

进程和线程的区别
描述
1.什么是进程?为什么要有进程?
进程有一个相当精简的解释:进程是对操作系统上正在运行程序的一个抽象。
这个概念确实挺抽象,仔细想想却也挺精准。
我们平常使用计算机,都会在同一时间做许多事,比如边看电影,边微信聊天,顺便打开浏览器百度搜索一下,我们所做的这么多事情背后都是一个个正在运行中的软件程序;这些软件想要运行起来,首先在磁盘上需要有各自的程序代码,然后将代码加载到内存中,CPU会去执行这些代码,运行中会产生很多数据需要存放,也可能需要和网卡、显卡、键盘等外部设备交互,这背后其实就涉及到程序对计算机资源的使用,存在这么多程序,我们当然需要想办法管理程序资源的使用。并且CPU如果只有一个,那么还需要操作系统调度CPU分配给各个程序使用,让用户感觉这些程序在同时运行,不影响用户体验。
理所当然,操作系统会把每个运行中的程序封装成独立的实体,分配各自所需要的资源,再根据调度算法切换执行。这个抽象程序实体就是进程。
所以很多对进程的官方解释中都会提到:进程是操作系统进行资源分配和调度的一个基本单位。
2.什么是线程?为什么要有线程?
在早期的操作系统中并没有线程的概念,进程是拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的内存空间,使得各个进程之间内存地址相互隔离。
后来,随着计算机行业的发展,程序的功能设计越来越复杂,我们的应用中同时发生着多种活动,其中某些活动随着时间的推移会被阻塞,比如网络请求、读写文件(也就是IO操作),我们自然而然地想着能不能把这些应用程序分解成更细粒度、能 准并行运行 多个顺序执行实体,并且这些细粒度的执行实体可以共享进程的地址空间,也就是可以共享程序代码、数据、内存空间等,这样程序设计模型会变得更加简单。
其实很多计算机世界里的技术演变,都是模拟现实世界。比如我们把一个进程当成一个项目,当项目任务变得复杂时,自然想着能不能将项目按照业务、产品、工作方向等分成一个个任务模块,分派给不同人员各自并行完成,再按照某种方式组织起各自的任务成果,最终完成项目。
需要多线程还有一个重要的理由就是:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。所以线程的创建、销毁、调度性能远远优于进程。
在引入多线程模型后,进程和线程在程序执行过程中的分工就相当明确了,进程负责分配和管理系统资源,线程负责CPU调度运算,也是CPU切换时间片的最小单位。对于任何一个进程来讲,即便我们没有主动去创建线程,进程也是默认有一个主线程的。
3.它们在Linux内核中实现方式有何不同?
在Linux 里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务(Task),由一个统一的结构 task_struct 进行管理,这个task_struct 数据结构非常复杂,囊括了进程管理生命周期中的各种信息。
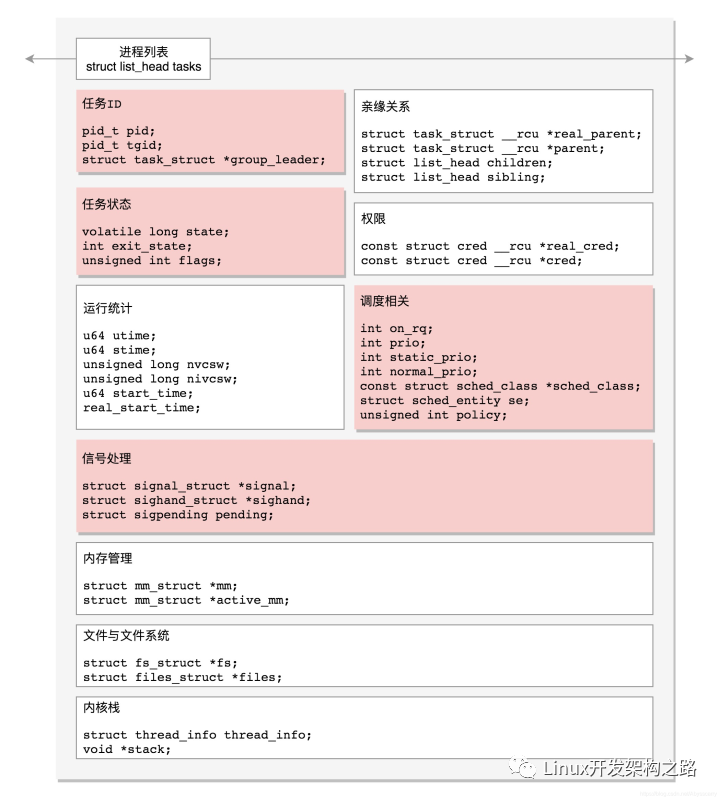
在Linux操作系统内核初始化时会创建第一个进程,即0号创始进程。随后会初始化1号进程(用户进程祖宗:/usr/lib/systemd/systemd),2号进程(内核进程祖宗:[kthreadd]),其后所有的进程线程都是在他们的基础上fork出来的。


