

如何使用原子类型
描述
一、何为原子操作
原子操作:顾名思义就是不可分割的操作,该操作只存在未开始和已完成两种状态,不存在中间状态;
原子类型:原子库中定义的数据类型,对这些类型的所有操作都是原子的,包括通过原子类模板std::atomic< T >实例化的数据类型,也都是支持原子操作的。
二、如何使用原子类型
2.1 原子库atomic支持的原子操作
原子库< atomic >中提供了一些基本原子类型,也可以通过原子类模板实例化一个原子对象,下面列出一些基本原子类型及相应的特化模板如下:
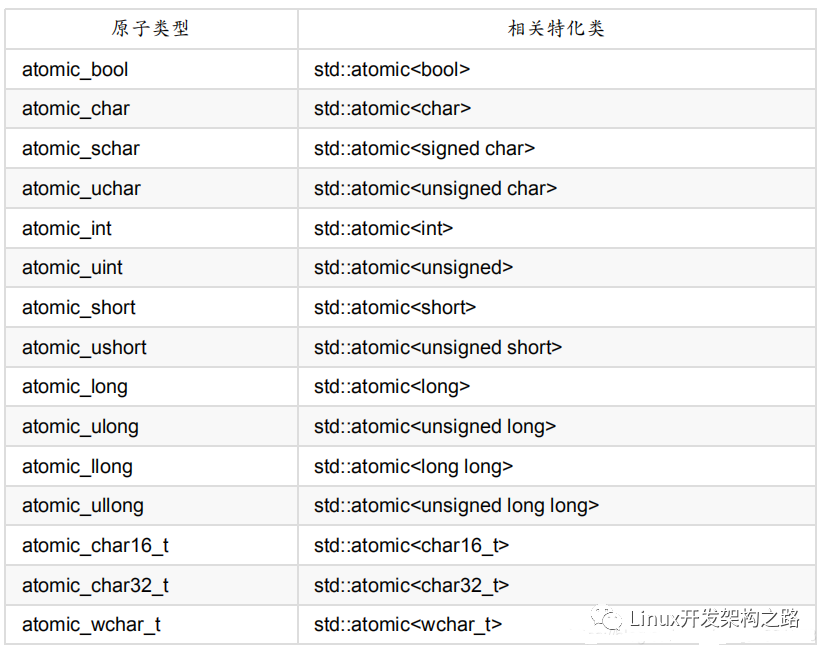
对原子类型的访问,最主要的就是读和写,但原子库提供的对应原子操作是load()与store(val)。原子类型支持的原子操作如下:

2.2 原子操作中的内存访问模型
原子操作保证了对数据的访问只有未开始和已完成两种状态,不会访问到中间状态,但我们访问数据一般是需要特定顺序的,比如想读取写入后的最新数据,原子操作函数是支持控制读写顺序的,即带有一个数据同步内存模型参数std::memory_order,用于对同一时间的读写操作进行排序。C++11定义的6种类型如下:
- memory_order_relaxed: 宽松操作,没有同步或顺序制约,仅对此操作要求原子性;
- memory_order_release & memory_order_acquire: 两个线程A&B,A线程Release后,B线程Acquire能保证一定读到的是最新被修改过的值;这种模型更强大的地方在于它能保证发生在A-Release前的所有写操作,在B-Acquire后都能读到最新值;
- memory_order_release & memory_order_consume: 上一个模型的同步是针对所有对象的,这种模型只针对依赖于该操作涉及的对象:比如这个操作发生在变量a上,而s = a + b; 那s依赖于a,但b不依赖于a; 当然这里也有循环依赖的问题,例如:t = s + 1,因为s依赖于a,那t其实也是依赖于a的;
- memory_order_seq_cst: 顺序一致性模型,这是C++11原子操作的默认模型;大概行为为对每一个变量都进行Release-Acquire操作,当然这也是一个最慢的同步模型;
内存访问模型属于比较底层的控制接口,如果对编译原理和CPU指令执行过程不了解的话,容易引入bug。内存模型不是本章重点,这里不再展开介绍,后续的代码都使用默认的顺序一致性模型或比较稳妥的Release-Acquire模型。
2.3 使用原子类型替代互斥锁编程
为便于比较,直接基于前篇文章:线程同步之互斥锁中的示例程序进行修改,用原子库取代互斥库的代码如下:
//atomic1.cpp 使用原子库取代互斥库实现线程同步
#include < chrono >
#include < atomic >
#include < thread >
#include < iostream >
std::chrono::milliseconds interval(100);
std::atomic< bool > readyFlag(false); //原子布尔类型,取代互斥量
std::atomic< int > job_shared(0); //两个线程都能修改'job_shared',将该变量特化为原子类型
int job_exclusive = 0; //只有一个线程能修改'job_exclusive',不需要保护
//此线程只能修改 'job_shared'
void job_1()
{
std::this_thread::sleep_for(5 * interval);
job_shared.fetch_add(1);
std::cout < < "job_1 shared (" < < job_shared.load() < < ")n";
readyFlag.store(true); //改变布尔标记状态为真
}
// 此线程能修改'job_shared'和'job_exclusive'
void job_2()
{
while (true) { //无限循环,直到可访问并修改'job_shared'
if (readyFlag.load()) { //判断布尔标记状态是否为真,为真则修改‘job_shared’
job_shared.fetch_add(1);
std::cout < < "job_2 shared (" < < job_shared.load() < < ")n";
return;
} else { //布尔标记为假,则修改'job_exclusive'
++job_exclusive;
std::cout < < "job_2 exclusive (" < < job_exclusive < < ")n";
std::this_thread::sleep_for(interval);
}
}
}
int main()
{
std::thread thread_1(job_1);
std::thread thread_2(job_2);
thread_1.join();
thread_2.join();
getchar();
return 0;
}
