

基于深度学习的3D点云实例分割方法
人工智能
描述
作者:PCIPG-HAY
现有的 3D 实例分割方法以自下而上的设计为主——手动微调算法将点分组为簇,然后是细化网络。然而,由于依赖于聚类的质量,当(1)具有相同语义类的附近对象被打包在一起,或(2)具有松散连接区域的大型对象时,这些方法会产生容易受到影响的结果。为了解决这些限制,我们引入了 ISBNet,这是一种新颖的cluster-free方法,它将实例表示为内核并通过动态卷积解码实例掩码。为了有效地生成高召回率和判别力的内核,我们提出了一种名为“实例感知最远点采样”的简单策略来对候选进行采样,并利用受 PointNet++ 启发的本地聚合层对候选特征进行编码。此外,我们还表明,在动态卷积中预测和利用 3D 轴对齐边界框可以进一步提高性能。我们的方法在 ScanNetV2 (55.9)、S3DIS (60.8) 和 STPLS3D (49.2) 上的 AP 上设置了新的最先进结果,并保留了快速推理时间(ScanNetV2 上每个场景 237 毫秒)。
1.引言
3D实例分割(3DIS)是3D领域深度学习的核心问题。给定由点云表示的 3D 场景,我们寻求为每个点分配语义类和唯一的实例标签。 3DIS 是一项重要的 3D 感知任务,在自动驾驶、增强现实和机器人导航等领域有着广泛的应用,其中可以利用点云数据来补充 2D 图像提供的信息。与 2D 图像实例分割 (2DIS) 相比,3DIS 可以说更难,因为外观和空间范围的变化更大,而且点云分布不均匀,即靠近物体表面密集而其他地方稀疏。因此,将 2DIS 方法应用于 3DIS 并非易事。
3DIS 的典型方法是 DyCo3D,采用动态卷积来预测实例掩码。具体来说,点被聚类、体素化,并通过 3D Unet 生成实例内核,用于与场景中所有点的特征进行动态卷积。这种方法如图 2 (a) 所示。然而,这种方法有一些局限性。首先,聚类算法严重依赖质心偏移预测,其质量在以下情况下显着恶化:(1) 对象密集,导致两个对象可能被错误地组合在一起作为一个对象,或 (2) 各部分连接松散的大型对象结果聚类在不同的对象中。这两种情况如图 1 所示。其次,点的特征主要编码对象外观,其不足以区分不同的实例,特别是在具有相同语义类的对象之间。这里也推荐「3D视觉工坊」新课程《三维点云处理:算法与实战汇总》。
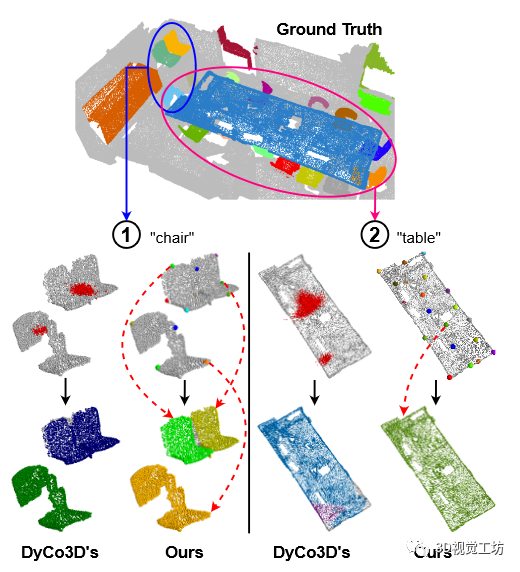
图 1. 在 DyCo3D中,内核预测质量很大程度上受到基于质心的聚类算法的影响,该算法有两个问题:1 对附近实例进行错误分组,2 将大对象过度分割成多个片段。我们的方法通过实例感知点采样解决了这些问题,取得了更好的结果。每个样本点都会聚合来自其本地上下文的信息,以生成用于预测其自己的对象掩码的内核,并且最终实例将由 NMS 进行过滤和选择。
为了解决 DyCo3D 的局限性,我们提出了 ISBNet,这是一种用于 3DIS 的无集群框架,具有实例感知最远点采样和框感知动态卷积。首先,我们重新审视最远点采样(FPS)和大量聚类方法,发现这些算法产生的实例召回率相当低。结果,在后续阶段遗漏了许多对象,导致性能不佳。受此启发,我们提出了实例感知最远点采样(IA-FPS),其目的是在具有高实例召回率的 3D 场景中对查询候选进行采样。然后,我们介绍点聚合器,将 IA-FPS 与本地聚合层结合起来,将实例的语义特征、形状和大小编码为实例特征。
