

贝叶斯优化是干什么的(原理解读)
描述
希望这篇文章能够让你无痛理解贝叶斯优化,记得点赞!
贝叶斯优化什么
既然是优化,就有优化命题的存在,比如要在某个区间内去最大化某个函数
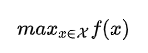
如果这个函数计算比较容易,甚至还可以知道它的梯度,那事情就好办了,一阶、二阶优化算法换着上就完事。
https://zhuanlan.zhihu.com/p/169835477
但现实往往没有那么理想,这个函数的一阶、二阶导数信息我们可能是没有的,甚至计算一次函数的值都很费劲(给定一个x,计算f(x) 的计算量很大。
比如神经网络中的超参数优化),这时候就要求助 gradient-free 的优化算法了,这类算法也很多了,贝叶斯优化就属于无梯度优化算法中的一种,它希望在尽可能少的试验情况下去尽可能获得优化命题的全局最优解。
概述
由于我们要优化的这个函数计算量太大,一个自然的想法就是用一个简单点的模型来近似f(x),这个替代原始函数的模型也叫做代理模型,贝叶斯优化中的代理模型为高斯过程,假设我们对待优化函数的先验(prior)为高斯过程,经过一定的试验我们有了数据(也就是evidence),然后根据贝叶斯定理就可以得到这个函数的后验分布。
有了这个后验分布后,我们需要考虑下一次试验点在哪里进一步收集数据,因此就会需要构造一个acquisition函数用于指导搜索方向(选择下一个试验点),然后再去进行试验,得到数据后更新代理模型的后验分布,反复进行。
综上所述,贝叶斯优化的流程为:

高斯过程
高斯过程是多元高斯分布向无穷维的扩展,如果说高斯分布是随机变量的分布,则高斯过程是函数的分布,它可以由均值函数和协方差函数组成
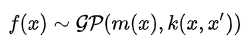

这里的均值和协方差函数的推导和具体形式先省略不管,感兴趣的可以看之前的博文,需要明确的是我们已经可以根据高斯过程的后验分布对这个未知函数在任意位置的值做出预测,均值包括方差。
关于高斯过程的更多可见:
https://zhuanlan.zhihu.com/p/158720213
acquisition函数
Typically, acquisition functions are defined such that high acquisition corresponds to potentially high values of the objective function, whether because the prediction is high, the uncertainty is great, or both.
也就是说贝叶斯优化选择的搜索方向为预测值大的位置或者不确定性大的位置,这样才有可能搜到目标函数的最优解。
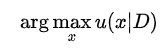
因此贝叶斯优化中很多工作关注点在于acquisition函数的设计:
最大化提升概率
最容易想到的就是我希望下一次试验的结果比当前所有观测结果都要好
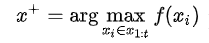
或者说这个新采样的函数值更优的概率要大
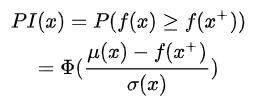
但是光这样考虑是有点目光短浅的,它忽略了对不确定性的考虑,一味追求选择大概率肯定大于f(x)+的点,也就是一直在exploitation,这样的缺点是可能就陷入了局部最优,忽略了潜在的最优解。改进的方法也很简单,加个偏置就可以了
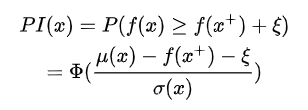

最大化提升量
提升的概率大并不意味着提升得多,一种量化的角度就是考虑提升量(可以不严谨地理解为梯度下降法中,不仅要下降,而且要下得更多一点)
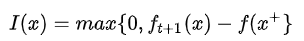
那么要求得下一次试验点就可以最大化期望的提升量
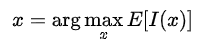
由于代替模型为高斯过程,提升量Ι的似然满足标准正态分布,进一步可以推导(不会推导想了解推导的再留言吧)得到

最大化置信上界
由于我们的代理模型是高斯过程,预测为分布,即有均值也有方差,那么就可以构造一个置信上界
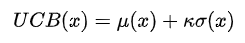
这样的上界同时考虑了预测值的大小以及不确定性,高斯过程在观测数据的位置不确定性(方差)小,在未探索区域的不确定大。
Talk is Cheap
让我们来解读一下源码,一探究竟
首先定义个Bayesian_opt的类,其中的代理模型高斯过程从sklearn拉出来就好了
from sklearn.gaussian_process import GaussianProcessRegressor self.GP = GaussianProcessRegressor(...)
定义acquisition function
def PI(x, gp, y_max, xi): mean, std = gp.predict(x, return_std=True) z = (mean - y_max - xi)/std return norm.cdf(z) def EI(x, gp, y_max, xi): mean, std = gp.predict(x, return_std=True) a = (mean - y_max - xi) z = a / std return a * norm.cdf(z) + std * norm.pdf(z) def UCB(x, gp, kappa): mean, std = gp.predict(x, return_std=True) return mean + kappa * std
寻找acquisition function最大的对应解,更精细化的可以去优化一下,这里仅展示随机采样的方式。
def acq_max(ac, gp, y_max, bounds, random_state, n_warmup=10000): # 随机采样选择最大值 x_tries = np.random.RandomState(random_state).uniform(bounds[:, 0], bounds[:, 1], size=(n_warmup, bounds.shape[0])) ys = ac(x_tries, gp=gp, y_max=y_max) x_max = x_tries[ys.argmax()] max_acq = ys.max() return x_max
主函数
while iteration < n_iter: # 更新高斯过程的后验分布 self.GP.fit(X, y) # 根据acquisition函数计算下一个试验点 suggestion = acq_max( ac=utility_function, gp=self.GP, y_max=y.max(), bounds=self.bounds, random_state=self.random_state ) # 进行试验(采样),更新观测点集合 X.append(suggestion) y.append(target_func(suggestion)) iteration += 1
编辑:黄飞
-
LABVIEW里面做吉利时的源表的程序时用node是干什么的?node in和node out是干什么的?2017-12-11 2851
-
求大神告知这是干什么的?2018-11-13 2035
-
ar识别图是干什么的2019-08-27 18670
-
覆铜板是干什么的2020-01-07 3210
-
RTCALRMbits.AMASK是干什么的2020-04-30 2099
-
对朴素贝叶斯算法的理解2020-05-15 2424
-
请问抽样定理是干什么的?2020-12-21 2471
-
伺服电机是用来干什么的?2021-09-28 5127
-
如何理解贝叶斯公式2018-02-02 4858
-
晶圆厂是干什么的2018-03-16 110076
-
一文秒懂贝叶斯优化/Bayesian Optimization2021-04-09 18394
-
简述对贝叶斯公式的基本理解2021-10-18 951
-
云服务器是干什么的2024-02-18 3137
-
美国云服务器是干什么的2024-02-19 1467
全部0条评论

快来发表一下你的评论吧 !
