

UDP如何实现可靠传输
描述
TCP的accept发生在三次握手的哪个阶段?
如下图connect和accept的关系:
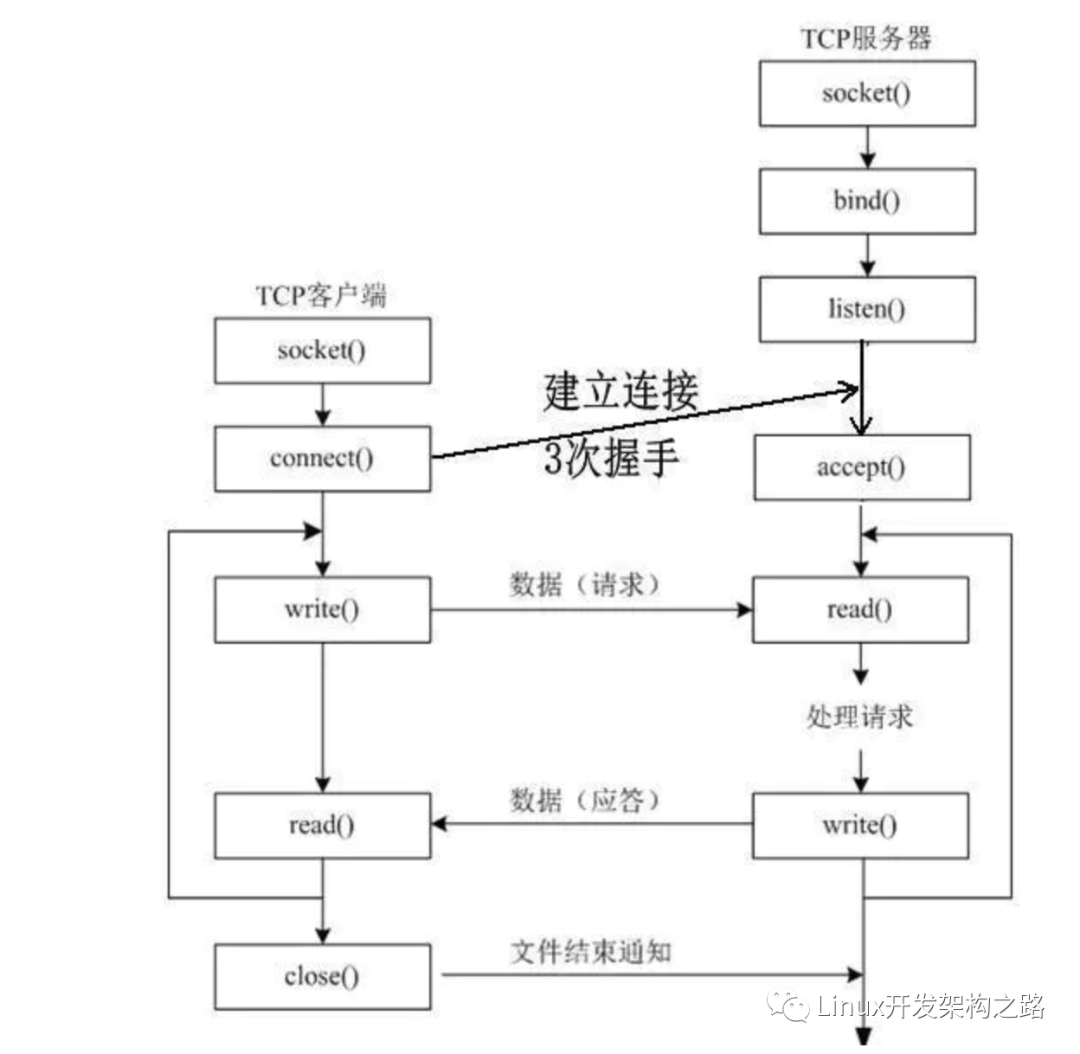
accept过程发生在三次握手之后,三次握手完成后,客户端和服务器就建立了tcp连接并可以进行数据交互了。
这时可以调用accept函数获得此连接。
connect返回了可以认为连接成功了吗?
connect返回成功后,三次握手就已经完成了。
已完成的链接会被放入一个队列中,accept的作用就是从已连接队列中取出优先级最高的一个链接,并将它绑定给一个新的fd,服务端就可以通过这个新的fd来recv和send数据了。
三次握手过程中可以携带数据么?
第三次握手的时候,可以携带。前两次握手不能携带数据。
如果前两次握手能够携带数据,那么一旦有人想攻击服务器,那么他只需要在第一次握手中的 SYN 报文中放大量数据,那么服务器势必会消耗更多的时间和内存空间去处理这些数据,增大了服务器被攻击的风险。
第三次握手的时候,客户端已经处于ESTABLISHED状态,并且已经能够确认服务器的接收、发送能力正常,这个时候相对安全了,可以携带数据。
等待2MSL的意义,如果不等待会怎样?
