

聊聊FreeRTOS内存管理方案及相关的优化措施
电子说
描述
FreeRTOS 作为一个嵌入式实时操作系统,其运行的环境一般资源有限,特别是其内存资源,可能只有几 M,甚至是几十 KB。针对不同的应用场景,FreeRTOS 源码中提供了 5 种内存管理方案。本文就来聊聊这些内存管理方案以及相关的优化措施。
内存管理相关的代码在 lib/FreeRTOS/portable/MemMang 目录下,从 heap_1.c 到 heap_5.c,文件相互独立,并提供统一接口:
void *pvPortMalloc( size_t xWantedSize );
void vPortFree( void *pv );
而 heap 的定义,可以是一块静态分配的数组作为 heap,也可以是指定的一块区域作为 heap,本文就以静态数组为例进行讲解。
#if( configAPPLICATION_ALLOCATED_HEAP == 1)
extern uint8_t ucHeap[ configTOTAL_HEAP_SIZE ];
#else
static uint8_t ucHeap[ configTOTAL_HEAP_SIZE ];
#endif
实际上,内存释放接口并不一定都有效,因为 heap_1 方案是不支持内存释放的。在 heap_1 中调用 pvPortMalloc() 的时候,其具体实现如下所示:

pucAligendHeap: 对齐后的 heap 起始地址。
xNextFreeByte: 记录下一次分配内存的偏移值,实际就是已分配内存的总大小。
pvReturn = pucAlignedHeap + xNextFreeByte;
xNextFreeByte += xWantedSize;
每次分配的时候,返回 pucAligendHeap + xNextFreeByte 的地址,然后更新 xNextFreeByte。当然了,整个分配过程中,还有一些对齐操作。由于分配后的内存不能进行释放,所以这种分配方案适用于不需要频繁申请释放内存的场景。
相对于 heap_1 方案,在 heap_2 中增加了内存释放的函数。其实现是在每一次分配的内存中增加了一些描述信息(也就是多分配一个结构体大小的内存,用于保存描述信息),这样在释放的时候,就可以根据这些信息回收内存。
typedef struct A_BLOCK_LINK {
struct A_BLOCK_LINK *pxNextFreeBlock;
size_t xBlockSize;
} BlockLink_t;
static const uint16_t heapSTRUCT_SIZE = (( sizeof( BlockLink_t ) + ( portBYTE_ALIGNMENT - 1 )) & ~portBYTE_ALIGNMENT_MASK );
xWantedSize += heapSTRUCT_SIZE; /*每次分配的时候自动加上描述结构体的大小*/
描述信息结构体中包含了一个链表指针,用于在释放的时候,将该内存加入到空闲链表中,每次分配内存实际就是从空闲链表上进行分配(初始状态,整个链表除了头尾,就一个成员,就是整个空闲的 heap 块)。xBlockSize 用于描述分配内存的大小。