此外,对象的 3D 边界框是现有的监督,但尚未在 3D 实例分割任务中进行探索。因此,我们在模型中添加一个辅助分支来联合预测每个实例的轴对齐边界框和二进制掩码。地面实况轴对齐边界框是从现有实例掩码标签推导出来的。与 Mask-DINO和 CondInst不同,辅助边界框预测仅用作学习过程的正则化,我们将其用作动态卷积中的额外几何线索,从而进一步提高了实例分割任务。
为了评估我们方法的性能,我们对三个具有挑战性的数据集进行了广泛的实验:ScanNetV2 、S3DIS和 STPLS3D。 ISBNet 不仅在这三个数据集中实现了最高的准确率,在 ScanNetV2、S3DIS 和 STPLS3D 上超过了最强的方法 +2.7/3.4/3.0,而且还表现出很高的效率,在 ScanNetV2 上每个场景的运行时间为 237ms。总而言之,我们的工作贡献如下:
(i) 我们提出了 ISBNet,一种 3DIS 的cluster-free范例,它利用实例感知的最远点采样和点聚合器来生成实例特征集。
(ii) 我们首先介绍使用轴对齐边界框作为辅助监督,并提出框感知动态卷积来解码实例二进制掩码。
(iii) ISBNet 在三个不同数据集上实现了最先进的性能:ScanNetV2、S3DIS 和 STPLS3D,无需对每个数据集的模型架构和超参数调整进行全面修改。
2.相关工作
**2D 图像实例分割 (2DIS) **涉及为图像中的每个像素分配实例标签和语义标签之一。它的方法可以分为三组:基于提案的方法、无提案的方法和基于 DETR 的方法。对于基于提案的方法 ,利用对象检测器(例如 Faster-RCNN)来预测对象边界框,以分割检测到的框内的前景区域。对于无提议方法,SOLO 和 CondInst 使用特征图预测动态卷积的实例内核以生成实例掩码。对于基于 DETR 的方法 ,Mask2Former和 Mask-DINO采用带有实例查询的转换器架构来获取每个实例的分割。与 3DIS 相比,由于 2D 图像的结构化、基于网格和密集的特性,2DIS 可以说更容易。因此,将 2DIS 方法应用于 3DIS 并非易事。
3D 点云实例分割 (3DIS) 方法
感兴趣的是使用语义类和唯一实例 ID 来标记 3D 点云中的每个点。它们可以分为基于提议的方法、基于聚类的方法和基于动态卷积的方法。
基于提案的方法首先检测 3D 边界框,然后分割每个框内的前景区域以形成实例。 3D-SIS 将 Mask R-CNN 架构应用于 3D 实例分割,并联合学习 RGB 图像和 3D 点云两种模式的特征。 3D-BoNet从总结场景内容的全局特征向量中预测固定数量的 3D 边界框,然后分割每个框内的前景点。这种方法的局限性在于,实例掩模的性能很大程度上取决于 3D 边界框的质量,由于 3D 点云的巨大变化和不均匀分布,3D 边界框非常不稳定。
基于聚类的方法学习潜在嵌入,有助于将点分组到实例中。 PointGroup预测从每个点到其实例质心的 3D 偏移,并从两个点云获取簇:原始点和质心偏移点。 HAIS提出了一种层次聚类方法,其中小簇可以被较大的簇过滤掉或吸收。 SoftGroup提出了一种软分组策略,其中每个点可以属于具有不同语义类别的多个簇,以减轻语义预测误差。基于聚类的方法的局限性之一是实例掩模的质量很大程度上取决于聚类的质量,即质心预测,这是非常不可靠的,特别是当测试对象在空间范围上与训练对象有很大不同时。
基于动态卷积的方法通过生成内核,然后使用它们与点特征进行卷积来生成实例掩码,来克服基于提案和基于聚类的方法的局限性。 DyCo3D采用中的聚类算法来生成动态卷积的内核。 PointInst3D使用最远点采样来代替中的聚类来生成内核。 DKNet [38]引入候选挖掘和候选聚合来为动态卷积生成更具辨别力的实例内核。
