

分布式系统中常见的一致性模型
描述
什么是一致性模型?
在分布式系统中,C(一致性) 和 A(可用性)始终存在矛盾。若想保证可用性,就必须通过复制、分片等方式冗余存储。而一旦进行复制,又来带多副本数据一致性的问题——一个副本的数据更新之后,其他副本必须要保持同步,否则数据不一致就可能导致业务出现问题。
因此,每次更新数据对所有副本进行修改的时间以及方式决定了复制代价的大小。全局同步与性能实际上是矛盾的,而为了提高性能,往往会采用放宽一致性要求的方法。因此,我们需要用一致性模型来理解和推理在分布式系统中数据复制需要考虑的问题和基本假设。
那么什么是一致性模型呢?
一致性模型本质上是进程与数据存储的约定:如果进程遵循某些规则,那么进程对数据的读写操作都是可预期的。
下图即为 Jepsen 概括的常见的一致性模型:
不可用(Unavailable):粉色代表网络分区后完全不可用。当出现网络隔离等问题的时候,为了保证数据的一致性,不提供服务。熟悉 CAP 理论的同学应该清楚,这就是典型的 CP 系统了。
- 严格可用 (Sticky Available):黄色代表严格可用。即使一些节点出现问题,在一些还没出现故障的节点,仍然保证可用,但需要保证 client 的操作是一致的。
- 完全可用(Highly Available):蓝色代表完全可用。就是网络全挂掉,在没有出现问题的节点上面,仍然可用。
一致性模型主要可以分为两类:能够保证所有进程对数据的读写顺序都保持一致的一致性模型称为强一致性模型,而不能保证的一致性模型称为弱一致性模型。
强一致性模型
强一致性包含线性一致性和顺序一致性,其中前者对安全性的约束更强,也是分布式系统中能保证的最好的一致性。
线性一致性(Linearizable Consistency)
线性一致性是最严格的且可实现的单对象单操作一致性模型。在这种模型下,写入的值在调用和完成之间的某个时间点可以被其他节点读取出来。且所有节点读到数据都是原子的,即不会读到数据转换的过程和中间未完成的状态。
要想达到线性一致,需要满足以下条件:
- 任何一次读都能读取到某个数据最近的一次写的数据。
- 所有进程看到的操作顺序都跟全局时钟下的顺序一致。
- 所有进程都按照全局时钟的时间戳来区分事件的先后,那么必然所有进程看到的数据读写操作顺序一定是一样的
我们发现,这个要求十分苛刻,难以在现实中实现。因为各种物理限制使分布式数据不可能一瞬间去同步这种变化。(通信是必然有延迟的,一旦有延迟,时钟的同步就没法做到一致。)
顺序一致性(Sequential Consistency)
由于线性一致的代价高昂,因此人们想到,既然全局时钟导致严格一致性很难实现,那么我们能否放弃了全局时钟的约束,改为分布式逻辑时钟实现呢?
Lamport 在 1979 年就提出的顺序一致性正是基于上述原理。顺序一致性中所有的进程以相同的顺序看到所有的修改。读操作未必能及时得到此前其他进程对同一数据的写更新,但是每个进程读到的该数据的不同值的顺序是一致的。
其需要满足以下条件:
- 任何一次读写操作都是按照某种特定的顺序。
- 所有进程看到的读写操作顺序都保持一致。
我们发现他们都能够保证所有进程对数据的读写顺序保持一致。那么它与线性一致性有什么不同呢?
尽管顺序一致性通过逻辑时钟保证所有进程保持一致的读写操作顺序,但这些读写操作的顺序跟实际上发生的顺序并不一定一致。而线性一致性是严格保证跟实际发生的顺序一致的。
我们以下图为例:

例子1:线性一致性与顺序一致性的区别
图 a 满足了顺序一致性,但未满足线性一致性。 从全局时钟来看,p2 的 read(x,0) 在 p1 的 write(x,4) 之后,但是 p1 却读出了旧的数据。因此不满足线性一致性。但是两个进程各自的读写顺序却是合理的,进程之间也没有产生冲突,因此从这两个进程的视角来看,执行流程是这样的 write(y,2)、read(x,0)、 write(x,4)、read(y,2)。此时满足顺序一致性。
- 图 b 满足线性一致性。 因为每个读操作都读到了该变量的最新写的结果,同时两个进程看到的操作顺序与全局时钟的顺序一样。
- 图 c 不满足顺序一致性。 因为从进程 P1 的角度看,它对变量 y 的读操作返回了结果 0。那么就是说,P1 进程的对变量 y 的读操作在 P2 进程对变量 y 的写操作之前,x 变量也如此。此时两个进程存在冲突,因此这个顺序不满足顺序一致性。
弱一致性模型
弱一致性是指系统在数据成功写入之后,不承诺立即可以读到最新写入的值,也不会具体承诺多久读到,但是会尽可能保证在某个时间级别之后,可以让数据达到一致性状态。其中包含因果一致性和最终一致性、客户端一致性。
因果一致性(Causal Consistency)
什么是因果关系呢?
如果事件 B 是由事件 A 引起的或者受事件 A 的影响,那么这两个事件就具有因果关系。
因果一致性是一种弱化的顺序一致性模型,它仅要求有因果关系的操作顺序是一致的,没有因果关系的操作顺序是随机的。
因果一致性的条件包括:
- 所有进程必须以相同的顺序看到具有因果关系的读写操作。
- 不同进程可以以不同的顺序看到并发的读写操作。
我们如何确定是否具有因果关系呢?如何传播这些因果关系呢?
即通过逻辑时钟来保证两个写入是有因果关系的。而实现这个逻辑时钟的一种主要方式就是向量时钟。向量时钟算法利用了向量这种数据结构,将全局各个进程的逻辑时间戳广播给所有进程,每个进程发送事件时都会将当前进程已知的所有进程时间写入到一个向量中,而后进行传播。
最终一致性(Eventual Consistency)
最终一致性是更加弱化的一致性模型,它被表述为副本之间的数据复制完全是异步的,如果数据停止修改,那么副本之间最终会完全一致。而这个最终可能是数毫秒到数天,乃至数月,甚至是“永远”。
对于最终一致性,我们主要关注以下两点:
- **最终是多久。**通常来说,实际运行的系统需要能够保证提供一个有下限的时间范围。
- **并发冲突如何解决。**一段时间内可能数据可能多次更新,到底以哪个数据为准?通常采用最后写入成功或向量时钟等策略。
因为在数据写入与读取完全不考虑别的约束条件,因此最终一致性具有最高的并发度,经常被应用于对性能要求高的场景中。
客户端一致性(Client-centric Consistency)
在最终一致性的模型中,如果客户端在数据不同步的时间窗口内访问不同的副本的同一个数据,会出现读取同一个数据却得到不同的值的情况。为了解决这个问题,有人提出了以客户端为中心的一致性模型。
客户端一致性是站在一个客户端的角度来观察系统的一致性。其保证该客户端对数据存储的访问的一致性,但是它不为不同客户端的并发访问提供任何一致性保证。
分布式数据库中,一个节点很可能同时连接到多个副本中,复制的延迟性会造成它从不同副本读取数据是不一致的。而客户端一致性就是为了定义并解决这个问题而存在的,这其中包含了写跟随读、管道随机访问存储两大类别。
写跟随读(Writes-Follow-Reads Consistency)
写跟随读的另一个名字是回话因果(session causal)。可以看到它与因果一致的区别是,它只针对一个客户端。 即对于一个客户端,如果一次读取到了写入的值 V1,那么这次读取之后写入了 V2。从其他节点看,写入顺序一定是 V1、V2。
管道随机访问存储(PRAM,Pipeline Random Access Memory)
管道随机访问存储的名字来源于共享内存访问模型。其对于单个进程的写操作都被观察到是顺序的,但不同的进程写会观察到不同的顺序。
其可拆解为以下三种一致性:
- 单调读一致性(Monotonic-read Consistency):它强调一个值被读取出来,那么后续任何读取都会读到该值,或该值之后的值,而不会读取到旧值。
- 单调写一致性(Monotonic-write Consistency):如果从一个节点写入两个值,它们的执行顺序是 V1、V2。那么从任何节点观察它们的执行顺序都应该是 V1、V2。
- 读你所写一致性(Read-your-writes Consistency):一个节点写入数据后,在该节点或其他节点上是一定能读取到这个数据的。
能够同时满足以上三种一致性的即为满足 PRAM。
PRAM、因果一致、线性一致到底有什么区别呢?

例子2:因果一致、顺序一致、PRAM 的区别
图 a 满足了顺序一致性与因果一致性。 图上的进程都满足相同的顺序与因果关系,因此满足顺序一致性与因果一致性。
- 图 b 满足了因果一致性,但未满足顺序一致性。 对于进程 p3 和 p4 其看到的 p1 和 p2 的执行顺序不一致,因此不满足顺序一致性。但是由于 p1 与 p2 的写入没有任何因果关系,所以此时满足因果一致性。
- 图 c 满足了 PRAM,但未满足因果一致性。 由于 p2 的 r(x,4) 依赖于 p1 的 w(x,4),此时两者存在因果关系。然而对于进程 p3 和 p4 而言,其看到的 p1 和 p2 执行顺序不同,因此此时并不满足因果一致性。但此时我们再来分析它们的观察顺序,此时 p4 观察的到顺序是 w(x.7)、w(x,2)、w(x,4)。而 p3 观察到的是 w(x,2)、w(x,4)、w(x,7)。尽管此时它们对不同进程写操作观察的顺序不同,但是对于同一个进程的写操作观察顺序是一致的,因此其满足 PRAM 一致性。
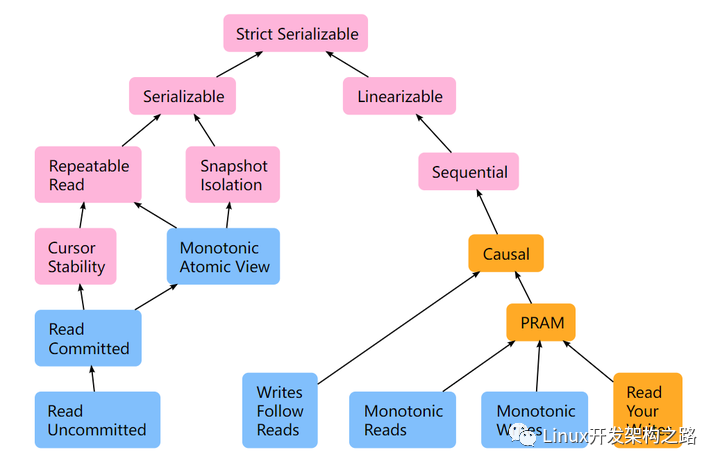
下图即为上面讨论的几种一致性模型的关系:

一致性模型之间的关系
事务隔离性
在一开始那张一致性模型图中,其实是有两个分支的,一个对应的就是数据库里面的隔离性(Isolation),另一个其实对应的是分布式系统的一致性(Consistency)。
事务隔离是描述并行事务之间的行为,而一致性是描述非并行事务之间的行为。其实广义的事务隔离应该是经典隔离理论与一致性模型的一种混合。
潜在问题
如下即数据库实现中遇到的各种各样的 isolation 问题。
- P0 Dirty Write(脏写):一个事务修改了另一个尚未提交的事务已经修改的值。
- P1 Dirty Read(脏读):一个事务读取到了另一个执行到一半的事务中修改的值。
- P2 Non-Repeatable Read(不可重复读):一个事务读取过程中读到了另一个事务更新后的结果。
- P3 Phantom(幻读):某一事务 A 先挑选出了符合一定条件的数据,之后另一个事务 B 修改了符合该条件的数据,此时 A 再进行的操作都是基于旧的数据,从而产生不一致。
- P4 Lost Update(丢失更新):更新被另一个事务覆盖。
- P4C Cursor Lost Update(游标丢失更新):与 Lost Update 类似,只是发生于 cursor 的操作过程之中。
- A5A Read Skew(读倾斜):由于事务的交叉导致读取到了不一致的数据。
- A5B Write Skew(写倾斜):两个事务同时读取到了一致的数据,然后分别进行了满足条件的修改,但最终结果破坏了一致性。
隔离级别
对于分布式数据库来说,原始的隔离级别并没有舍弃,而是引入了一致性模型后,扩宽数据库隔离级别的内涵。其中共有如下数种隔离级别:
- Read Uncommitted(读未提交):事务执行过程中能够读到未提交的修改。
- Read Committed(读已提交):事务执行过程中能够读到已提交的修改。
- Monotonic Atomic View(单调原子视图):在 Read Committed 的基础上加上了原子性的约束,观测到其他事务的修改时会观察到完整的修改。
- Cursor Stability(稳定游标):使用 cursor 读取某个数据时,这个不能被其他事务修改直至 cursor 释放或事务结束。
- Snapshot Isolation(快照隔离级别):即使其他事务修改了数据,重复读取都会读到一样的数据。
- Repeatable Read(可重复读):每个事务在独立、一致的 snapshot 上进行操作,直至提交后其他事务才可见。
- Serializable(串行化):事务按照一定的次序顺序执行。
对应的可能发生的问题如下

P(Possible):会发生。
- SP(Sometimes Possible):有时候可能发生。
- NP(Not Possible):不可能发生。
-
一致性测试系统的技术原理和也应用场景2024-11-01 4042
-
一行代码,保障分布式事务一致性—GTS:微服务架构下分布式事务解决方案2018-06-05 2693
-
顺序一致性和TSO一致性分别是什么?SC和TSO到底哪个好?2022-07-19 2742
-
蓝鲸集群文件系统中资源交互一致性协议2009-04-21 971
-
DBA迅速解决分布式事务XA一致性问题2017-09-07 1058
-
分布式一致性算法Yac2017-11-27 903
-
基于消息通信的分布式系统最终一致性平台2017-12-04 949
-
DSA系统的全局一致性需求分析2017-12-06 1155
-
分布式大数据不一致性检测2018-01-12 1082
-
一致性哈希是什么?为什么它是可扩展的分布式系统架构的一个必要工具2018-07-17 5182
-
分布式系统的CAP和数据一致性模型2020-05-05 3170
-
基于自触发一致性算法的分布式分层控制策略2021-03-24 1184
-
一种更安全的分布式一致性算法选举机制2021-04-07 1236
-
最终一致性是现在大部分高可用的分布式系统的核心思路2021-06-17 2686
-
zookeeper分布式原理2023-12-03 1432
全部0条评论

快来发表一下你的评论吧 !