如果不等待,客户端直接跑路,当服务端还有很多数据包要给客户端发,且还在路上的时候,若客户端的端口此时刚好被新的应用占用,那么就接收到了无用数据包,造成数据包混乱。所以,最保险的做法是等服务器发来的数据包都死翘翘再启动新的应用。
那,照这样说一个 MSL 不就不够了吗,为什么要等待 2 MSL?
- 1 个 MSL 确保四次挥手中主动关闭方最后的 ACK 报文最终能达到对端
- 1 个 MSL 确保对端没有收到 ACK 重传的 FIN 报文可以到达
这就是等待 2MSL 的意义。
SYN Flood 攻击
SYN Flood 攻击原理
SYN Flood 属于典型的 DoS/DDoS 攻击。其攻击的原理很简单,就是用客户端在短时间内伪造大量不存在的 IP 地址,并向服务端疯狂发送SYN。对于服务端而言,会产生两个危险的后果:
- 处理大量的SYN包并返回对应ACK, 势必有大量连接处于SYN_RCVD状态,从而占满整个半连接队列,无法处理正常的请求。
- 由于是不存在的 IP,服务端长时间收不到客户端的ACK,会导致服务端不断重发数据,直到耗尽服务端的资源。
如何应对 SYN Flood 攻击?
- 增加 SYN 连接,也就是增加半连接队列的容量。
- 减少 SYN + ACK 重试次数,避免大量的超时重发。
- 利用 SYN Cookie 技术,在服务端接收到SYN后不立即分配连接资源,而是根据这个SYN计算出一个Cookie,连同第二次握手回复给客户端,在客户端回复ACK的时候带上这个Cookie值,服务端验证 Cookie 合法之后才分配连接资源。
TCP Fast Open

注意: 客户端最后握手的 ACK 不一定要等到服务端的 HTTP 响应到达才发送,两个过程没有任何关系。
第一次握手时server会计算出cookie传给客户端并缓存,之后的握手客户端会携带cookie进行SYN。
如果cookie不合法直接丢弃,如果合法,就可以直接发送http响应。
TFO 的优势
TFO 的优势并不在与首轮三次握手,而在于后面的握手,在拿到客户端的 Cookie 并验证通过以后,可以直接返回 HTTP 响应,充分利用了1 个RTT(Round-Trip Time,往返时延)的时间提前进行数据传输,积累起来还是一个比较大的优势。
序列号回绕怎么办?
现在我们来模拟一下这个问题。
序列号的范围其实是在0 ~ 2 ^ 32 - 1, 为了方便演示,我们缩小一下这个区间,假设范围是 0 ~ 4,那么到达 4 的时候会回到 0。

假设在第 6 次的时候,之前还滞留在网路中的包回来了,那么就有两个序列号为1 ~ 2的数据包了,怎么区分谁是谁呢?这个时候就产生了序列号回绕的问题。
那么用 timestamp 就能很好地解决这个问题,因为每次发包的时候都是将发包机器当时的内核时间记录在报文中,那么两次发包序列号即使相同,时间戳也不可能相同,这样就能够区分开两个数据包了。
附:
timestamp是 TCP 报文首部的一个可选项,一共占 10 个字节,格式如下:
kind(1 字节) + length(1 字节) + info(8 个字节)
其中 kind = 8, length = 10, info 有两部分构成: timestamp和timestamp echo,各占 4 个字节。
能不能说说 Nagle 算法和延迟确认?
Nagle 算法
试想一个场景,发送端不停地给接收端发很小的包,一次只发 1 个字节,那么发 1 千个字节需要发 1000 次。这种频繁的发送是存在问题的,不光是传输的时延消耗,发送和确认本身也是需要耗时的,频繁的发送接收带来了巨大的时延。
而避免小包的频繁发送,这就是 Nagle 算法要做的事情。
具体来说,Nagle 算法的规则如下:
- 当第一次发送数据时不用等待,就算是 1byte 的小包也立即发送
- 后面发送满足下面条件之一就可以发了:
- 数据包大小达到最大段大小(Max Segment Size, 即 MSS)
- 之前所有包的 ACK 都已接收到
延迟确认
试想这样一个场景,当我收到了发送端的一个包,然后在极短的时间内又接收到了第二个包,那我是一个个地回复,还是稍微等一下,把两个包的 ACK 合并后一起回复呢?
延迟确认(delayed ack)所做的事情,就是后者,稍稍延迟,然后合并 ACK,最后才回复给发送端。TCP 要求这个延迟的时延必须小于500ms,一般操作系统实现都不会超过200ms。
不过需要主要的是,有一些场景是不能延迟确认的,收到了就要马上回复:
- 接收到了大于一个 frame 的报文,且需要调整窗口大小
- TCP 处于 quickack 模式(通过tcp_in_quickack_mode设置)
- 发现了乱序包
两者一起使用会怎样?