我们的方法是一种基于动态卷积的方法,在内核生成和动态卷积方面有两个重要的改进。特别是,在前者中,我们提出了一种新的实例编码器,将实例感知的最远点采样与点聚合层相结合,以生成内核来取代 DyCo3D 中的聚类。在后者中,我们不仅使用动态卷积的外观特征,还使用几何提示(即边界框预测)增强了该特征。
3.本文方法
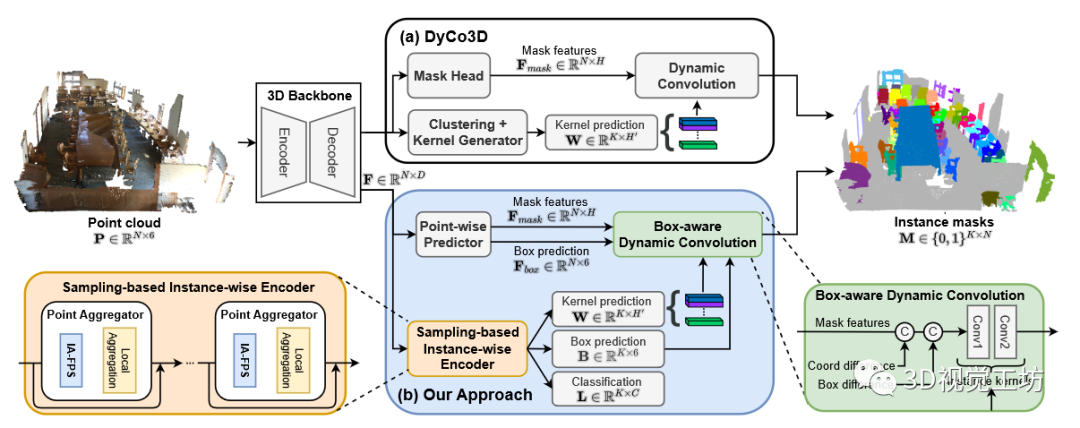
图 2. DyCo3D 的总体架构(块 (a))和我们的 3DIS 方法(块 (b))。给定点云,使用 3D 主干来提取每点特征。对于 DyCo3D,它首先根据每个点的预测对象质心将点分组为簇,为每个簇生成一个内核。同时,掩模头将每点特征转换为掩模特征以进行动态卷积。对于我们的 ISBNet 方法,我们用一种新颖的基于采样的实例编码器替换了聚类算法,以获得更快、更鲁棒的内核、框和类预测。此外,逐点预测器取代了 DyCo3D 的掩码头,以输出掩码和框特征,用于新的框感知动态卷积,以生成更准确的实例掩码。
问题陈述:给定一个 3D 点云,其中 N 是点的数量,每个点由 3D 位置和 RGB 颜色向量表示。我们的目标是将点云分割成 K 个实例,这些实例由一组二进制掩码 和一组语义标签表示,其中 C 是语义类别的数量。
我们的方法由四个主要组件组成:3D 主干网络、逐点预测器、基于采样的实例编码器和盒感知动态卷积。 3D 主干网采用 3D 点云作为输入来提取每个点特征。我们的主干网络提取特征其中 i = 1,... , N 为输入点云的每个点。我们遵循之前的方法,采用带有稀疏卷积 的 U-Net 作为主干。逐点预测器从主干网络获取每点特征并将其转换为逐点语义预测、轴对齐边界框预测 和用于框感知动态卷积的掩模特征。基于采样的实例级编码器(第 3.1 节)处理逐点特征以生成实例内核、实例类标签和边界框参数。最后,盒子感知动态卷积(第 3.2 节)获取实例内核和掩码特征以及互补框预测,以生成每个实例的最终二进制掩码。我们的方法的概述如图 2 所示。
3.1基于采样的实例编码器
给定主干网输出的每点特征 ,我们的目标是产生实例特征,其中 K ≪ N 。实例特征E被用于预测实例分类分数 、实例框和实例内核,其中 H′ 由动态卷积中卷积层的大小决定。
通常,可以采用最远点采样 (FPS)对一组 K 个候选进行采样,以生成实例内核。 FPS 通过使用成对距离选择距先前采样点最远的下一个点来贪婪地采样 3D 坐标中的点。然而,这种采样技术较差。首先,FPS采样的K个候选点中有很多属于背景类别的点,浪费了计算资源。其次,大物体在采样点的数量中占主导地位,因此不会从小物体中采样任何点。第三,逐点特征无法捕获本地上下文来创建实例内核。我们在选项卡中提供分析。 1 来验证这一观察结果。特别是,我们计算了内核预测的实例数量相对于总的真实实例的召回率。召回值应该很大,因为我们期望对真实实例上的聚类或采样点进行良好的覆盖。然而,可以看出,以前的方法的召回率较低,这可以解释为这些方法没有考虑点聚类或采样的实例。
为了解决这个问题,我们提出了一种新颖的基于采样的实例编码器,它在点采样步骤中考虑了实例。受 PointNet++中的Set Abstraction的启发,我们指定实例编码器包含一系列点聚合器 (PA) 块,其组件是实例感知 FPS (IA-FPS),以对覆盖尽可能多的前景对象的候选点进行采样,并且本地聚合层捕获本地上下文,从而单独丰富候选特征。我们将图 2 中橙色块中的 PA 可视化,并在下面详细介绍我们的采样。
