

malloc在Linux上执行的是哪个系统调用
描述
malloc底层为什么是内存池
malloc大家都用过,其是库函数。我们都知道库函数在不同的操作系统中其实执行的是系统调用,那么malloc在Linux上执行的是哪个系统调用呢?
brk()和mmap(),至于为什么是两个,这跟ptmalloc内存池的分配策略有关,稍后介绍。
既然是系统调用,那么就必须处于内核态去处理,而系统内核态的进入往往又经过中断机制。
其大概来说是这么个经过:
1.保存用户当前栈esp和页ss
2.切换到内核态
3.根据中断号找到相应的处理函数
4.执行完后恢复栈esp和页ss
所以说,这个系统调用的开销是比较大的。看一下以下代码:
for(int i=0;i< 100000;i++)
{
int* p = (int*)malloc(sizeof(int));
}
如果不采用内存池的设计,这个代码就会执行10w次系统调用,这无疑是非常大的开销。
ptmalloc的设计概念
Linux下的内存分配
刚刚说了malloc执行的是两个系统调用,分别是brk和mmap,那么这两个又有什么区别呢?
先来看看Linux下内存的一个布局:
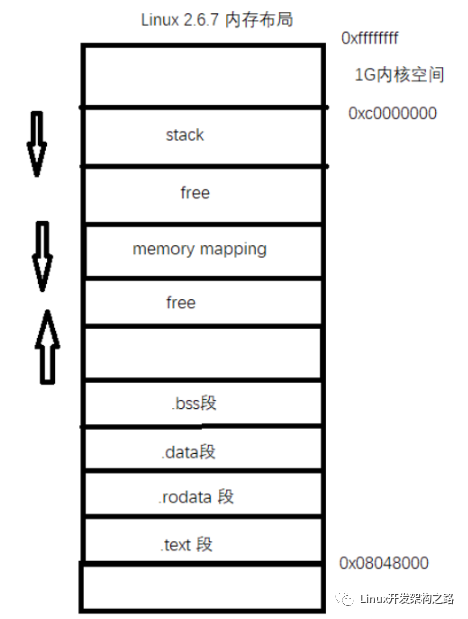
在这里我们可以着重关注两个区:heap(堆区) memory mapping(内存映射区)
为什么着重说他们两个呢?
因为与ptmalloc分配策略息息相关。
brk函数其实就是在heap分配空间,在ptmalloc的设计中有start_brk和brk两个标志,他们两个的差值标记着堆区的大小。一开始这两个值是相同的,但是随着ptmalloc去调用brk函数,brk标记不断向高地址区域偏移,标记着heap堆区被分配出去了。
mmap函数则是在memory mapping区域分配空间,memory mapping区域除了我们常知道的映射动态库对象或者文件,其空间还可以被mmap映射至物理内存。
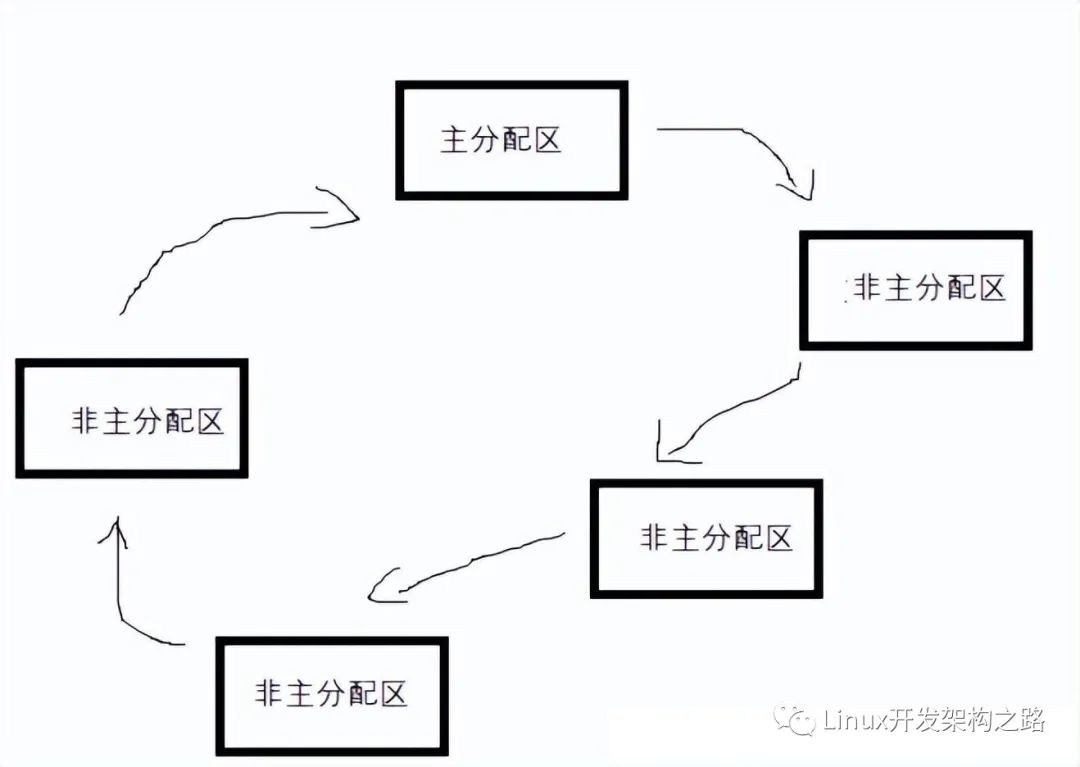
分配区
分配区的概念是针对多线程来说的,当在多线程的条件下,一个进程会有一个一个主分配区和0至多个从分配区。为什么要这么设计呢?
主分配区和从分配区:
主分配区一个进程只能有一个,其是调用brk,从堆区去分配内存。
从分配区一个线程可以拥有多个从分配区,其调用mmap从memory mapping区域去分配一个sub-heap
因为内存是存在竞争的,为了线程安全,当一个线程在使用这个分配区的时候,其他线程不可访问,这个时候又不可能给这个线程挂起,挂起多线程存在的意义何在?
所以,ptmalloc这里的策略就是开辟一个新的分配区,这个新的分配区一定是从分配区。一般来说,从分配区的数量不会超过线程数。
而所有的分配区会被指针相连,形成一个环形链表,保证每个分配区都尽可能的被用到。
chunk块是什么?
chunk块是ptmalloc中最基本的内存单元,ptmalloc把它组织成一个双向链表,每次分配都是从这个链表的尾部去取chunk块,用完了再把它插入到链表的头部。