由示例程序可以看出,原子布尔类型可以实现互斥锁的部分功能,但在使用条件变量condition variable时,仍然需要mutex保护对condition variable的消费,即使condition variable是一个atomic object。
2.4 使用原子类型实现自旋锁
自旋锁(spinlock)与互斥锁(mutex)类似,在任一时刻最多只能有一个持有者,但如果资源已被占用,互斥锁会让资源申请者进入睡眠状态,而自旋锁不会引起调用者睡眠,会一直循环判断该锁是否成功获取。自旋锁是专为防止多处理器并发而引入的一种锁,它在内核中大量应用于中断处理等部分(对于单处理器来说,防止中断处理中的并发可简单采用关闭中断的方式,即在标志寄存器中关闭/打开中断标志位,不需要自旋锁)。
对于多核处理器来说,检测到锁可用与设置锁状态两个动作需要实现为一个原子操作,如果分为两个原子操作,则可能一个线程在获得锁后设置锁前被其余线程抢到该锁,导致执行错误。这就需要原子库提供对原子变量“读-修改-写(Read-Modify-Write)”的原子操作,上文原子类型支持的操作中就提供了RMW(Read-Modify-Write)原子操作,比如a.exchange(val)与a.compare_exchange(expected,desired)。
标准库还专门提供了一个原子布尔类型std::atomic_flag,不同于所有 std::atomic 的特化,它保证是免锁的,不提供load()与store(val)操作,但提供了test_and_set()与clear()操作,其中test_and_set()就是支持RMW的原子操作,可用std::atomic_flag实现自旋锁的功能,代码如下:
//atomic2.cpp 使用原子布尔类型实现自旋锁的功能
#include < thread >
#include < vector >
#include < iostream >
#include < atomic >
std::atomic_flag lock = ATOMIC_FLAG_INIT; //初始化原子布尔类型
void f(int n)
{
for (int cnt = 0; cnt < 100; ++cnt) {
while (lock.test_and_set(std::memory_order_acquire)) // 获得锁
; // 自旋
std::cout < < n < < " thread Output: " < < cnt < < 'n';
lock.clear(std::memory_order_release); // 释放锁
}
}
int main()
{
std::vector< std::thread > v; //实例化一个元素类型为std::thread的向量
for (int n = 0; n < 10; ++n) {
v.emplace_back(f, n); //以参数(f,n)为初值的元素放到向量末尾,相当于启动新线程f(n)
}
for (auto& t : v) { //遍历向量v中的元素,基于范围的for循环,auto&自动推导变量类型并引用指针指向的内容
t.join(); //阻塞主线程直至子线程执行完毕
}
getchar();
return 0;
}
自旋锁除了使用atomic_flag的TAS(Test And Set)原子操作实现外,还可以使用普通的原子类型std::atomic实现:其中a.exchange(val)是支持TAS原子操作的,a.compare_exchange(expected,desired)是支持CAS(Compare And Swap)原子操作的,感兴趣可以自己实现出来。其中CAS原子操作是无锁编程的主要实现手段,我们接着往下介绍无锁编程。
三、如何进行无锁编程
3.1 什么是无锁编程
在原子操作出现之前,对共享数据的读写可能得到不确定的结果,所以多线程并发编程时要对使用锁机制对共享数据的访问过程进行保护。但锁的申请释放增加了访问共享资源的消耗,且可能引起线程阻塞、锁竞争、死锁、优先级反转、难以调试等问题。
现在有了原子操作的支持,对单个基础数据类型的读、写访问可以不用锁保护了,但对于复杂数据类型比如链表,有可能出现多个核心在链表同一位置同时增删节点的情况,这将会导致操作失败或错序。所以我们在对某节点操作前,需要先判断该节点的值是否跟预期的一致,如果一致则进行操作,不一致则更新期望值,这几步操作依然需要实现为一个RMW(Read-Modify-Write)原子操作,这就是前面提到的CAS(Compare And Swap)原子操作,它是无锁编程中最常用的操作。
既然无锁编程是为了解决锁机制带来的一些问题而出现的,那么无锁编程就可以理解为不使用锁机制就可保证多线程间原子变量同步的编程。无锁(lock-free)的实现只是将多条指令合并成了一条指令形成一个逻辑完备的最小单元,通过兼容CPU指令执行逻辑形成的一种多线程编程模型。
无锁编程是基于原子操作的,对基本原子类型的共享访问由load()与store(val)即可保证其并发同步,对抽象复杂类型的共享访问则需要更复杂的CAS来保证其并发同步,并发访问过程只是不使用锁机制了,但还是可以理解为有锁止行为的,其粒度很小,性能更高。对于某个无法实现为一个原子操作的并发访问过程还是需要借助锁机制来实现。