实例感知 FPS。我们的采样策略是对前景点进行采样,以最大程度地覆盖所有实例,无论其大小如何。为了实现这一目标,我们选择如下迭代采样技术。具体来说,候选者是从一组点中采样的,这些点既不是背景也不是先前采样的候选者选择的。我们使用逐点语义预测来估计每个点成为背景的概率。我们还使用由前 k 个候选生成的实例掩码。利用 FPS 从点集 P′ ⊂ P 中采样点:
(1)
其中 K′ 是已选择的候选者的数量,τ 是超参数阈值。
实际上,在训练中,由于实例掩码预测不足以指导实例采样,因此从预测的前景掩码中一次性采样 K 个候选者。另一方面,在测试中,我们迭代地采样较小的块 一个接一个地使得后续块既不会从背景点采样,也不会从属于先前块的预测掩模的点采样。通过这样做,IA-FPS 的召回率提高了很多,如表 1 所示。
本地聚合层。对于每个候选 k,本地聚合层将本地上下文编码并转换为其实例特征。具体来说,采用 Ball-query [29] 来收集其 Q 个局部邻居作为局部特征。此外,计算候选者 k 与其邻居 q 之间的相对坐标,并用邻域半径 r 进行归一化以形成局部坐标,或。接下来,我们使用 MLP 层将局部特征和局部坐标 转换为候选 k 的实例特征。我们还添加了与原始特征的残差连接以避免梯度消失。具体来说,实例级特征可以计算为:
(2)
在哪里 [·; ·]表示串联运算。从 E 开始,使用线性层来预测实例分类分数 L、实例框 B 和实例内核 W。
值得注意的是,为了获得实例级特征 E,我们不使用单个 PA 块,而是提出了一种渐进的方法,即顺序应用多个 PA 块。这样,后续块将从前一个块采样的较少数量的点中进行采样。这样做与在 2D 图像中堆叠多个卷积层以增加感受野具有相同的效果。
3.2包络盒感知的动态卷积
在[16,17,38]的动态卷积中,对于每个候选k,所有点w.r.t k的相对位置,和逐点掩码特征被连接起来与实例核进行卷积,得到实例二进制掩码,其中 Conv 被实现为多个卷积层。然而,我们认为仅使用掩模特征和位置并不是最优的。例如,当仅使用 3D 中的掩模特征和位置时,类相同的相邻对象边界附近的点彼此无法区分。
另一方面,3D 边界框描绘了对象的形状和大小,这为实例分割中对象掩模的预测提供了重要的几何线索。我们的方法使用边界框预测作为规范化实例分割的辅助任务训练。特别是,对于每个点,我们建议回归从对象掩模推导出来的轴对齐边界框。然后使用预测框来调节掩模特征,以生成框感知动态卷积的内核(参见图 2 中的绿色块)。每个边界框由 6D 向量参数化,表示实例点坐标的最小和最大边界。值得注意的是,我们选择使用轴对齐的边界框,因为地面实况框基本上是免费的,因为它们可以很容易地从地面实况实例注释构建。
因此,我们建议使用预测框作为动态卷积中的附加几何线索,给出我们提出的框感知动态卷积的名称。直观上,如果两个点的预测框相似,则它们将属于同一对象。我们的最终实例掩码 第 k 个候选者获得为:
(3)
几何特征可以根据第 k 个候选实例预测的边界框与输入点云 P 中的 N 个点的绝对差计算得出,即。
3.3网络训练
我们使用 Pointwise Loss 和 Instance-wise Loss 来训练我们的方法。前者是在逐点预测中产生的,即语义分割的交叉熵损失,以及边界框回归的L1损失和gIoU损失[31]。后者是在每个实例预测中发生的,即分类、框预测和掩模预测,使用[20]提出的用于 2D 对象检测的一对多匹配损失。具体来说,匹配成本是实例分类和实例掩码的组合:
(4)
其中 是两个掩模之间的骰子损失。准确地说,通过在匈牙利匹配中复制地面实况 S 次,将 S 个预测掩码与一个地面实况掩码进行匹配。这样,训练收敛速度要快得多,并且掩模预测性能比 DETR提出的一对一匹配要好。然后,真实掩码与其匹配的预测掩码之间产生的实例损失定义为:
(5)
其中Lcls是交叉熵损失,是dice损失和BCE损失的组合,是L1损失和gIoU损失的组合,是Mask-Scoring损失。
4.实验
4.1实验设计
数据集。我们在三个数据集上评估我们的方法:ScanNetV2 [8]、S3DIS [1] 和 STPLS3D [4]。 ScanNetV2 数据集由 1201、312 和 100 个扫描组成,分别具有 18 个对象类,用于训练、验证和测试。与之前的工作一样,我们报告了 ScanNetV2 验证集和测试集的评估结果。 S3DIS数据集包含来自6个区域、13个类别的271个场景。我们报告了区域 5 和区域 6 交叉验证的评估。 STPLS3D 数据集是来自真实世界和合成环境的航空摄影测量点云数据集。它包括25个总面积为6平方公里的城市场景和14个实例类别。继[5, 34]之后,我们使用场景 5、10、15、20 和 25 进行验证,其余部分进行训练。
评估指标。采用物体检测和实例分割任务常用的平均精度,即AP50和AP25分别是IoU阈值50%和25%时的分数,AP是IoU阈值50%到95%时的平均分数,步长为 5%。 Box AP 表示 3D 轴对齐边界框预测的平均精度。此外,还使用平均覆盖率 (mCov)、平均加权覆盖率 (mWCov)、平均精度 (mPrec50) 和平均召回率 (mRec50) 进行评估,IoU 阈值为 50%。
实施细节。我们使用 PyTorch 深度学习框架 [27] 实现我们的模型,并在单个 V100 GPU 上使用 AdamW 优化器对其进行 320 个时期的训练。批量大小设置为 16。学习率初始化为 0.004,并通过余弦退火进行调度 [41]。根据[34],我们将 ScanNetV2 和 S3DIS 的体素大小设置为 0.02m,将 STPLS3D 的体素大小设置为 0.3m,因为它的稀疏性和更大的规模。在训练中,场景被随机裁剪,最大数量为 250,000 个点。在测试中,整个场景都被输入网络而不进行裁剪。我们使用与[34]中相同的主干设计,输出 32 个通道的特征图。基于采样的实例感知编码器中使用了两层 PA 的堆栈。 τ 设置为 0.5。我们将这两层的球查询半径 r 设置为 0.2 和 0.4,并将两层的邻居数量 Q = 32。我们还实现了具有隐藏维度为 32 的两层的盒感知动态卷积。γmask 设置为 5。λbox、λmask 和 λms 分别设置为 1、5 和 1。在训练中,我们设置 S = 4 和 K = 256。在推理中,我们设置 K = 384 并使用非极大值抑制来删除阈值为 0.2 的冗余掩模预测。遵循[14,26,38],我们利用超级点[23,24]来对齐ScanNetV2数据集上的最终预测掩模。
4.2主要结果
ScanNetV2。我们在表2中报告隐藏测试集的实例分割结果,在表3中的验证集上报告了目标检测和实例分割的结果。 在隐藏测试集上,ISBNet 在 AP/AP50 中取得了 55.9/76.6 的成绩,在 ScanNetV2 基准上创下了新的 state-of-the-art 性能。在验证集上,我们提出的方法以较大的优势超越了第二好的方法,在 AP/AP50/AP25 中为 +3.7/5.5/3.6,在 Box AP50/Box AP25 中为 +2.6/6.5。
