

epoll模型介绍
描述
什么是select?
有的朋友可能对select也不是很了解啊,我这里稍微科普一下:网络连接,服务器也是通过文件描述符来管理这些连接上来的客户端,既然是供连接的服务器,那就免不了要接收来自客户端的消息。那么多台客户端,消息那么的多,要是漏了一条两条重要消息,那也不要用TCP了,那怎么办?
前辈们就是有办法,轮询,轮询每个客户端文件描述符,查看他们是否带着消息,如果带着,那就处理一下;如果没带着,那就一边等着去。这就是select,轮询,颇有点领导下基层的那种感觉哈。
但是这个select的轮询呐,会有个问题,明眼人一下就能想到,那即是耗费资源啊,耗费什么资源,时间呐,慢呐(其实也挺快了,不过相对epoll来说就是慢)。 再认真想一下,还浪费什么资源,系统资源。有的客户端呐,占着那啥玩意儿不干那啥事儿,这种客户端呐,还不少。这也怪不得人家,哪儿有客户端时时刻刻在发消息,要是有,那就要小心是不是恶意攻击了。那把这么一堆偶尔动一下的客户端的文件描述符一直攥手里,累不累?能一次攥多少个?就像一个老板,一直想着下去巡视,那他可以去当车间组长了哈哈哈。
所以,select的默认上限一般是1024(FD_SETSIZE),当然我们可以手动去改,但是人家给个1024自然有人家的道理,改太大的话系统在这一块的负载就大了。 那句话怎么说的来着,你每次对系统的索取,其实都早已明码标价!哈哈哈。。。
所以,我们选用epoll模型。
什么是epoll?
epoll接口是为解决Linux内核处理大量文件描述符而提出的方案。该接口属于Linux下多路I/O复用接口中select/poll的增强。其经常应用于Linux下高并发服务型程序,特别是在大量并发连接中只有少部分连接处于活跃下的情况 (通常是这种情况),在该情况下能显著的提高程序的CPU利用率。
前面说,select就像亲自下基层视察的老板,那么epoll这个老板就要显得精明的多了。他可不亲自下基层,他找了个美女秘书,他只要盯着他的秘书看就行了,呸,他只需要听取他的秘书的汇报就行了。汇报啥呢?基层有任何消息,跟秘书说,秘书汇总之后一次性交给老板来处理。这样老板的时间不就大大的提高了嘛。
如果你学过设计模式,这就是典型的“命令模式”,非常符合“依赖倒置原则”,这是一个非常美妙的模式,这个原则也是我最喜欢的一个原则,将高层实现与低层实现解耦合,从而可以各自开发,只要接口一致便可,这个接口,就是秘书。
扯远了,如果对“设计模式”有兴趣,可以找我的专栏。
好,言归正传哈哈哈。
epoll的设计思路
- (1)epoll在Linux内核中构建了一个文件系统,该文件系统采用红黑树来构建,红黑树在增加和删除上面的效率极高,因此是epoll高效的原因之一。有兴趣可以百度红黑树了解,但在这里你只需知道其算法效率超高即可。
- (2)epoll提供了两种触发模式,水平触发(LT)和边沿触发(ET)。当然,涉及到I/O操作也必然会有阻塞和非阻塞两种方案。目前效率相对较高的是 epoll+ET+非阻塞I/O 模型,在具体情况下应该合理选用当前情形中最优的搭配方案。
- (3)epoll所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于1024,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以下面语句查看,一般来说这个数目和系统内存关系很大。
阻塞I/O与非阻塞I/O
为了方便理解后面的内容,我们先看几张图,关于阻塞与非阻塞I/O的。
阻塞式文件I/O
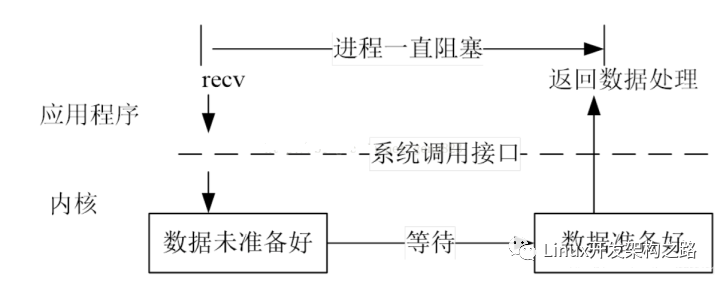
非阻塞式文件I/O

多路复用I/O

好,有了上面这几张图垫着,咱来看看边缘触发和水平触发。
边缘触发 VS 水平触发
EPOLL 事件有两种模型: Edge Triggered (ET) 边缘触发 只有新数据到来,才触发,不管缓存区中是否还有数据。 Level Triggered (LT) 水平触发 只要有数据都会触发,不管数据是哪里的。 (这样表述会不会好理解一些)
LT(level triggered) 是 缺省 的工作方式 ,并且同时支持 block 和 no-block socket. 在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的 fd 进行 IO 操作。如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点。传统的 select/poll 都是这种模型的代表.