其中,xStart 和 xEnd 是空闲链的头尾节点。初始状态时,整个 heap 就是一个空闲块。分配的时候,从头遍历空闲链,找到第一个满足大小的块,也就是最先匹配原则(first fit),从中分裂出所需的大小,然后将剩余的插入到空闲链中。而释放就是将其插入到空闲链中。
需要注意的是,插入空闲链中,都是升序排列的,也就是说在分配的时候,最先满足的块也是最优的块(best fit),可以减少碎片的产生。从实现来看,heap_2 虽然添加了释放内存函数,但其在插入到空闲链的时候,没有对相邻的块进行合并,所以 heap_2 适用于操作固定大小内存的场景。
heap_3 的方案没有基于 heap_2 进行优化,而是直接使用 libc 库中 malloc() / free() 接口,所以这里就不多做介绍。
事实上,相邻块合并功能是在 heap_4 中引入的。在将空闲块插入到链表的时候,会判断是否有空闲块是相邻的,如果相邻就合并成一个更大的空闲块,就能减少碎片的产生,进而更适用于一般的内存分配和释放场景。注意 heap_4 在插入空闲链的时候,不再是升序排列,而是根据地址大小进行排列,这样便于判断量表中前后两个块是否相邻。
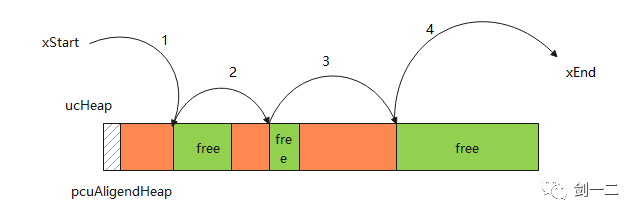
heap_5 相对于 heap_4 方案并没有进行算法上的优化,它添加了一个接口可以指定某个内存块作为 heap。
void vPortDefineHeapRegions( const HeapRegion_t * const pRegions );
在前几种内存管理方案中,除了 heap_3,内存块都是静态分配的。而在 heap_5 中 heap 不再是静态定义的全局变量,而是需要显示指定的一块内存区域作为 heap。这样的好处就是,heap 的来源更加灵活,可以是和运行空间不连续的一块内存,也可以将多个不连续的内存块作为 heap 进行管理。
以上就介绍了 FreeRTOS 中原生的 5 种内存管理方案。可以看出,后面的内存管理方案对前面的管理方案是兼容的,比如 heap_5 可以替代 heap_1, heap_2 和 heap_4 方案。这里可能就有个疑问了,为什么不直接用 heap_5 方案呢?更丰富的功能,意味着复杂的一些实现,在一些简单的场景中,heap_5 分配速度可能没有 heap_1 或者 heap_2 来得快,所以 heap_1,heap_2 等方案也有其存在的意义。
在实际场景中,比如随机的分配和释放,而且分配的大小也不一致,这个时候,一般会选择 heap_4。heap_4 引入了内存合并功能,可以减少内存碎片,但和 heap_2 相比,也把最优匹配的原则去掉了。如下图所示:
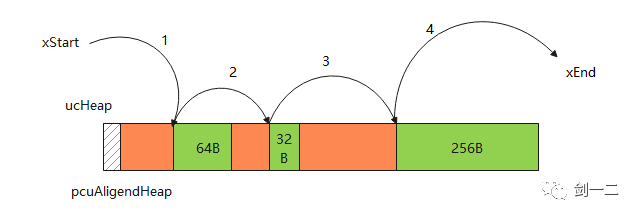
当要分配一个 32Bytes 的内存(经过对齐等处理后的大小),按照 heap_4 的分配方案,最先匹配原则,会从 56Bytes 大小的块中分配一个32Bytes 出去,而不是从第二个空闲块,刚刚好是 32Bytes 的块中分配。这样的分配方法就会产生碎片。碎片多了就会导致空闲内存看似很多,但大的内存块已经没有了。
优化的办法也很简单,就是遍历整个空闲链表,找到最优的一个块,其修改方法就是在原来 first fit 的基础上,遍历剩余的链表:
/* first fit */
while ((pxBlock- >xBlockSize < xWantedSize) && (pxBlock- >pxNextFreeBlock != NULL))
{
pxPreviousBlock = pxBlock;
pxBlock = pxBlock- >pxNextFreeBlock;
}
/* best fit */
BlockLink_t *pxTmp = pxBlock;
BlockLink_t *pxPreTmp = pxPreviousBlock;while (pxTmp != pxEnd){
if ((pxTmp- >xBlockSize >= xWantedSize) && (pxTmp- >xBlockSize < pxBlock- >xBlockSize))
{
pxBlock = pxTmp;
pxPreviousBlock = pxPreTmp;
}
pxPreTmp = pxTmp;
pxTmp = pxTmp- >pxNextFreeBlock;
}
最优匹配的引入,不是一定就比原来的方案效果要好,因为遍历整个空闲链表,会导致分配内存的时间变长。这在某些对实时要求较高的环境中就不适应了,比如在一些网络环境中可能会因为超时而导致功能不正常。
其实分配快,内存碎片少的方法有很多,只是他们的实现成本会有所不同,一个算法不可能适用所有的场景,分配方案中也没有哪个比哪个一定更好,找到适合应用场景的就是好的算法。这也许就是 FreeRTOS 中保留了多种分配方案的原因吧。
-
FreeRTOS内存机制详解2023-12-31 4237
-
FreeRTOS内存管理实现2023-10-10 1796
-
FreeRTOS内存管理简介2023-07-30 1627
-
FreeRTOS的源码下载2023-02-10 8259
-
FreeRTOS高级篇7---FreeRTOS内存管理分析2022-01-26 778
-
什么是内存优化?有那些优化措施?2022-01-14 1638
-
Freertos关于堆内存管理的相关资料分享2021-12-27 1202
-
FreeRTOS内存管理的算法解析?2020-07-30 1219
-
嵌入式操作系统FreeRTOS内存如何管理和堆2020-01-10 6356
-
FreeRTOS代码剖析之1:内存管理Heap2017-02-09 1489
-
第28章 FreeRTOS动态内存管理2016-09-11 11790
-
通信设备中内存管理优化2009-02-21 1043
全部0条评论

快来发表一下你的评论吧 !