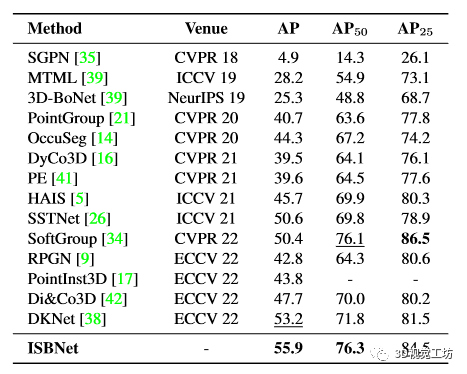
表 2. ScanNetV2 隐藏测试集上的 3D 实例分割结果(以 AP 分数表示)。最好的结果以粗体显示,次好的结果以下划线显示。我们提出的方法实现了最高的 AP,优于之前最强的方法。
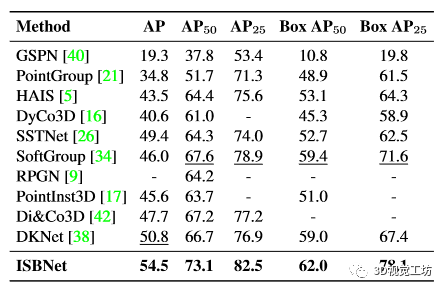
表 3. ScanNetV2 验证集上的 3D 实例分割和 3D 对象检测结果。
S3DIS。表 4 总结了 S3DIS 数据集的 5 区和 6 倍交叉验证的结果。在 Area 5 和交叉验证评估中,我们提出的方法在几乎所有指标上都大幅超越了最强的方法。在6倍交叉验证评估中,我们在mCov/mWCov/mRec50中取得了74.9/76.8/77.1,与第二强的方法相比提高了+3.5/2.7/3.1。
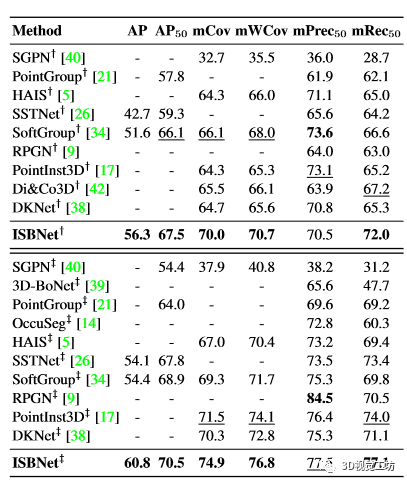
表 4. S3DIS 数据集上的 3D 实例分割结果。标有 † 的方法在区域 5 上进行评估,标有 ‡ 的方法在 6 倍交叉验证中进行评估。
STPLS3D。表5显示了STPLS3D数据集的验证集上的结果。我们的方法在所有指标中实现了最高的性能,并且在 AP/AP50 中超过了第二好的方法 +3.0/2.2。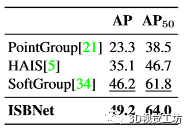
表 5. STPLS3D 验证集上的 3D 实例分割结果。
4.3定性结果
我们在图 3 中可视化我们的方法 DyCo3D [16] 和 DKNet [38] 在 ScanNetV2 验证集上的定性结果。可以看出,我们的方法成功区分了具有相同语义类的附近实例。由于聚类的限制,DyCo3D [16] 错误分割了书架的部分(第 1 行)并合并了附近的沙发(第 2、3 行)。 DKNet [38] 过度分割了第 2 行中的窗口,并且还错误地合并了附近的沙发和桌子(第 3 行)。
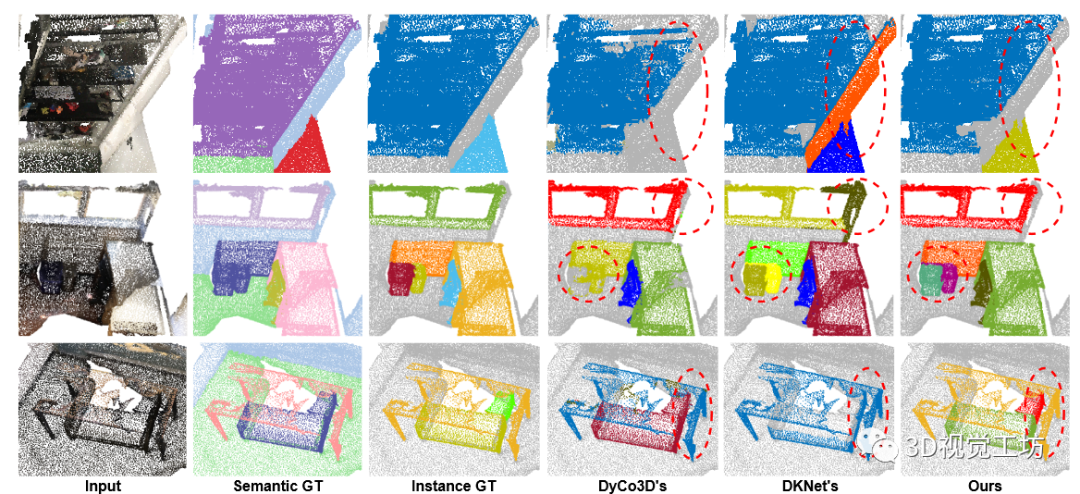
图 3. ScanNetV2 验证集的代表性示例。每行显示一个示例,前三列中包含输入、语义基本事实和实例基本事实。我们的方法(最后一列)生成更精确的实例掩码,特别是在具有相同语义标签的多个实例位于在一起的区域。
4.4消融实验
我们对 ScanNetV2 数据集的验证集进行了一系列消融研究,以研究 ISBNet。
掩模损耗的不同组合的影响如表6所示。值得注意的是,结合使用二元交叉熵和骰子损失会产生最佳结果,AP 为 54.5。
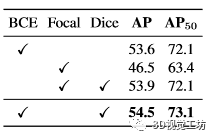
表 6. ScanNetV2 验证集上掩模损失的不同组合的消融研究。
各个组件对整体性能的影响
如表7所示。第 1 行中的 DyCo3D* 是我们对 DyCo3D 的重新实现,其主干与 [5,34,38] 相同,并且使用一对多匹配损失进行训练。第 2 行中的基线是具有标准最远点采样 (FPS)、标准动态卷积(如 [16,17,38] 中所示)且没有本地聚合层 (LAL) 的模型。可以看出,替换 DyCo3D* 中的聚类和微小 Unet 使 AP 中的性能从 49.4 降低到 47.9。当基线中的标准 FPS 替换为实例感知最远点采样 (IAFPS) 时,第 3 行的性能提高到 49.7。当将 LAL 添加到基线模型时,第 4 行的 AP 分数提高到 50.1,并且优于DyCo3D* 的 AP 增加 0.7。只需将标准动态卷积替换为 Box-aware Dynamic Convolution (BA-DyCo),第 5 行的 AP 即可获得 +0.7。特别是,结合 IA-FPS 和 PA 可显着提高性能,AP/AP50 中的 +5.5/+6.8第 6 行。最后,第 7 行的完整方法,ISBNet 在 AP/AP50 中实现了最佳性能 54.5/73.1。
