

浅谈AI模型在漂移检测中的应用
描述
人工智能应用的开发过程中,AI 模型的泛化能力是一个非常重要的考量因素,理想情况下,基于训练数据集优化得到的 AI 模型,不存在过拟合或欠拟合问题,可以直接迁移到新数据上用于推断。
在这种设定下,训练数据集是从未知分布 P 中独立同分布生成,且数据集是静态、均衡且无偏的,1. 训练数据集中的样本能够全面描述目标总体的底层特征,2. 数据总体的统计分布不会随时间和外部环境因素改变。实际上,真实应用场景无法满足这种理想假设,所以,在生产或运营环境中,如果 AI 模型的输入数据和训练集来自不同统计分布时,模型的性能将无法达到预期,甚至输出不可靠的预测结果。
因此,在实际应用中,可能出现以下两种场景:
1.持续监控并维护 AI 模型,例如,定期使用新数据更新模型,必要时重新选择特征输入或更改模型以保证预测能力;
2.维持原 AI 模型,在出现置信度不够高的预测结果时,例如,针对未知类别的样本,或异常值进行预测时,驳回模型推断结果并预警。
本文将围绕第一种场景,展开介绍如何结合数据开展漂移检测,以判定合适的时机对模型进行更新。
引例:车载动力电池的健康状态估计
举个简单的例子,针对电动汽车电池的容量衰退问题,开发健康状态估计算法。在驾驶条件下无法直接测量电池容量,基于历史或实验数据,构建 AI 模型作为估计容量衰退趋势,以缓解里程焦虑。
在训练 AI 模型用于健康状态(SoH)估计时,模型的输入包括电压、电流、电池荷电状态 (SoC) 等信息,其中 SoC 这一状态量,会受到外部环境温度影响,而温度波动的统计分布又随时间或空间而变化,从而间接影响到 SoH 估计的结果,这种现象称为漂移,当训练数据无法覆盖到实际应用中某些工况的温度范围,实际预测过程中采集的数据偏离原训练数据的统计分布,将导致模型预测准确度下降。
因此,在生产环境中部署 AI 模型的同时,引入漂移检测,监控流数据是否发生漂移,以确定是否需要基于最近采集的数据执行再训练(如下图黄色箭头所示)。
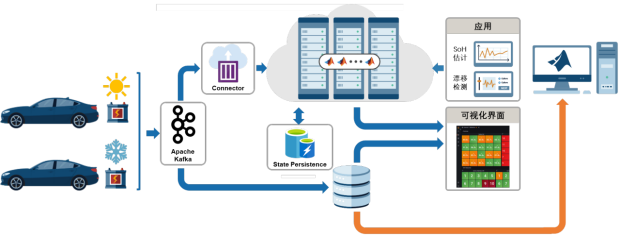
“数据漂移” 和 “概念漂移”
在监控机器学习模型的性能,判断是否需要对模型进行维护时,存在两种可能的情况:
数据漂移:如果模型推断时,输入的数据和训练数据存在明显差异,模型性能无法达到预期,这种情况下,需要结合新数据,对模型进行再训练,调整可学习参数。
概念漂移:当模型学习的概念依赖于某些未被考虑到特征/变量时,例如,利用模型预测交通堵塞情况,但没有考虑到与节假日相关的特征,或是当输入特征和模型预测的目标概念之间,底层关系发生变化时,这种情况下,需要评估是否需要更换模型,而不仅仅是重训练原模型。
MATLAB 的 Statistics and Machine Learning Toolbox,可支持:
1.根据批量数据检测数据漂移:调用 detectdrift 函数,通过置换检验判断目标数据集相对于基准数据集是否存在漂移。
