM生成过程和选择策略从两个相反的方向指导迭代:LLM生成的原始文本逐步向目标域偏移,而选择标准旨在确保伪数据保持接近源域。因此,我们分析了评论域的最佳选择策略GRsConf,并考察了每次迭代中所选择的伪数据的分布。同时,使用GRs的JS散度来测量所选伪数据与源域和目标域之间的距离。如图5所示,所选伪数据与源域的距离逐渐增大,而与目标域的距离逐渐减小。趋势表明,域迁移在第一次迭代中是最小的,在第二次和第三次迭代中发生了更多的适应,并最终在第四次迭代中稳定下来。这种距离的演化趋势表明领域迁移过程是渐进的,印证了GRsConf选择策略结合LLM增强自训练的跨域句法解析方法的有效性。
目标句的影响
采用基于GRsConf的伪数据选择方法在评论领域进行了对比实验。如表2所示,可以得出结论,句子的数量不会显著影响最终的目标域解析器。

GRs的影响
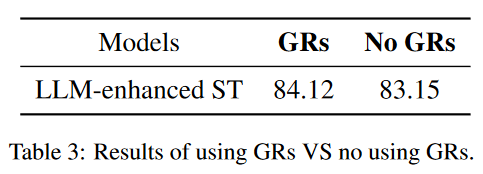
此外,我们用5个目标域句子建立了LLM生成过程,省去了语法规则的引入。从表3所示的实验结果可以看出,在没有语法规则的情况下,解析器的性能要低于标准的LLM增强的自训练方法。这表明,用语法规则约束LLM的生成是一个合理的选择。
总结
提出了一种用于句法成分解析中的跨域自适应的增强自训练方法。通过利用LLM的生成并将其整合到自训练过程中,该方法大大提高了跨域的成分解析性能。并有效地将高置信度选择标准与基于语法规则的选择相结合,逐步使训练数据更接近目标域。
编辑:黄飞
-
单片机与电磁兼容基础研究2012-08-13 1885
-
依存句法分析器的简单实现2018-10-17 2992
-
pyhanlp两种依存句法分类器2018-12-21 3487
-
基于CRF序列标注的中文依存句法分析器的Java实现2019-01-16 1987
-
自然语言处理句法分析2019-09-18 1670
-
基于本体和句法分析的领域分词的实现2009-04-09 407
-
基于浅层句法信息的翻译实例获取方法研究2009-11-24 544
-
助焊剂成分作用分析2016-05-06 774
-
如何使用中文信息MMT模型进行句法自动分析资料免费下载2018-12-19 1323
-
自然语言处理中极其重要的句法分析2019-04-09 14229
-
什么是句法分析2020-11-24 9614
-
基于句法语义依存分析的金融事件抽取2021-03-24 1187
-
LLM在数据分析中的作用2024-11-19 2002
全部0条评论

快来发表一下你的评论吧 !