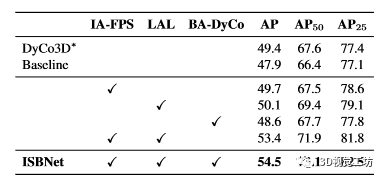
表 7. ISBNet 每个组件对 ScanNetV2 验证集的影响。 IA-FPS:实例感知最远点采样,LAL:本地聚合层,BA-DyCo:盒子感知动态卷积。 *:我们的 DyCo3D 改进版本 [16]。
轴对齐边界框回归的影响
如表 8所示。在不使用边界框作为辅助监督(Aux.)的情况下,我们的方法在 AP/AP50 中达到了 52.8/71.6。在训练过程中添加边界框损失可以使 AP 提高 0.6。特别是,当在动态卷积中使用边界框作为额外的几何线索(Geo.Cue)时,AP/AP50 中的结果显着增加到 54.5/73.1。这证明了我们的主张,即 3D 边界框是区分3D 点云中的实例的关键几何线索。
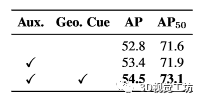
表 8. 3D 轴对齐边界框回归的影响。
点聚合器 (PA) 块数量的影响
如表 9所示。使用单块 PA,我们的方法在 AP/AP50 中达到 53.2/72.5。堆叠两个 PA 块可在这些指标中带来 1.3/0.6 的增益。然而,当我们添加更多块时,AP/AP50 中的结果略有下降至 54.3/73.0。
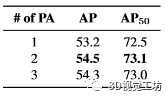
表 9. 点聚合器 (PA) 块的数量。
动态卷积不同设计的影响
如表 10 所示。这里,使用两层具有 32 个隐藏通道的动态卷积给出了最好的结果。仅使用单层动态卷积会导致性能显着下降。另一方面,添加太多层(即三层)会产生更差的结果。减少隐藏通道的数量会稍微降低性能。由于额外的几何线索,即使只有 216 个动态卷积参数,我们的模型也可以在 AP/AP50 中达到 53.6/72.1,证明了盒子感知动态卷积的鲁棒性。这里也推荐「3D视觉工坊」新课程《三维点云处理:算法与实战汇总》。
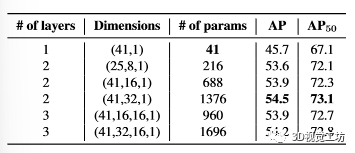
表 10. Box-aware 动态卷积的消融。
IA-FPS 块大小的消融。我们研究了表 11 中推理中 IA-FPS 采样块大小的不同设计。 11. 前三行显示我们一次对 K 个候选样本进行采样时的结果。将样本数量从 256 增加到 384 会稍微提高整体性能,但在样本数为 512 时,AP 结果下降到 53.6。当将 K 分割为较小的大小块 (192,128,64) 并根据式(192,128,64)采样点时: (1),最后一行的AP/AP50性能进一步提升至54.5/73.1。
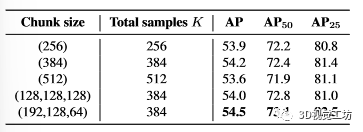
表 11. 迭代采样的样本块大小的消融。
运行时分析。