2.根据流式数据检测概念漂移:构建 incrementalConceptDriftDetector 对象,指定使用 DDM,HDDMW 或 HDDMA 算法,根据实时输入的数据流,调用 detectdrift 函数评估是否发生概念漂移。
本文将以电池 SoH 估计所使用的数据集为例,介绍基于批量数据的数据漂移检测,并简要说明如何开展流式数据的概念漂移检测。
电池健康监控系统中的漂移检测
数据准备
在分析工程大数据时,一个常见的问题是,如何高效管理多个不同试验、工况、日期的多通道测量数据,Predictive Maintenance Toolbox 提供了一个专用的对象 fileEnsembleDatastore 用于创建关于本地或远程数据集的索引,并根据自定义读取函数 ReadFcn,对数据集进行增量式或批量式访问。按照数据集中的不同变量类型,将不同变量分别定义为:数据变量(测量量)、独立变量(时间戳、文件名等)或状态变量(标签信息)。并通过 SelectedVariables 属性,指定每次访问数据集需要读取的部分变量。此外,经过特征提取后的数据可通过自定义 WriteToMemberFcn 函数,再次写回到 fileEnsembleDatastore 便于集中管理。关于如何使用 fileEnsembleDatastore,可查看文档链接:File Ensemble Datastore with Measured Data[1]。
sample = read(fensemble);
time = sample.("Current"){:}.Time;
current = sample.("Current"){:}.Var1;
voltage = sample.("Voltage"){:}.Var1;
SoC = sample.("SoC_B1"){:}.Var1;
SoH = sample.("SoH"){:}.Var1;
tt = timetable(time,current,voltage,SoC,SoH);
figure
stackedplot(tt)
ans = 1×5 table
| Key | Current | Voltage | SoC_B1 | ⋯ | |
| 1 |
360001×1 timetable |
360001×1 timetable |
360001×1 timetable |
⋯ |
完整文件集一共由20组电池数据组成,其中 key 代表各个文件的编号。
fileEnsembleDatastore 支持通过 read 或 readall 方法,将数据读取到内存。接下来,我们尝试选取一组数据查看各个状态量的时间序列:
prj = currentProject; location = fullfile(prj.RootFolder,"TrainingData","battery*.mat"); extension = '.mat'; fensemble = fileEnsembleDatastore(location,extension); fensemble.ReadFcn = @readBatteryData; fensemble.DataVariables = ["Current","Voltage","SoC_B1","SoH"]; fensemble.SelectedVariables = ["Current","Voltage","SoC_B1","SoH"]; preview(fensemble)
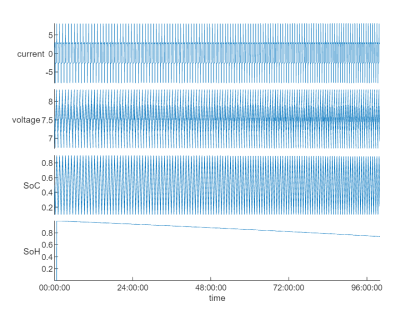
特征提取
从上图信号波形构建 AI 模型进行预测或是判断是否存在漂移,是非常困难的,因此,针对特征工程往往是必要的。利用 Diagnostic Feature Designer App 可通过交互式方式,对时间序列数据进行可视化探查,并提取统计或时频域特征,并导出函数用于后续处理。了解更多可参考:Explore Ensemble Data and Compare Features Using Diagnostic Feature Designer[2]。使用预先导出的 diagnosticFeatures_Historical 函数,从基准数据集中提取各种统计特征得到特征表:
batteryData = readall(fensemble); % 通过 readall 函数将所有数据读入内存 baselineData = batteryData(batteryData.key<=10,:); % 将编号前10的文件作为基准数据集 baselineFeatures = diagnosticFeatures_Historical(baselineData); head(baselineFeatures)

size(baselineFeatures)
ans = 1×2
2000 20
特征表维度为 2000x20,通过将原始基准数据分为 2000 个长度分别为 1800s 的时间序列,并提取各个原始物理量的多个统计和频域特征,表格中,前4列记录的是文件编号和起止时间戳信息,在后续处理中,将重点关注第 5 列到最末列(20)的特征数据。
再从完整数据集中,选取部分数据作为目标数据集,并提取特征:
idx = 15; % 范围 11~19 targetData = batteryData(batteryData.key>idx,:); targetFeatures = diagnosticFeatures_Historical(targetData);
对比基准数据集和目标数据集,可视化各个特征的统计分布:
figure
tiledlayout(4,4);
for i = 5:width(baselineFeatures)
nexttile;
histogram(baselineFeatures{:,i},Normalization="pdf");
hold on
histogram(targetFeatures{:,i},Normalization="pdf");
