

HTTP 中GET 和 POST 的区别
描述
一、概述
HTTP 的请求报文
GET 方法的特点
POST 方法的特点
GET 和 POST 的区别
二、HTTP 的请求报文
首先我们要解决的第一个问题是:GET 和 POST 是什么?
GET 和 POST 其实都是 HTTP 的请求方法。除了这 2 个请求方法之外,HTTP 还有 HEAD、PUT、DELETE、TRACE、CONNECT、OPTIONS 这 6 个请求方法。所以HTTP 的请求方法共计有 8 种,它们的描述如下所示:
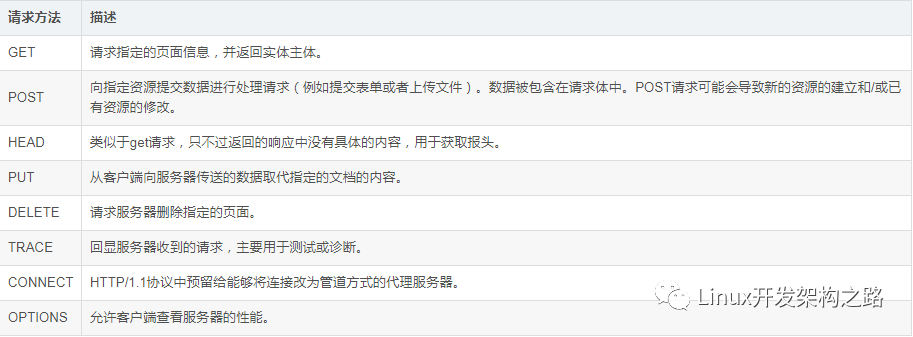
接下来我们解决第二个问题:请求方法如何使用?
要解决这个问题,我们首先需要了解 HTTP 的请求报文结构:

可以看到 HTTP 的请求报文由三部分构成:
- 请求行:由请求方法(Method)、URL 字段和 HTTP 的协议版本组成,注意其中的空格、回车符和换行符均不可省略,所以我们的请求方法实际上就是位于请求行中的了。
- 请求头部:位于请求行之后,个数可以为 0~若干个,每个请求头部都包含一个头部字段名和一个值,它们之间用冒号 ":" 分隔,在最后用回车符和换行符表示结束。
- 请求数据:如果请求方法为 GET,那么请求数据为空。它主要是在 POST 中进行使用,适用于需要填表单(FORM)的场景。
我们通过一个实际的例子来看看 HTTP 的 GET 请求报文是什么样的,我们这里以访问
https://api.github.com/search/users?q=JakeWharton 为例,通过抓包我们得到的请求报文如下所示:
GET /search/users?q=JakeWharton HTTP/1.1
Host: api.github.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _octo=GH1.1.1623908978.1549006668; _ga=GA1.2.548087391.1549006688; logged_in=yes; dotcom_user=GoMarck; _gid=GA1.2.17634150.1554639136; _gat=1
我们重点看到请求行:
GET /search/users?q=JakeWharton HTTP/1.1
可以看到请求方法用的是 GET 请求,URL为 /search/users?q=JakeWharton,协议为 HTTP1.1。
请求行下面部分全都是请求头部,我们可以看到 host 为 api.github.com,连接方式为长连接等信息。值得注意的是我们这个例子中是不存在请求数据的。
接下来我们在来看一下 POST 请求的报文(该例子源自其他博客):
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
可以看到请求行中请求方法为 POST,URL 为空,协议版本也是 HTTP1.1。它和上面 GET 方法例子不一样的地方在于它的请求参数是位于请求数据中的,可以看到 name=Professional%20Ajax&publisher=Wiley 就是它的请求数据。并且我们要注意到在请求数据和请求头之间是空出一行的,这是必不可少的。
三、GET 方法的特点
1、前面的例子:
https://api.github.com/search/users?q=JakeWharton 就是一个非常典型的 GET 请求的表现形式,即请求的数据会附在 URL 之后(放在请求行中),以 ? 分割 URL 和传输数据,多个参数用 & 连接。
2、除此之外,根据 HTTP 规范,GET 用于信息获取,而且应该是安全和幂等的 。
安全性指的是非修改信息,即该操作用于获取信息而非修改信息。换句话说,GET请求一般不应产生副作用,也就是说,它仅仅是获取资源信息,就像数据库查询一样,不会修改,增加数据,不会影响资源的状态。
幂等性 (Idempotence) 则指的是无论调用这个URL 多少次,都不会有不同的结果的 HTTP 方法。而在实际过程中,这个规定没有那么严格。例如在一个新闻应用中,新闻站点的头版不断更新,虽然第二次请求会返回不同的一批新闻,该操作仍然被认为是安全的和幂等的,因为它总是返回当前的新闻。
3、GET 是会被浏览器主动缓存的,如果下一次传输的数据相同,那么就会返回缓存中的内容,以求更快地展示数据。
4、GET 方法的 URL 一般都具有长度限制,但是需要注意的是 HTTP 协议中并未规定 GET 请求的长度。这个长度限制主要是由浏览器和 Web 服务器所决定的,并且各个浏览器对长度的限制也各不相同。
5、GET 方法只产生一个 TCP 数据包,浏览器会把请求头和请求数据一并发送出去,服务器响应 200 ok(返回数据)。
四、POST 方法的特点
- 根据 HTTP 规范,POST 表示可能修改变服务器上的资源的请求。例如我们在刷知乎的时候对某篇文章进行点赞,就是提交的 POST 请求,因为它改变了服务器中的数据(该篇文章的点赞数)。
- POST 方法因为有可能修改服务器上的资源,所以它是不符合安全和幂等性的。
- 从前面关于 POST 的请求报文也可以看出,POST 是将请求信息放置在请求数据中的,这也是 POST 和 GET 的一点不那么重要的区别。有一些博客的说法是 GET 请求的请求信息是放置在 URL 的而 POST 是放置在请求数据中的所以 POST 比 GET 更安全。其实这种说法很有问题,随便抓下包 POST 中的请求报文就暴露无疑了,这又何来安全之说?
- 因为 POST 方法的请求信息是放置在请求数据中的,所以它的请求信息是没有长度限制的。
- POST 方法会产生两个 TCP 数据包,浏览器会先将请求头发送给服务器,待服务器响应100 continue,浏览器再发送请求数据,服务器响应200 ok(返回数据)。这么看起来 GET 请求的传输会比 POST 快上一些(因为GET 方法只发送一个 TCP 数据包),但是实际上在网络良好的情况下它们的传输速度基本相同。
五、GET 和 POST 的区别
上面说了那么多 GET 方法和 POST 方法各自的特点,它们在外在的表现上似乎是有着诸多的不同,但是实际上,它们的本质是一样的,并无区别!!!
这似乎有些不可思议,但是我们重新回想一下 GET 和 POST 是什么?它们是 HTTP 请求协议的请求方法,而 HTTP 又是基于TCP/IP的关于数据如何在万维网中如何通信的协议,所以 GET/POST 实际上都是 TCP 链接。
也就是说,GET 和 POST 所做的事其实是一样的,如果你给 GET 加上请求数据,给 POST 加上 URL 参数,这在技术上是完全可行的,事实上确实有一些人为了贪图方便在更新资源时用了GET,因为用POST必须要到FORM(表单),这样会麻烦一点(但是强烈不建议这样子做!!!)。
既然 GET 和 POST 的底层都是 TCP,那么为什么 HTTP 还要特别将它们区分出来呢?
其实可以想象一下,如果我们直接使用 TCP 进行数据的传输,那么无论是单纯获取资源的请求还是修改服务器资源的请求在外观上看起来都是 TCP 链接,这样就非常不利于进行管理。所以在 HTTP 协议中,就会对这些不同的请求设置不同的类别进行管理,例如单纯获取资源的请求就规定为 GET、修改服务器资源的请求就规定为 POST,并且也对它们的请求报文的格式做出了相应的要求(例如请求参数 GET 位于 URL 而 POST 则位于请求数据中)。
当然,如果我们想将 GET 的请求参数放置在请求数据中或者将 POST 的请求数据放置在 URL 中,这是完全可以的,虽然这样子做并不符合 HTTP 的规范。但是这样子做是否能得到我们期望的响应数据呢?答案是未必,这取决于服务器的行为。
以 GET 方法在请求数据中放置请求参数为例,有些服务器会将请求数据中的参数读出,在这种情况下我们依然能获得我们期望的响应数据;而有些服务器则会选择直接忽略,这种情况下我们就无法获取期望的响应数据了。
所以,对于 GET 和 POST 的区别,总结来说就是:它们的本质都是 TCP 链接,并无区别。但是由于 HTTP 的规定以及浏览器/服务器的限制,导致它们在应用过程中可能会有所不同。
-
HTTP post的结束符能否改变2012-05-25 4327
-
GET和POST的请求示例流程2021-04-02 3805
-
什么是Http协议?2021-12-22 1133
-
如何通过GET和POST请求控制pwm占空比?2023-02-28 528
-
IDF-4.4.2使用file_server例程作为http server服务器,使用POST上传文件报405错误怎么解决?2023-03-06 743
-
http请求 get post2017-09-27 1155
-
PHP中REQUEST和POST及GET有什么区别2019-02-19 1542
-
get与post的请求一些区别2022-09-07 2514
-
Java中Get和Post的使用2023-01-12 1732
-
HTTP请求报文:GET和POST的区别2023-04-10 3466
-
HTTP协议的运作方式2023-05-06 1291
-
HTTP中GET与POST的区别是什么?2023-08-05 1128
-
所有接口都用post请求的原因2023-08-24 928
-
安信可Ai-WB2模组HTTP 客户端 POST请求方法2023-10-30 1711
-
鸿蒙OS开发实战:【网络管理HTTP数据请求】2024-04-01 2256
全部0条评论

快来发表一下你的评论吧 !