图 4 报告了同一 Titan X GPU 上 ISBNet 的组件和总运行时间以及 3DIS 的 5 种最新方法。所有方法都可以大致分为三个主要阶段:主干、实例抽象器和掩码解码器。我们的方法是最快的方法,总运行时间仅为 237 毫秒,主干/实例抽象器/掩码解码器阶段为 152/53/32 毫秒。与PointGroup [21]、DyCo3D [16]和SoftGroup [34]中基于聚类的实例抽象器相比,我们基于Point Aggregator的实例抽象器显着减少了运行时间。我们的掩模解码器是通过动态卷积实现的,是这些方法中第二快的。这证明了我们提出的方法的有效性。
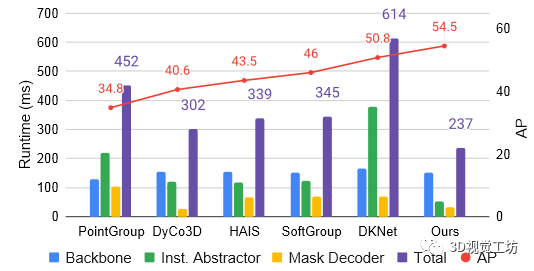
图 4. 组件和总运行时间(以毫秒为单位)以及之前五种方法的 AP 和 ScanNetV2 验证集上的 ISBNet 的结果。
5.结论
在这项工作中,我们引入了 ISBNet,一种简洁的基于动态卷积的方法来解决 3D 点云实例分割的任务。考虑到实例分割模型的性能依赖于候选查询的召回,我们提出了实例感知最远点采样和点聚合器来有效地对 3D 点云中的候选进行采样。此外,利用 3D 边界框作为辅助监督和动态卷积的几何提示进一步提高了模型的准确性。在 ScanNetV2、S3DIS 和 STPLS3D 数据集上进行的大量实验表明,我们的方法在所有数据集上都实现了稳健且显着的性能提升,大幅超越了 3D 实例分割中最先进的方法,即 +2.7、+2.4、+ 3.0 在 ScanNetV2、S3DIS 和 STPLS3D 上的 AP 中。
我们的方法并非没有局限性。例如,我们的实例感知 FPS 不能保证覆盖所有实例,因为它依赖于当前实例预测来做出点采样决策。我们提出的轴对齐边界框可能无法紧密贴合复杂实例的形状。图 5 显示了一个硬箱,其中冰箱以柜台为界。我们的模型无法区分这些点,因为它们共享相似的边界框。解决这些限制可能会导致未来工作的改进。此外,通过利用对象的几何结构(例如形状和大小)来改进动态卷积的新研究将是一个有趣的研究课题。
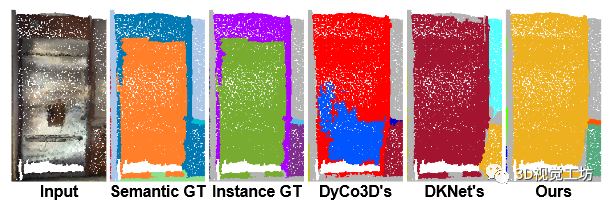
图 5. ScanNetV2 验证集的一个硬案例,其中冰箱被柜台包围。 ISBNet 和以前的方法错误地将这些实例中的点合并到单个对象中。
编辑:黄飞
-
基于深度学习的方法在处理3D点云进行缺陷分类应用2024-02-22 2789
-
基于深度学习和3D图像处理的精密加工件外观缺陷检测系统2022-03-08 28309
-
3D点云技术介绍及其与VR体验的关系2017-09-15 1617
-
基于3D相机深度图像的室内三维平面分割2017-11-16 1086
-
实现快读高效且稳健的3D稀疏点云的分割2018-11-16 6774
-
3D的感知技术及实践2020-10-23 4476
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1506
-
何为3D点云语义分割2022-07-21 10675
-
基于深度学习的3D分割综述(RGB-D/点云/体素/多目)2022-11-04 3545
-
首个无监督3D点云物体实例分割算法2022-11-09 3717
-
一种有效将3D点云分割成平面组件的多分辨率方法2023-01-09 2118
-
一个基于学习的LiDAR点云3D线特征分割和描述模型2023-01-12 2770
-
NeuralLift-360:将野外的2D照片提升为3D物体2023-04-16 3236
-
基于深度学习的点云分割的方法介绍2023-07-20 793
-
NeurlPS'23开源 | 首个!开放词汇3D实例分割!2023-11-14 1841
全部0条评论

快来发表一下你的评论吧 !