hold off
xlabel(baselineFeatures.Properties.VariableNames{i},Interpreter="none");
end
legend("baseline","target",location="northeastoutside")
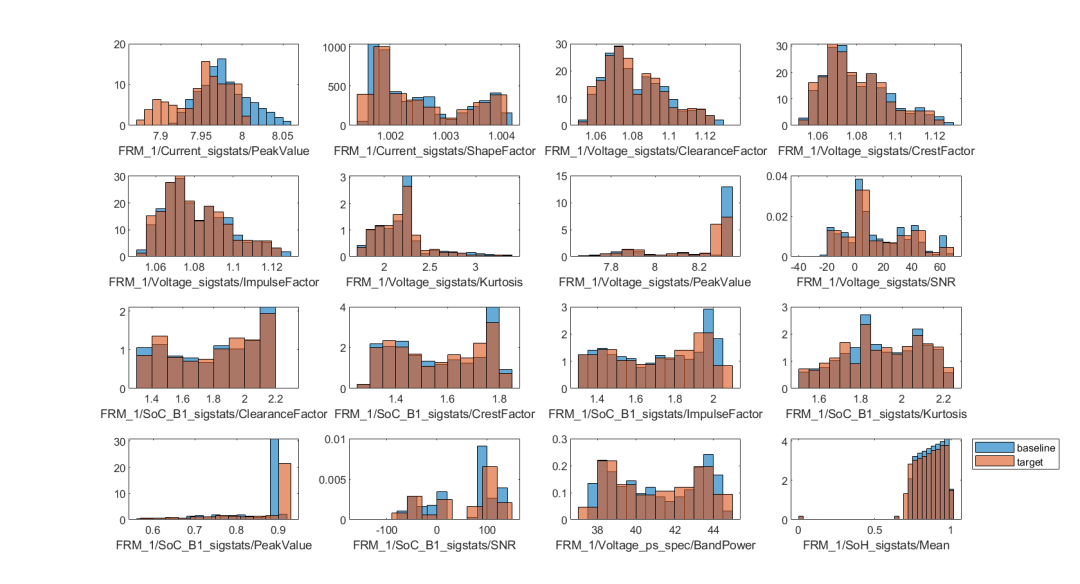
基于批量数据的漂移检测
从上图可以看出,部分特征,例如第一个特征电流峰值,可以从图中看出,蓝色基准数据集的取值范围更大,这一特征的均值略高于红色目标数据集的均值。如何定量或定性地判断模型输入数据/特征是否发生了漂移呢?针对批量数据,detectdrift 采用置换检验这一方法,推断目标数据相较于基准数据,是否发生数据漂移,detectdrift 函数调用方式如下:
DDiagnostics = detectdrift(baselineFeatures(:,5:end),targetFeatures(:,5:end)); % 前4列记录的是文件编号和起止时间戳信息,检测漂移时不需要考虑
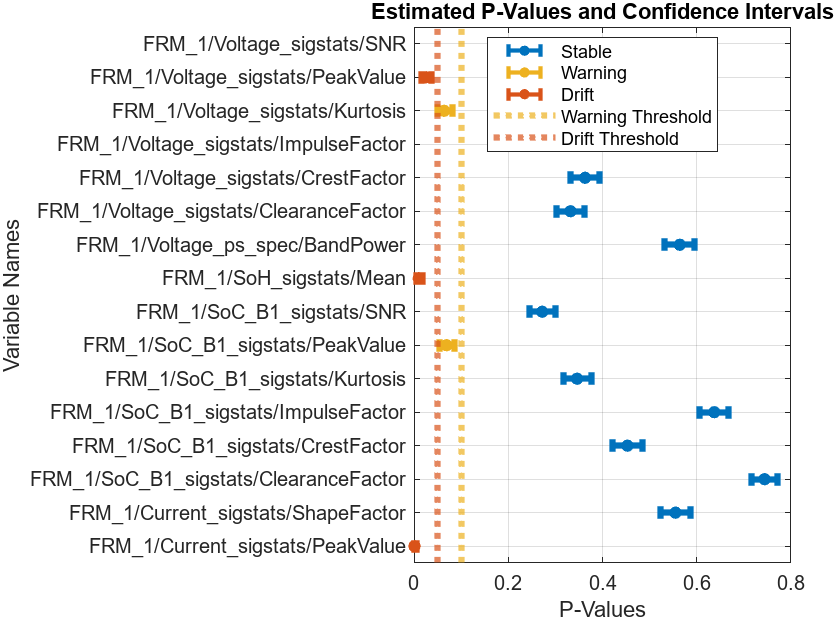
计算结果以 DriftDiagnostics 对象返回,其中记录了上述计算中涉及到的相关属性信息,针对 DriftDiagnostics 对象的方法函数可以帮助我们理解检测结果和推断过程。例如,通过 summary 汇总各个特征的漂移状态、p 值和置信区间:
summary(DDiagnostics)
Multiple Test Correction Drift Status: Drift
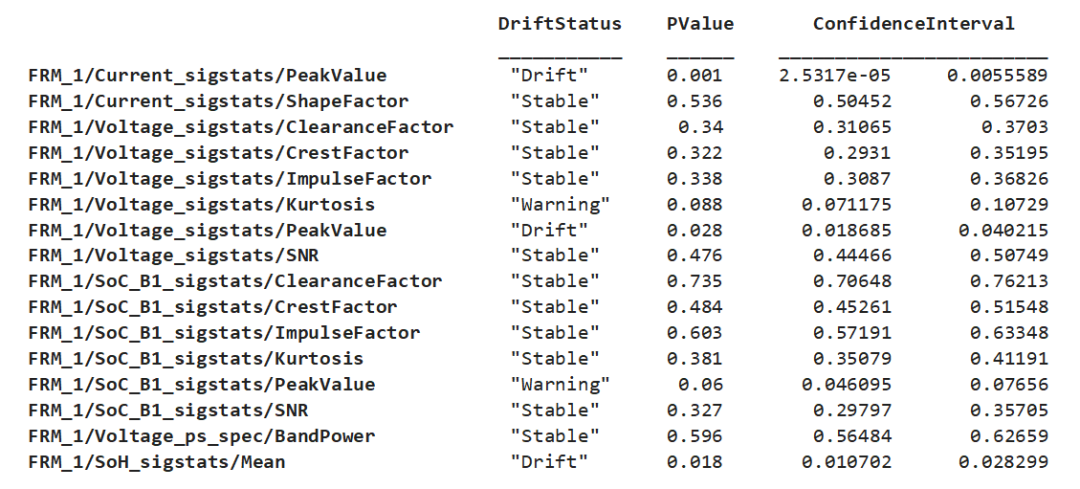
figure; plotDriftStatus(DDiagnostics)
【算法解析】
什么是置换检验?这是一个非参数化统计显著度检验方法,适用于总体分布未知的数据集。实现过程如下:
提出零假设:数据没有发生漂移
选择一个测试统计量,例如基准数据m的个样本均值 μ1 和目标数据 n 个样本均值 μ2 的差值 t0=μ1-μ2,算法提供了 Wasserstein, Kolmogorov-Smirnov 等测试统计量供选择
将两组数据合并,对全部数据样本进行不放回抽样,重新得到两组样本量分别为 m 和 n 的集合,分别计算测试统计量,得到 t1=μ1-μ2
假设零假设成立,重复上述抽样多次,将全部测试统计量 t0,t1,t2,... 排序形成抽样分布,并计算 p 值 p=x/perm,x 为 t1,t2,... 中大于 t0 的次数,perm 为置换的次数
由于在样本数量非常大的情况下,遍历全部可能的组合,将限制计算速度,因此,算法将尽可能多地进行抽样,以估计测试统计量的分布
根据零假设,测试统计量 t1,t2,... ,应该与 t0 接近,当 t0 被判定为区别于 t1,t2,... 的异常值时,驳回零假设,即判断数据发生漂移