ET(edge-triggered) 是高速工作方式 ,只支持 no-block socket 。在这种模式下,当描述符从未就绪变为就绪时,内核通过 epoll 告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了 ( 比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个 EWOULDBLOCK 错误)。但是请注意,如果一直不对这个 fd 作 IO 操作 ( 从而导致它再次变成未就绪 ) ,内核不会发送更多的通知 (only once), 不过在 TCP 协议中, ET 模式的加速效用仍需要更多的 benchmark 确认。
要设置ET:在epoll_ctl函数中配置上EPOLLET即可
epoll 工作在 ET 模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读 / 阻塞写操作把处理多个文件描述符的任务饿死。最好以下面的方式调用 ET 模式的 epoll 接口,在后面会介绍避免可能的缺陷。
- 基于非阻塞文件句柄
- 只有当 read(2) 或者 write(2) 返回 EAGAIN 时才需要挂起,等待。但这并不是说每次 read() 时都需要循环读,直到读到产生一个 EAGAIN 才认为此次事件处理完成,当 read() 返回的读到的数据长度小于请求的数据长度时,就可以确定此时缓冲中已没有数据了,也就可以认为此事读事件已处理完成。
epoll API
epoll提供的API,我所用过的其实不多,无非就那么几个。 所以我就只能聊聊我说用过的。
头文件
#include< sys/epoll.h >
创建句柄
int epoll_create(int size);
创建一个epoll句柄,参数size用于告诉内核监听的文件描述符个数,跟内存大小有关。 返回epoll 文件描述符
控制某个epoll监控的文件描述符上的事件:注册,修改,删除
参数释义: epfd:为epoll的句柄 op:表示动作,用3个宏来表示 ··· EPOLL_CTL_ADD(注册新的 fd 到epfd) ··· EPOLL_CTL_DEL(从 epfd 中删除一个 fd) ··· EPOLL_CTL_MOD(修改已经注册的 fd 监听事件)
event:告诉内核需要监听的事件
typedef union epoll_data
{
void* ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t; /* 保存触发事件的某个文件描述符相关的数据 */
struct epoll_event
{
__uint32_t events; /* epoll event */
epoll_data_t data; /* User data variable */
};
/* epoll_event.events:
EPOLLIN 表示对应的文件描述符可以读
EPOLLOUT 表示对应的文件描述符可以写
EPOLLPRI 表示对应的文件描述符有紧急的数据可读
EPOLLERR 表示对应的文件描述符发生错误
EPOLLHUP 表示对应的文件描述符被挂断
EPOLLET 设置ET模式
*/
epoll消息读取
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
等待所监控文件描述符上有事件的产生
参数释义: events:用来从内核得到事件的集合 maxevent:用于告诉内核这个event有多大,这个maxevent不能大于创建句柄时的size timeout:超时时间 ··· -1:阻塞 ··· 0:立即返回 ···>0:指定微秒
成功返回有多少个文件描述符准备就绪,时间到返回0,出错返回-1.