3.1 CAS原子操作实现无锁编程
CAS原子操作主要是通过函数a.compare_exchange(expected,desired)实现的,其语义为“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”,CAS算法的实现伪码如下:
bool compare_exchange_strong(T& expected, T desired)
{
if( this- >load() == expected ) {
this- >store(desired);
return true;
} else {
expected = this- >load();
return false;
}
}
下面尝试实现一个无锁栈,代码如下:
//atomic3.cpp 使用CAS操作实现一个无锁栈
#include < atomic >
#include < iostream >
template< typename T >
class lock_free_stack
{
private:
struct node
{
T data;
node* next;
node(const T& data) : data(data), next(nullptr) {}
};
std::atomic< node* > head;
public:
lock_free_stack(): head(nullptr) {}
void push(const T& data)
{
node* new_node = new node(data);
do{
new_node- >next = head.load(); //将 head 的当前值放入new_node- >next
}while(!head.compare_exchange_strong(new_node- >next, new_node));
// 如果新元素new_node的next和栈顶head一样,证明在你之前没人操作它,使用新元素替换栈顶退出即可;
// 如果不一样,证明在你之前已经有人操作它,栈顶已发生改变,该函数会自动更新新元素的next值为改变后的栈顶;
// 然后继续循环检测直到状态1成立退出;
}
T pop()
{
node* node;
do{
node = head.load();
}while (node && !head.compare_exchange_strong(node, node- >next));
if(node)
return node- >data;
}
};
int main()
{
lock_free_stack< int > s;
s.push(1);
s.push(2);
s.push(3);
std::cout < < s.pop() < < std::endl;
std::cout < < s.pop() < < std::endl;
getchar();
return 0;
}
程序注释中已经解释的很清楚了,在将数据压栈前,先通过比较原子类型head与新元素的next指向对象是否相等来判断head是否已被其他线程修改,根据判断结果选择是继续操作还是更新期望,而这一切都是在一个原子操作中完成的,保证了在不使用锁的情况下实现共享数据的并发同步。
CAS 看起来很厉害,但也有缺点,最著名的就是 ABA 问题,假设一个变量 A ,修改为 B之后又修改为 A,CAS 的机制是无法察觉的,但实际上已经被修改过了。如果在基本类型上是没有问题的,但是如果是引用类型呢?这个对象中有多个变量,我怎么知道有没有被改过?聪明的你一定想到了,加个版本号啊。每次修改就检查版本号,如果版本号变了,说明改过,就算你还是 A,也不行。
上面的例子节点指针也属于引用类型,自然也存在ABA问题,比如在线程2执行pop操作,将A,B都删掉,然后创建一个新元素push进去,因为操作系统的内存分配机制会重复使用之前释放的内存,恰好push进去的内存地址和A一样,我们记为A’,这时候切换到线程1,CAS操作检查到A没变化成功将B设为栈顶,但B是一个已经被释放的内存块。该问题的解决方案就是上面说的通过打标签标识A和A’为不同的指针,具体实现代码读者可以尝试实现。
-
三种最常见的接线端子类型:PCB安装,隔离带和馈通2021-04-20 20019
-
请问三级管开关如果控制负电压对管子类型有要求吗2018-08-19 3931
-
芯灵思SinlinxA33开发板Linux内核原子操作(附实测代码)2019-02-19 12785
-
请教大神我可以在OTA分区运行时更改分区子类型吗?2023-03-02 871
-
如何在运行时更改分区子类型?2023-04-13 513
-
什么是子类?2009-04-28 4488
-
等离子类型2009-12-31 807
-
pcb接线端子类型有哪些2021-08-22 11921
-
Rust原子类型和内存排序2022-10-31 1909
-
接线端子类型介绍2022-11-24 5548
-
常见的接线端子类型有哪些?2023-02-14 4786
-
有刷直流电动机的转子类型有哪些2024-06-12 2450
-
DIY项目中常用的端子类型2024-12-29 3676
全部0条评论

快来发表一下你的评论吧 !