我们一般都是通过fork系统调用来创建新的进程,fork 系统调用包含两个重要的事件,一个是将 task_struct 结构复制一份并且初始化,另一个是试图唤醒新创建的子进程。
我们说无论是进程还是线程,在内核里面都是task,管起来不是都一样吗?到底如何区分呢?其实,线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的。
创建进程的话,调用的系统调用是 fork,会将五大结构 files_struct、fs_struct、sighand_struct、signal_struct、mm_struct 都复制一遍,从此父进程和子进程各用各的数据结构。而创建线程的话,调用的是系统调用 clone,五大结构仅仅是引用计数加一,也即线程共享进程的数据结构。
4.所以它们到底有哪些区别?
功能:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
开销:每个进程都有独立的内存空间,存放代码和数据段等,程序之间的切换会有较大的开销;线程可以看做轻量级的进程,共享内存空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
运行环境:在操作系统中能同时运行多个进程;而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
创建过程:在创建新进程的时候,会将父进程的所有五大数据结构复制新的,形成自己新的内存空间数据,而在创建新线程的时候,则是引用进程的五大数据结构数据,但是线程会有自己的私有数据、栈空间。
进程和线程其实在cpu看来都是task_struct结构的一个封装,执行不同task即可,而且在cpu看来就是在执行这些task时候遵循对应的调度策略以及上下文资源切换定义,包括寄存器地址切换,内核栈切换。所以对于cpu而言,进程和线程是没有区别的。
附:我们通常所说的上下文切换具体指什么?
操作系统抽象出一个进程的概念,让应用程序专心于实现自己的业务逻辑既可,对应用程序屏蔽了CPU调度、内存管理等硬件细节,而且在有限的CPU上可以“同时”进行许多个任务。但是它为用户带来方便的同时,也引入了一些额外的开销。
在操作系统中,由于CPU的时间片调度策略,从一个进程切换到另一个进程需要保存当前进程的状态并恢复另一个进程的状态:当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务。上下文切换包括保存当前任务的运行环境,恢复将要运行任务的运行环境。
在上下文切换过程中,CPU会停止处理当前运行的程序,并保存当前程序运行的具体位置以便之后继续运行。从这个角度来看,上下文切换有点像我们同时阅读几本书,在来回切换书本的同时我们需要记住每本书当前读到的页码。
在三种情况下可能会发生上下文切换:中断处理,多任务处理,内核/用户态切换。
在中断处理中,其他程序”打断”了当前正在运行的程序。当CPU接收到中断请求时,会在正在运行的程序和发起中断请求的程序之间进行一次上下文切换。
在多任务处理中,CPU会在不同程序之间来回切换,每个程序都有相应的处理时间片,CPU在两个时间片的间隔中进行上下文切换。
在Linux中进行内核/用户态切换也会进行上下文切换,进行系统调用时,CPU寄存器里原来用户态的指令位置需要先保存起来。接着,为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程,所以一次系统调用的过程,其实是发生了两次CPU上下文切换。
CPU上下文切换,是保证Linux系统正常工作的核心功能之一,一般情况下不需要我们特别关注。
但过多的上下文切换,会把CPU时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。
-
进程和线程的概念及其区别2023-11-21 2610
-
嵌入式进程和线程的区别2023-09-04 1085
-
进程和线程的区别以及优缺点2023-07-21 2429
-
程序中进程和线程的区别2023-06-22 1796
-
进程切换与线程切换有啥区别2023-02-24 1233
-
Java语言核心基础语法325-进程与线程的区别电子学习 2023-01-16
-
进程与线程的区别和联系2022-12-05 1621
-
#硬声创作季 程序员知识:【进程管理】进程和线程的区别Mr_haohao 2022-09-16
-
进程和线程的区别是什么2021-12-23 975
-
进程和线程得区别在哪?2021-07-07 1616
-
Linux进程和线程的区别是什么?2021-03-11 1675
-
进程和线程的区别和联系介绍2018-07-04 3150
-
进程和线程区别2016-11-30 4648
-
进程和线程的区别2013-12-12 3957
全部0条评论

快来发表一下你的评论吧 !