代码示例
/* 实现功能:通过epoll, 处理多个socket
* 监听一个端口,监听到有链接时,添加到epoll_event
* xs
*/
#include < stdio.h >
#include < stdlib.h >
#include < string.h >
#include < sys/socket.h >
#include < poll.h >
#include < sys/epoll.h >
#include < sys/time.h >
#include < netinet/in.h >
#include < unistd.h >
#define MYPORT 12345
//最多处理的connect
#define MAX_EVENTS 500
//当前的连接数
int currentClient = 0;
//数据接受 buf
#define REVLEN 10
char recvBuf[REVLEN];
//epoll描述符
int epollfd;
//事件数组
struct epoll_event eventList[MAX_EVENTS];
void AcceptConn(int srvfd);
void RecvData(int fd);
int main()
{
int i, ret, sinSize;
int recvLen = 0;
fd_set readfds, writefds;
int sockListen, sockSvr, sockMax;
int timeout;
struct sockaddr_in server_addr;
struct sockaddr_in client_addr;
//socket
if((sockListen=socket(AF_INET, SOCK_STREAM, 0)) < 0)
{
printf("socket errorn");
return -1;
}
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(MYPORT);
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
//bind
if(bind(sockListen, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0)
{
printf("bind errorn");
return -1;
}
//listen
if(listen(sockListen, 5) < 0)
{
printf("listen errorn");
return -1;
}
// epoll 初始化
epollfd = epoll_create(MAX_EVENTS);
struct epoll_event event;
event.events = EPOLLIN|EPOLLET;
event.data.fd = sockListen;
//add Event
if(epoll_ctl(epollfd, EPOLL_CTL_ADD, sockListen, &event) < 0)
{
printf("epoll add fail : fd = %dn", sockListen);
return -1;
}
//epoll
while(1)
{
timeout=3000;
//epoll_wait
int ret = epoll_wait(epollfd, eventList, MAX_EVENTS, timeout);
if(ret < 0)
{
printf("epoll errorn");
break;
}
else if(ret == 0)
{
printf("timeout ...n");
continue;
}
//直接获取了事件数量,给出了活动的流,这里是和poll区别的关键
int i = 0;
for(i=0; i< ret; i++)
{
//错误退出
if ((eventList[i].events & EPOLLERR) ||
(eventList[i].events & EPOLLHUP) ||
!(eventList[i].events & EPOLLIN))
{
printf ( "epoll errorn");
close (eventList[i].data.fd);
return -1;
}
if (eventList[i].data.fd == sockListen)
{
AcceptConn(sockListen);
}else{
RecvData(eventList[i].data.fd);
}
}
}
close(epollfd);
close(sockListen);
return 0;
}
/**************************************************
函数名:AcceptConn
功能:接受客户端的链接
参数:srvfd:监听SOCKET
***************************************************/
void AcceptConn(int srvfd)
{
struct sockaddr_in sin;
socklen_t len = sizeof(struct sockaddr_in);
bzero(&sin, len);
int confd = accept(srvfd, (struct sockaddr*)&sin, &len);
if (confd < 0)
{
printf("bad acceptn");
return;
}else
{
printf("Accept Connection: %d", confd);
}
//将新建立的连接添加到EPOLL的监听中
struct epoll_event event;
event.data.fd = confd;
event.events = EPOLLIN|EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, confd, &event);
}
//读取数据
void RecvData(int fd)
{
int ret;
int recvLen = 0;
memset(recvBuf, 0, REVLEN);
printf("RecvData functionn");
if(recvLen != REVLEN)
{
while(1)
{
//recv数据
ret = recv(fd, (char *)recvBuf+recvLen, REVLEN-recvLen, 0);
if(ret == 0)
{
recvLen = 0;
break;
}
else if(ret < 0)
{
recvLen = 0;
break;
}
//数据接受正常
recvLen = recvLen+ret;
if(recvLen< REVLEN)
{
continue;
}
else
{
//数据接受完毕
printf("buf = %sn", recvBuf);
recvLen = 0;
break;
}
}
}
printf("data is %s", recvBuf);
}
整体拔高:高效的并发方式
并发编程的目的是让程序”同时”执行多个任务。如果程序是计算密集型的,并发编程并没有什么优势,反而由于任务的切换使效率降低。但如果程序是I/O密集型的,那就不同了。
并发模式是指I/O处理单元和多个逻辑单元之间协调完成任务的方法,服务器主要有两种并发编程模式:半同步/半异步(half-sync/half-async)模式和领导者/追随者(Leader/Followers)模式。
这里讲一个“半同步/半异步”。
下面的内容需要有一定的基础了,小白可以收藏一下以后变强了再看。
半同步/半异步模式