在假设 x 符合二项分布的条件下,通过 [~,CI] = binofit(x,perm,0.05) 估计 p 值的 95% 置信区间
detectdrift 函数中,默认条件下,漂移阈值定义为 0.05,警告阈值定义为 0.1,当计算得到的置信区间上限小于漂移阈值时,判定漂移状态出现
反之,当置信区间下限大于警告阈值时,判定状态稳定,介于二者之间,则发出警告
结果分析
为了方便理解,我们可以使用 DriftDiagnostics 的方法函数 plotPermutationResults ,可视化指定特征的置换检验结果:
figure tiledlayout(3,1) nexttile % stable plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(5)) nexttile % warning plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(6)) nexttile % drift plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(7))
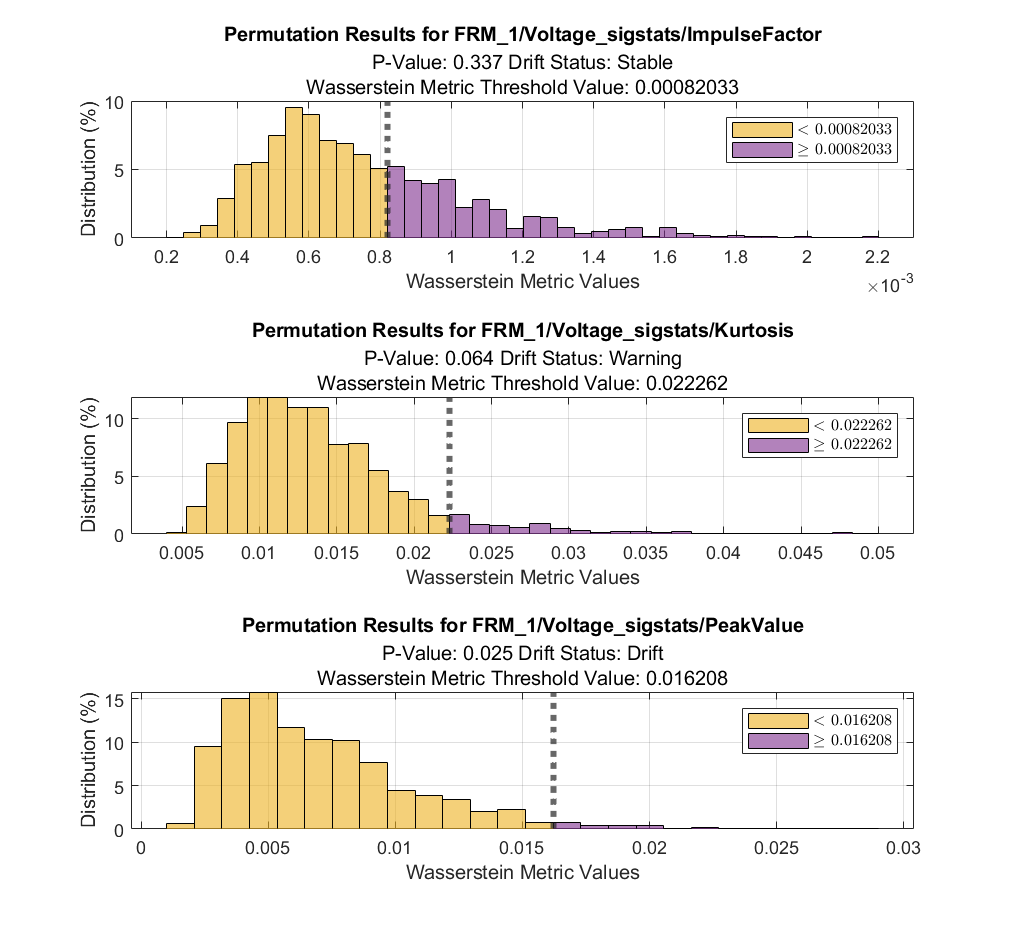
其中,灰色虚线代表使用原有的基准数据集和目标数据集计算得到的测试统计量,即,作为阈值,将置换组合后的测试统计量所形成抽样分布划分为两部分,p 值代表大于阈值的部分占比。由以上直方图,可以清晰看到原始测试统计量在置换组合的测试统计量抽样分布中的位置。另外结合二项分布假设计算得到的置信区间,可以判定是否发生漂移。此外,plotHistogram,plotEmpiricalCDF 函数也可用于可视化辅助分析。
问题延申:基于流式数据的概念漂移检测
如引例图示,在实际生产环境中,通常需要采集流式数据,如何根据有限且分布未知的数据,监控数据或概念本身是否存在漂移,并对AI模型进行维护呢?一方面,可以结合增量学习方法,根据模型准确度在一定时间窗口内准确度的平均值和累积值,作为是否存在漂移问题的判定标准。另一方面,可以使用 incrementalConceptDriftDetector 对象定义漂移检测模型,然后根据实时数据流更新检测模型,并调用 detectdrift 函数检测漂移。此外,如果将构建机器学习模型的过程和漂移检测合二为一,可以通过 incrementalDriftAwareLearner 创建可感知概念漂移的分类或回归模型,根据输入数据和漂移状态的变化,自动调整模型参数。
以下简要介绍第三种方式的实现步骤:
1.初始化基础增量学习模型,例如朴素贝叶斯分类模型:
BaseLearner = incrementalClassificationNaiveBayes(MaxNumClasses=2,Metrics="classiferror");
2.定义概念漂移检测算法,并将基础模型和检测器作为参数,创建可感知漂移的增量学习模型:
dd = incrementalConceptDriftDetector("hddma");
idaMdl = incrementalDriftAwareLearner(BaseLearner,DriftDetector=dd,TrainingPeriod=5000);
3.根据输入数据流 (XNew,YNew),先评估模型当前性能指标(updateMetrics),再调整模型参数:
idaMdl = updateMetricsAndFit(idaMdl,XNew,YNew);
classficationError{j,:} = idal.Metrics{"ClassificationError",:};
4.记录数据用于可视化:
plot(classficationError.Variables)
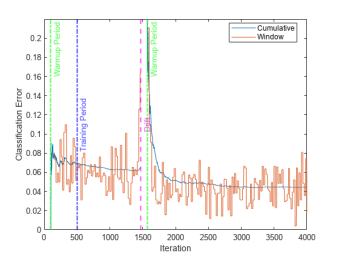
关于上述方法,可查看以下文档链接了解更多:Construct drift-aware model for incremental learning[3]。
AI 模型在生产环境中使用时,需要进行持续性维护,以确保性能,本文介绍了常用的漂移检测方法,在某些场景下,原模型维持不变,在出现推断结果置信度不够高时,例如,出现未知类别的样本时,需要驳回模型推断结果并预警,这类问题一般定义为分布外检测。针对深度学习的分布外检测问题,可安装附加功能包 Deep Learning Toolbox Verification Library[4],并查看相关文档。
-
AI模型的配置AI模型该怎么做?2025-10-14 418
-
在K230中,如何使用AI Demo中的object_detect_yolov8n,YOLOV8多目标检测模型?2025-08-07 514
-
AI模型部署边缘设备的奇妙之旅:目标检测模型2024-12-19 2770
-
AI大模型在自然语言处理中的应用2024-10-23 2874
-
AI模型在MCU中的应用2024-07-12 3077
-
防止AI大模型被黑客病毒入侵控制(原创)聆思大模型AI开发套件评测42024-03-19 2100
-
AI Transformer模型支持机器视觉对象检测方案2023-11-23 1204
-
AI视觉检测在工业领域的应用2023-06-15 4419
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 2857
-
在X-CUBE-AI.7.1.0中导入由在线AI平台生成的.h5模型报错怎么解决?2022-12-27 759
-
介绍在STM32cubeIDE上部署AI模型的系列教程2021-12-14 3385
-
浅谈智能电网在智慧城市中的应用2020-07-16 2100
-
如何去识别和跟踪模型漂移2020-03-20 4200
-
浅谈镍氢电池在电动航模中的应用2009-11-05 2486
全部0条评论

快来发表一下你的评论吧 !