前者意味着延迟发,后者意味着延迟接收,会造成更大的延迟,产生性能问题。
TCP的Keep Alive和HTTP的Keep Alive的区别
TCP keepalive
- 在双方长时间未通讯时,如何得知对方还活着?如何得知这个TCP连接是健康且具有通讯能力的?
- TCP的保活机制就是用来解决此类问题的
- 保活机制默认是关闭的,TCP连接的任何一方都可打开此功能。
- 若对端正常存活,且连接有效,对端必然能收到探测报文并进行响应。此时,发送端收到响应报文则证明TCP连接正常,重置保活时间计数器即可。
- 若由于网络原因或其他原因导致,发送端无法正常收到保活探测报文的响应。那么在一定探测时间间隔(tcp_keepalive_intvl)后,将继续发送保活探测报文。直到收到对端的响应,或者达到配置的探测循环次数上限(tcp_keepalive_probes)都没有收到对端响应,这时对端会被认为不可达,TCP连接随存在但已失效,需要将连接做中断处理。
HTTP keep-alive
- keep-alive机制:若开启后,在一次http请求中,服务器进行响应后,不再直接断开TCP连接,而是将TCP连接维持一段时间。在这段时间内,如果同一客户端再次向服务端发起http请求,便可以复用此TCP连接,向服务端发起请求,并重置timeout时间计数器,在接下来一段时间内还可以继续复用。这样无疑省略了反复创建和销毁TCP连接的损耗。
TCP队头阻塞和HTTP队头阻塞
- TCP队头阻塞
TCP数据包是有序传输,中间一个数据包丢失,会等待该数据包重传,造成后面的数据包的阻塞。(停止等待)
- HTTP队头阻塞
http队头阻塞和TCP队头阻塞完全不是一回事。
http1.x采用长连接(Connection:keep-alive),可以在一个TCP请求上,发送多个http请求。
有非管道化和管道化,两种方式。
非管道化,完全串行执行,请求->响应->请求->响应…,后一个请求必须在前一个响应之后发送。
管道化,请求可以并行发出,但是响应必须串行返回。后一个响应必须在前一个响应之后。原因是,没有序号标明顺序,只能串行接收。
管道化请求的致命弱点:
- 会造成队头阻塞,前一个响应未及时返回,后面的响应被阻塞
- 请求必须是幂等请求,不能修改资源。因为,意外中断时候,客户端需要把未收到响应的请求重发,非幂等请求,会造成资源破坏。
由于这个原因,目前大部分浏览器和Web服务器,都关闭了管道化,采用非管道化模式。
无论是非管道化还是管道化,都会造成队头阻塞(请求阻塞)。
解决http队头阻塞的方法:
- 并发TCP连接(浏览器一个域名采用6-8个TCP连接,并发HTTP请求)
- 域名分片(多个域名,可以建立更多的TCP连接,从而提高HTTP请求的并发)
- HTTP2方式
http2使用一个域名单一TCP连接发送请求,请求包被二进制分帧**(多路复用)**不同请求可以互相穿插,避免了http层面的请求队头阻塞。但是不能避免TCP层面的队头阻塞。
UDP
UDP如何实现可靠传输?
传输层无法保证数据的可靠传输,只能通过应用层来实现了。
实现的方式可以参照tcp可靠性传输的方式,只是实现不在传输层,实现转移到了应用层。
最简单的方式是在应用层模仿传输层TCP的可靠性传输。
下面不考虑拥塞处理,可靠UDP的简单设计。
1、添加seq/ack机制,确保数据发送到对端
2、添加发送和接收缓冲区,主要是用户超时重传。
3、添加超时重传机制。
详细说明:送端发送数据时,生成一个随机seq=x,然后每一片按照数据大小分配seq。数据到达接收端后接收端放入缓存,并发送一个ack=x的包,表示对方已经收到了数据。发送端收到了ack包后,删除缓冲区对应的数据。时间到后,定时任务检查是否需要重传数据。
-
udp是什么协议?udp协议介绍2024-04-19 3915
-
UDP与TCP的主要区别 UDP能否像TCP一样实现可靠传输?2024-01-22 1942
-
如何选择传输层协议?TCP和UDP的优缺点和适用场合2023-12-11 2654
-
TCP和UDP如何实现可靠性传输2023-10-16 2334
-
udp是什么协议 TCP与UDP的区别2023-06-26 12897
-
UDP能否像TCP一样实现可靠传输?2023-06-05 1446
-
基于UDP的简单文件传输协议TFTP设计2022-12-14 3951
-
udp协议设计与实现2022-08-04 845
-
如何使用UDP协议设计及实现语音传输系统的方法详细说明2019-11-20 1388
-
实现基于51单片机的UDP实时传输工具2017-09-21 753
-
TCP和UDP的区别分析2017-09-18 828
-
UDP高速传输问题2016-05-24 7122
-
求助关于TCP/UDP传输的问题2016-05-20 3792
-
基于UDP协议的语音传输系统设计及实现2010-07-02 1159
全部0条评论

快来发表一下你的评论吧 !