在半同步/半异步模式中,同步线程用于处理客户逻辑,异步线程用于处理I/O事件。异步线程监听到客户请求之后就将其封装成请求对象并插入到请求队列中。请求队列将通知某个工作在同步模式的工作线程来读取并处理该请求对象。

半同步/半反应堆模式(half-sync/half-reactive模式)
半同步/半反应堆模式是半同步/半异步模式的一种变体。 其结构如下图:

在上图中,异步线程只有一个,由主线程充当,负责监听socket上的事件。如果监听socket上有新的连接请求到来,主线程就接受新的连接socket,然后往epoll内核事件表中注册该socket上的读写事件。如果连接socket上有读写事件发生,即有新的客户请求到来或有数据要发送至客户端,主线程就将该连接socket插入到请求队列中,所有工作线程都睡眠在请求队列上,当有任务到来时,他们通过竞争来获取任务的接管权。 由于主线程插入请求队列中的任务是就绪的连接socket,所以该半同步/半反应堆模式所采用的事件处理模式是Reactor模式,即工作线程要自己从socket上读写数据。当然,半同步/半反应堆模式也可以用模拟的Proactor事件处理模式,即由主线程来完成数据的读写操作,此时主线程将应用程序数据、任务类型等信息封装为一个任务对象,然后将其插入到请求队列。
半同步/半反应堆模式的缺点: 主线程和工作线程共享请求队列,因而请求队列是临界资源,所以对请求队列操作的时候需要加锁保护。 每个工作线程在同一时间只能处理一个客户请求。如果客户数量增多,则请求队列中堆积任务太多,客户端的响应会越来越慢。如果增多工作线程的话,则线程的切花也将消耗大量的CPU时间。
高效的半同步/半异步模式
在半同步/半反应堆模式中,每个工作线程同时只能处理一个客户请求,如果并发量大的话,客户端响应会很慢。如果每个工作线程都能同时处理多个客户链接,则就能改善这种情况,所以就有了高效的半同步/半异步模式。 其结构如图:

主线程只管监听socket,当有新的连接socket到来时,主线程就接受连接并返回新的连接socket给某个工作线程。此后该新连接socket上的任何I/O操作都由被选中的工作线程来处理,直到客户端关闭连接。当工作线程检测到有新的连接socket到来时,就把该新的连接socket的读写事件注册到自己的epoll内核事件表中。 主线程和工作线程都维持自己的事件循环,他们各自独立的监听不同事件。因此在这种高效的半同步/半异步模式中,每个线程都工作在异步模式中,所以它并非严格意义上的半同步/半异步模式。
epoll源码学习
数据结构
eventpoll
// epoll的核心实现对应于一个epoll描述符
struct eventpoll {
spinlock_t lock;
struct mutex mtx;
wait_queue_head_t wq; // sys_epoll_wait() 等待在这里
// f_op- >poll() 使用的, 被其他事件通知机制利用的wait_address
wait_queue_head_t poll_wait;
//已就绪的需要检查的epitem 列表
struct list_head rdllist;
//保存所有加入到当前epoll的文件对应的epitem
struct rb_root rbr;
// 当正在向用户空间复制数据时, 产生的可用文件
struct epitem *ovflist;
/* The user that created the eventpoll descriptor */
struct user_struct *user;
struct file *file;
//优化循环检查,避免循环检查中重复的遍历
int visited;
struct list_head visited_list_link;
}
epitem
// 对应于一个加入到epoll的文件
struct epitem {
// 挂载到eventpoll 的红黑树节点
struct rb_node rbn;
// 挂载到eventpoll.rdllist 的节点
struct list_head rdllink;
// 连接到ovflist 的指针
struct epitem *next;
/* 文件描述符信息fd + file, 红黑树的key */
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
int nwait;
// 当前文件的等待队列(eppoll_entry)列表
// 同一个文件上可能会监视多种事件,
// 这些事件可能属于不同的wait_queue中
// (取决于对应文件类型的实现),
// 所以需要使用链表
struct list_head pwqlist;
// 当前epitem 的所有者
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct list_head fllink;
/* epoll_ctl 传入的用户数据 */
struct epoll_event event;
};
eppoll_entry
// 与一个文件上的一个wait_queue_head 相关联,因为同一文件可能有多个等待的事件,
//这些事件可能使用不同的等待队列
struct eppoll_entry {
// List struct epitem.pwqlist
struct list_head llink;
// 所有者
struct epitem *base;
// 添加到wait_queue 中的节点
wait_queue_t wait;
// 文件wait_queue 头
wait_queue_head_t *whead;
};
函数接口
epoll_create()
//先进行判断size是否 >=0,若是则直接调用epoll_create1
SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
return sys_epoll_create1(0);
}
SYSCALL_DEFINE1是一个宏,用于定义有一个参数的系统调用函数,上述宏展开后即成为: int sys_epoll_create(int size),这就是epoll_create系统调用的入口。至于为何要用宏而不是直接声明,主要是因为系统调用的参数个数、传参方式都有严格限制,最多六个参数。
/* 这才是真正的epoll_create啊~~ */
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
int error;
struct eventpoll *ep = NULL;//主描述符
/* Check the EPOLL_* constant for consistency. */
BUILD_BUG_ON(EPOLL_CLOEXEC != O_CLOEXEC);
/* 对于epoll来讲, 目前唯一有效的flag就是CLOEXEC */
if (flags & ~EPOLL_CLOEXEC)
return -EINVAL;
/*
* Create the internal data structure ("struct eventpoll").
*/
/* 分配一个struct eventpoll */
error = ep_alloc(&ep);
if (error < 0)
return error;
/*
* Creates all the items needed to setup an eventpoll file. That is,
* a file structure and a free file descriptor.
*/
/* 这里是创建一个匿名fd。
epollfd本身并不存在一个真正的文件与之对应, 所以内核需要创建一个
"虚拟"的文件, 并为之分配真正的struct file结构, 而且有真正的fd.