bins又是什么?
bins是ptmalloc用来维护chunk的一个数据结构,其和哈希思想十分相似。bins本身可以看成一个数组,这个数组总共有128个整型数据,每个整型数据叫bin,其中第1个整型数据表示unsorted bin,其是用来chunk复用或者释放策略实施的。从第2个bin到第64个bin统称为small bins,每个相邻的samll bin相差8,这个bin上代表的数据就是其维护的chunk中可用给用户的字节大小。从第65个开始到127个就属于large bins了,每个相邻的large bin相差64。

Fast Bins
一般情况下,程序其实对小块内存是十分热衷的。当分配其刚刚合并了几块小的chunk之后,也许又有一个小块内存的需求,那么这个时候我又需要去切割chunk块,这想想就挺低效的。
所以ptmalloc的策略是维护一个Fast Bin,这个bin中维护小于等于64B的chunk。
当一个小于64B的chunk被释放后,首先会被放在Fast Bin中斌给不改变其标志位P,这样也就无法去合并这个chunk块。但是在一个特定的时候,ptmalloc会便利fast bins中的chunk块,合并相邻的空闲啊chunk块,并且将其添加到unsorted bin 中,然后加入到相应的bins中。
unsorted bin
unsorted bin的队列中使用bins数组的第一个,如果是释放的chunk大于64B,这个chunk就会被放在这里。
当分配的时候,优先去fast bins中去找,没有找到就去unsorted bin,如果这里也没找到,ptmalloc就会将unsorted bin中的代码加入bins中,然后去bins中找。
top chunk
并不是所有的chunk都是由bin去维护的,有三个例外情况:top chunk,mmaped chunk和last remainder(不讲)。
刚刚说了,从分配去会从memory mapping区域去分配一个sub-heap。在这个内存的最高处就会存在一个top chunk,当bins也不能满足用户需求的时候,才去这个top chunk去分配空间,如果top chunk也不够,那么再分配一个sub-heap,合并。