这里2个参数比较关键:
eventpoll_fops, fops就是file operations, 就是当你对这个文件(这里是虚拟的)进行操作(比如读)时,
fops里面的函数指针指向真正的操作实现, 类似C++里面虚函数和子类的概念.
epoll只实现了poll和release(就是close)操作, 其它文件系统操作都有VFS全权处理了.
ep, ep就是struct epollevent, 它会作为一个私有数据保存在struct file的private指针里面.
*/
error = anon_inode_getfd("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
if (error < 0)
ep_free(ep);
return error;
// epoll 文件系统的相关实现
// epoll 文件系统初始化, 在系统启动时会调用
static int __init eventpoll_init(void)
{
struct sysinfo si;
si_meminfo(&si);
// 限制可添加到epoll的最多的描述符数量
max_user_watches = (((si.totalram - si.totalhigh) / 25) < < PAGE_SHIFT) /
EP_ITEM_COST;
BUG_ON(max_user_watches < 0);
// 初始化递归检查队列
ep_nested_calls_init(&poll_loop_ncalls);
ep_nested_calls_init(&poll_safewake_ncalls);
ep_nested_calls_init(&poll_readywalk_ncalls);
// epoll 使用的slab分配器分别用来分配epitem和eppoll_entry
epi_cache = kmem_cache_create("eventpoll_epi", sizeof(struct epitem),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC, NULL);
pwq_cache = kmem_cache_create("eventpoll_pwq",
sizeof(struct eppoll_entry), 0, SLAB_PANIC, NULL);
return 0;
}
epoll_ctl()
//创建好epollfd后, 接下来添加fd
//epoll_ctl的参数:epfd 表示epollfd;op 有ADD,MOD,DEL,
//fd 是需要监听的描述符,event 我们感兴趣的events
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int error;
int did_lock_epmutex = 0;
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
error = -EFAULT;
//错误处理以及从用户空间将epoll_event结构copy到内核空间.
if (ep_op_has_event(op) &&
// 复制用户空间数据到内核
copy_from_user(&epds, event, sizeof(struct epoll_event))) {
goto error_return;
}
// 取得 epfd 对应的文件
error = -EBADF;
file = fget(epfd);
if (!file) {
goto error_return;
}
// 取得目标文件
tfile = fget(fd);
if (!tfile) {
goto error_fput;
}
// 目标文件必须提供 poll 操作
error = -EPERM;
if (!tfile- >f_op || !tfile- >f_op- >poll) {
goto error_tgt_fput;
}
// 添加自身或epfd 不是epoll 句柄
error = -EINVAL;
if (file == tfile || !is_file_epoll(file)) {
goto error_tgt_fput;
}
// 取得内部结构eventpoll
ep = file- >private_data;
// EPOLL_CTL_MOD 不需要加全局锁 epmutex
if (op == EPOLL_CTL_ADD || op == EPOLL_CTL_DEL) {
mutex_lock(&epmutex);
did_lock_epmutex = 1;
}
if (op == EPOLL_CTL_ADD) {
if (is_file_epoll(tfile)) {
error = -ELOOP;
// 目标文件也是epoll 检测是否有循环包含的问题
if (ep_loop_check(ep, tfile) != 0) {
goto error_tgt_fput;
}
} else
{
// 将目标文件添加到 epoll 全局的tfile_check_list 中
list_add(&tfile- >f_tfile_llink, &tfile_check_list);
}
}
mutex_lock_nested(&ep- >mtx, 0);
// 以tfile 和fd 为key 在rbtree 中查找文件对应的epitem
epi = ep_find(ep, tfile, fd);
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
// 没找到, 添加额外添加ERR HUP 事件
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else {
error = -EEXIST;
}
// 清空文件检查列表
clear_tfile_check_list();
break;
case EPOLL_CTL_DEL:
if (epi) {
error = ep_remove(ep, epi);
} else {
error = -ENOENT;
}
break;
case EPOLL_CTL_MOD:
if (epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_modify(ep, epi, &epds);
} else {
error = -ENOENT;
}
break;
}
mutex_unlock(&ep- >mtx);
error_tgt_fput:
if (did_lock_epmutex) {
mutex_unlock(&epmutex);
}
fput(tfile);
error_fput:
fput(file);
error_return:
return error;
}
//ep_insert()在epoll_ctl()中被调用, 完成往epollfd里面添加一个监听fd的工作
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
int error, revents, pwake = 0;
unsigned long flags;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
/*
struct ep_pqueue {
poll_table pt;
struct epitem *epi;
};
*/
// 增加监视文件数
user_watches = atomic_long_read(&ep- >user- >epoll_watches);
if (unlikely(user_watches >= max_user_watches)) {
return -ENOSPC;
}
// 分配初始化 epi
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL))) {
return -ENOMEM;
}
INIT_LIST_HEAD(&epi- >rdllink);
INIT_LIST_HEAD(&epi- >fllink);
INIT_LIST_HEAD(&epi- >pwqlist);
epi- >ep = ep;
// 初始化红黑树中的key
ep_set_ffd(&epi- >ffd, tfile, fd);
// 直接复制用户结构
epi- >event = *event;
epi- >nwait = 0;
epi- >next = EP_UNACTIVE_PTR;
// 初始化临时的 epq
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
// 设置事件掩码
epq.pt._key = event- >events;
// 内部会调用ep_ptable_queue_proc, 在文件对应的wait queue head 上
// 注册回调函数, 并返回当前文件的状态
revents = tfile- >f_op- >poll(tfile, &epq.pt);
// 检查错误
error = -ENOMEM;
if (epi- >nwait < 0) { // f_op- >poll 过程出错
goto error_unregister;
}
// 添加当前的epitem 到文件的f_ep_links 链表
spin_lock(&tfile- >f_lock);
list_add_tail(&epi- >fllink, &tfile- >f_ep_links);
spin_unlock(&tfile- >f_lock);
// 插入epi 到rbtree
ep_rbtree_insert(ep, epi);
/* now check if we've created too many backpaths */
error = -EINVAL;
if (reverse_path_check()) {
goto error_remove_epi;
}
spin_lock_irqsave(&ep- >lock, flags);
/* 文件已经就绪插入到就绪链表rdllist */
if ((revents & event- >events) && !ep_is_linked(&epi- >rdllink)) {
list_add_tail(&epi- >rdllink, &ep- >rdllist);
if (waitqueue_active(&ep- >wq))
// 通知sys_epoll_wait , 调用回调函数唤醒sys_epoll_wait 进程
{
wake_up_locked(&ep- >wq);
}
// 先不通知调用eventpoll_poll 的进程
if (waitqueue_active(&ep- >poll_wait)) {
pwake++;
}
}
spin_unlock_irqrestore(&ep- >lock, flags);
atomic_long_inc(&ep- >user- >epoll_watches);
if (pwake)
// 安全通知调用eventpoll_poll 的进程
{
ep_poll_safewake(&ep- >poll_wait);
}
return 0;
error_remove_epi:
spin_lock(&tfile- >f_lock);
// 删除文件上的 epi
if (ep_is_linked(&epi- >fllink)) {
list_del_init(&epi- >fllink);
}
spin_unlock(&tfile- >f_lock);
// 从红黑树中删除
rb_erase(&epi- >rbn, &ep- >rbr);
error_unregister:
// 从文件的wait_queue 中删除, 释放epitem 关联的所有eppoll_entry
ep_unregister_pollwait(ep, epi);
spin_lock_irqsave(&ep- >lock, flags);
if (ep_is_linked(&epi- >rdllink)) {
list_del_init(&epi- >rdllink);
}
spin_unlock_irqrestore(&ep- >lock, flags);
// 释放epi
kmem_cache_free(epi_cache, epi);
return error;
}
static unsigned int ep_eventpoll_poll(struct file *file, poll_table *wait)
{
int pollflags;
struct eventpoll *ep = file- >private_data;
// 插入到wait_queue
poll_wait(file, &ep- >poll_wait, wait);
// 扫描就绪的文件列表, 调用每个文件上的poll 检测是否真的就绪,
// 然后复制到用户空间
// 文件列表中有可能有epoll文件, 调用poll的时候有可能会产生递归,
// 调用所以用ep_call_nested 包装一下, 防止死循环和过深的调用
pollflags = ep_call_nested(&poll_readywalk_ncalls, EP_MAX_NESTS,
ep_poll_readyevents_proc, ep, ep, current);
// static struct nested_calls poll_readywalk_ncalls;
return pollflags != -1 ? pollflags : 0;
}
// 通用的poll_wait 函数, 文件的f_ops- >poll 通常会调用此函数
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p- >_qproc && wait_address) {
// 调用_qproc 在wait_address 上添加节点和回调函数
// 调用 poll_table_struct 上的函数指针向wait_address添加节点, 并设置节点的func
// (如果是select或poll 则是 __pollwait, 如果是 epoll 则是 ep_ptable_queue_proc),
p- >_qproc(filp, wait_address, p);
}
}
/*
* 该函数在调用f_op- >poll()时会被调用.
* 也就是epoll主动poll某个fd时, 用来将epitem与指定的fd关联起来的.