mmaped chunk
如果top chunk也不能满足要求,那么ptmalloc就会使用mmap直接去将页映射到内存空间,这个chunk在被free的时候直接解除映射。
ptmalloc 的分配策略
- 获取分配区锁,加锁成功则使用该分配区分配内存,否则就遍历分配区的环形链表。如果链表中没有空闲的,就开辟一个新的分配区,把其加入线程私有实例并且加入到环形链表。
- 将用户请求的字节向上对齐到bins中的最近字节。
- 如果小于64B就在fast bin中分配内存,如果大于再去判断是否小于512B,如果小于就去small bin中分配大小,如果大于就说明此时分配的是大内存。
- 首先会将fast bin中的chunk进行合并,然后链接至unsorted bin,再将其链接到相应的bin中
- 然后去large bins中进行寻找,如果够用结束,不够下一步。
- 这个时候就需要判断top chunk是否够用,不够用下一步
- 有两种选择,判断分配的字节大小是否大于等于mmap分配阈值,如果小于根据分配区去选择brk还是mmap去增加top chunk的大小;如果大于就直接调用mmap去映射。

ptmalloc 的内存释放策略
- 获取分配区的锁
- 判断free参数是否位nullptr,如果为nullptr则什么都不做
- 如果释放空间为mmaped chunk,直接使用munmap释放
- 如果size < 64B且不和top chunk相邻,放入fast bin
- 判断前一个块是否空闲,空闲则合并
- 判断下一个是否空闲,空闲则合并放入unsorted bin,然后放入相应的bin中
- 判读合并后是否大于64kb,如果大于fast bin中chunk进行合并,放入unsorted bin,然后下一步。
- 判读top chunk是否大于128kb,如果大于就会归还给操作系统。注意:如果为非主分配区,就只会归还一部部分。

可以看到,只有当chunk前后合并之后大于64k才会进行堆收缩策略,但是实际上,这个条件比较难以触发,ptmalloc管理的内存是越分配越多的。
在这个时候,一般都会给项目配上自己相应的内存池。这个就是二级空间配置器。
SGI STL 二级空间配置器
SGI也实现了自己相应的内存池,称为二级空间配置器。而malloc所依赖的ptmalloc则是一级空间配置器。
SGI这里的策略是,对于大于128字节的数据,调用malloc进行分配,而小于的,则是在自己实现的内存池中进行分配。
这个自己实现的内存池,基本和ptmalloc中bin的思想一致。
但是这里有一点是要注意的,它不是从尾部分配,其每个bin的指针指向了下一个空闲的chunk,如果归还了,则使用链表的头插法。而在一开始,以8字节为例,他会分配20个chunk块,其中10个返回给用户使用,剩下10个备用。如果下次分配24字节,则会从备用的chunk中分出3*8=24,三个chunk块。

-
Linux内核中系统调用详解2023-08-23 1414
-
添加Linux系统调用与利用QEMU测试2023-10-01 1739
-
C语言入门教程-malloc函数和free函数2009-07-29 5019
-
基于linux系统实现的vivado调用VCS仿真教程2018-07-05 12762
-
在linux操作系统中如何截获系统调用2017-11-07 865
-
通过实现一个简单的malloc来描述malloc背后的机制2018-01-27 5104
-
透了解系统调用助你成为Linux下编程高手2018-05-11 4506
-
Linux系统ELF程序的执行过程2019-04-27 3968
-
linux设备驱动模型一字符设备open系统调用流程2019-04-26 3074
-
Linux下系统调用的技巧2019-04-02 721
-
如何区分xenomai、linux系统调用/服务2022-05-10 3177
-
Linux内核系统调用概述及实现原理2022-05-14 3245
-
Linux系统调用的具体实现原理2023-09-05 2154
-
Linux系统调用概述2023-11-09 1577
-
如何实现一个malloc2023-11-13 1875
全部0条评论

快来发表一下你的评论吧 !