* 关联的办法就是使用等待队列(waitqueue)
*/
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi- >nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
/* 初始化等待队列, 指定ep_poll_callback为唤醒时的回调函数,
* 当我们监听的fd发生状态改变时, 也就是队列头被唤醒时,
* 指定的回调函数将会被调用. */
init_waitqueue_func_entry(&pwq- >wait, ep_poll_callback);
pwq- >whead = whead;
pwq- >base = epi;
/* 将刚分配的等待队列成员加入到头中, 头是由fd持有的 */
add_wait_queue(whead, &pwq- >wait);
list_add_tail(&pwq- >llink, &epi- >pwqlist);
/* nwait记录了当前epitem加入到了多少个等待队列中,
* 我认为这个值最大也只会是1... */
epi- >nwait++;
} else {
/* We have to signal that an error occurred */
epi- >nwait = -1;
}
}
//回调函数, 当我们监听的fd发生状态改变时, 它会被调用.
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
//从等待队列获取epitem.需要知道哪个进程挂载到这个设备
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi- >ep;//获取
spin_lock_irqsave(&ep- >lock, flags);
if (!(epi- >event.events & ~EP_PRIVATE_BITS))
goto out_unlock;
/* 没有我们关心的event... */
if (key && !((unsigned long) key & epi- >event.events))
goto out_unlock;
/*
* 这里看起来可能有点费解, 其实干的事情比较简单:
* 如果该callback被调用的同时, epoll_wait()已经返回了,
* 也就是说, 此刻应用程序有可能已经在循环获取events,
* 这种情况下, 内核将此刻发生event的epitem用一个单独的链表
* 链起来, 不发给应用程序, 也不丢弃, 而是在下一次epoll_wait
* 时返回给用户.
*/
if (unlikely(ep- >ovflist != EP_UNACTIVE_PTR)) {
if (epi- >next == EP_UNACTIVE_PTR) {
epi- >next = ep- >ovflist;
ep- >ovflist = epi;
}
goto out_unlock;
}
/* 将当前的epitem放入ready list */
if (!ep_is_linked(&epi- >rdllink))
list_add_tail(&epi- >rdllink, &ep- >rdllist);
/* 唤醒epoll_wait... */
if (waitqueue_active(&ep- >wq))
wake_up_locked(&ep- >wq);
/* 如果epollfd也在被poll, 那就唤醒队列里面的所有成员. */
if (waitqueue_active(&ep- >poll_wait))
pwake++;
out_unlock:
spin_unlock_irqrestore(&ep- >lock, flags);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep- >poll_wait);
return 1;
}
epoll_wait()
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
int error;
struct file *file;
struct eventpoll *ep;
/* The maximum number of event must be greater than zero */
if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)
return -EINVAL;
/* Verify that the area passed by the user is writeable */
/* 这个地方有必要说明一下:
* 内核对应用程序采取的策略是"绝对不信任",
* 所以内核跟应用程序之间的数据交互大都是copy, 不允许(也时候也是不能...)指针引用.
* epoll_wait()需要内核返回数据给用户空间, 内存由用户程序提供,
* 所以内核会用一些手段来验证这一段内存空间是不是有效的.
*/
if (!access_ok(VERIFY_WRITE, events, maxevents * sizeof(struct epoll_event))) {
error = -EFAULT;
goto error_return;
}
/* Get the "struct file *" for the eventpoll file */
error = -EBADF;
/* 获取epollfd的struct file, epollfd也是文件嘛 */
file = fget(epfd);
if (!file)
goto error_return;
error = -EINVAL;
/* 检查一下它是不是一个真正的epollfd... */
if (!is_file_epoll(file))
goto error_fput;
/* 获取eventpoll结构 */
ep = file- >private_data;
/* 等待事件到来~~ */
error = ep_poll(ep, events, maxevents, timeout);
error_fput:
fput(file);
error_return:
return error;
}
/* 这个函数真正将执行epoll_wait的进程带入睡眠状态... */
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res, eavail;
unsigned long flags;
long jtimeout;
wait_queue_t wait;//等待队列
/* 计算睡觉时间, 毫秒要转换为HZ */
jtimeout = (timeout < 0 || timeout >= EP_MAX_MSTIMEO) ?
MAX_SCHEDULE_TIMEOUT : (timeout * HZ + 999) / 1000;
retry:
spin_lock_irqsave(&ep- >lock, flags);
res = 0;
/* 如果ready list不为空, 就不睡了, 直接干活... */
if (list_empty(&ep- >rdllist)) {
/* OK, 初始化一个等待队列, 准备直接把自己挂起,
* 注意current是一个宏, 代表当前进程 */
init_waitqueue_entry(&wait, current);//初始化等待队列,wait表示当前进程
__add_wait_queue_exclusive(&ep- >wq, &wait);//挂载到ep结构的等待队列
for (;;) {
/* 将当前进程设置位睡眠, 但是可以被信号唤醒的状态,
* 注意这个设置是"将来时", 我们此刻还没睡! */
set_current_state(TASK_INTERRUPTIBLE);
/* 如果这个时候, ready list里面有成员了,
* 或者睡眠时间已经过了, 就直接不睡了... */
if (!list_empty(&ep- >rdllist) || !jtimeout)
break;
/* 如果有信号产生, 也起床... */
if (signal_pending(current)) {
res = -EINTR;
break;
}
/* 啥事都没有,解锁, 睡觉... */
spin_unlock_irqrestore(&ep- >lock, flags);
/* jtimeout这个时间后, 会被唤醒,
* ep_poll_callback()如果此时被调用,
* 那么我们就会直接被唤醒, 不用等时间了...
* 再次强调一下ep_poll_callback()的调用时机是由被监听的fd
* 的具体实现, 比如socket或者某个设备驱动来决定的,
* 因为等待队列头是他们持有的, epoll和当前进程
* 只是单纯的等待...
**/
jtimeout = schedule_timeout(jtimeout);//睡觉
spin_lock_irqsave(&ep- >lock, flags);
}
__remove_wait_queue(&ep- >wq, &wait);
/* OK 我们醒来了... */
set_current_state(TASK_RUNNING);
}
/* Is it worth to try to dig for events ? */
eavail = !list_empty(&ep- >rdllist) || ep- >ovflist != EP_UNACTIVE_PTR;
spin_unlock_irqrestore(&ep- >lock, flags);
/* 如果一切正常, 有event发生, 就开始准备数据copy给用户空间了... */
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && jtimeout)
goto retry;
return res;
}
//调用p_scan_ready_list()
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
struct ep_send_events_data esed;
esed.maxevents = maxevents;
esed.events = events;
return ep_scan_ready_list(ep, ep_send_events_proc, &esed);
}
//由ep_send_events()调用本函数
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv)
{
int error, pwake = 0;
unsigned long flags;
struct epitem *epi, *nepi;
LIST_HEAD(txlist);
mutex_lock(&ep- >mtx);
spin_lock_irqsave(&ep- >lock, flags);
/* 这一步要注意, 首先, 所有监听到events的epitem都链到rdllist上了,
* 但是这一步之后, 所有的epitem都转移到了txlist上, 而rdllist被清空了,
* 要注意哦, rdllist已经被清空了! */
list_splice_init(&ep- >rdllist, &txlist);
/* ovflist, 在ep_poll_callback()里面我解释过, 此时此刻我们不希望
* 有新的event加入到ready list中了, 保存后下次再处理... */
ep- >ovflist = NULL;
spin_unlock_irqrestore(&ep- >lock, flags);
/* 在这个回调函数里面处理每个epitem
* sproc 就是 ep_send_events_proc, 下面会注释到. */
error = (*sproc)(ep, &txlist, priv);
spin_lock_irqsave(&ep- >lock, flags);
/* 现在我们来处理ovflist, 这些epitem都是我们在传递数据给用户空间时
* 监听到了事件. */
for (nepi = ep- >ovflist; (epi = nepi) != NULL;
nepi = epi- >next, epi- >next = EP_UNACTIVE_PTR) {
/* 将这些直接放入readylist */
if (!ep_is_linked(&epi- >rdllink))
list_add_tail(&epi- >rdllink, &ep- >rdllist);
}
ep- >ovflist = EP_UNACTIVE_PTR;
/* 上一次没有处理完的epitem, 重新插入到ready list */
list_splice(&txlist, &ep- >rdllist);
/* ready list不为空, 直接唤醒... */
if (!list_empty(&ep- >rdllist)) {
if (waitqueue_active(&ep- >wq))
wake_up_locked(&ep- >wq);
if (waitqueue_active(&ep- >poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep- >lock, flags);
mutex_unlock(&ep- >mtx);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep- >poll_wait);
return error;
}
-
epoll源码分析2023-11-13 2213
-
epoll的基础数据结构2023-11-10 1864
-
用epoll来实现多路复用2023-11-09 1351
-
介绍reactor的四种模型2023-11-08 3746
-
揭示EPOLL一些原理性的东西2022-08-24 1481
-
一文详解epoll的实现原理2022-08-01 5005
-
epoll_wait的事件返回的fd为错误是怎么回事?2020-06-12 3110
-
epoll使用方法与poll的区别2019-07-31 2373
-
Linux中epoll IO多路复用机制2019-05-16 1000
-
poll&&epoll之epoll实现2019-05-14 3281
-
关于Epoll,你应该知道的那些细节2019-05-12 1619
-
我读过的最好的epoll讲解2018-05-12 9196
-
epoll的使用2018-05-11 2914
全部0条评论

快来发表一下你的评论吧 !
