

 英伟达发布新一代H200,搭载HBM3e,推理速度是H100两倍!
英伟达发布新一代H200,搭载HBM3e,推理速度是H100两倍!
描述
电子发烧友网报道(文/李弯弯)日前,英伟达正式宣布,在目前最强AI芯片H100的基础上进行一次大升级,发布新一代H200芯片。H200拥有141GB的内存、4.8TB/秒的带宽,并将与H100相互兼容,在推理速度上几乎达到H100的两倍。H200预计将于明年二季度开始交付。此外,英伟达还透露,下一代Blackwell B100 GPU也将在2024年推出。
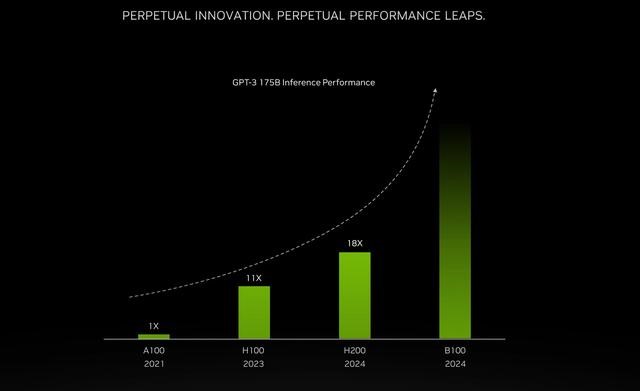
英伟达新发布的H200性能大幅提升(来源:英伟达官网)
首款搭载HBM3e的GPU,推理速度几乎是H100的两倍
与A100和H100相比,H200最大的变化就是内存。搭载世界上最快的内存HBM3e技术的H200在性能上得到了直接提升,141GB的内存几乎是A100和H100最高80GB内存的2倍,4.8TB每秒的带宽达到A100的2.4倍,显著高于H100 3.35TB每秒的带宽。
今年早些时候,就有消息称,包括英伟达在内,全球多个科技巨头都在竞购SK海力士第五代高带宽内存HBM3e。 HBM是由AMD和SK海力士发起的基于3D堆栈工艺的高性能DRAM,适用于高存储器带宽需求的应用场合。如今HBM已经发展出HBM2、HBM2e以及HBM3,HBM3e是HBM3的新一代产品。英伟达、AMD等企业的高端AI芯片大多搭载HBM。
电子发烧友此前报道过,英伟达历代主流训练芯片基本都配置HBM,其2016年发布的首个采用帕斯卡架构的显卡TeslaP100已搭载了HBM2,随后TeslaV100也采用了HBM2;2017年初,英伟达发布的Quadro系列专业卡中的旗舰GP100也采用了HBM2;2021年推出的TeslaA100计算卡也搭载了HBM2E,2022年推出了面向大陆地区的A800,同样也配置HBM2E;2022年推出了市面上最强的面向AI服务器的GPU卡H100,采用的HBM3。
AMD今年6月推出的号称是最强的AI芯片MI300X,就是搭载由SK海力士及三星电子供应的HBM。AMD称,MI300X提供的HBM密度最高是英伟达AI芯片H100的2.4倍,其HBM带宽最高是H100的1.6倍。这意味着,AMD的芯片可以运行比英伟达芯片更大的模型。
如今英伟达新发布的H200搭载HBM3e,可想而知在性能上将会更上一层。H200配备141GB的HBM3e内存,运行速率约为6.25 Gbps,六个HBM3e堆栈为每个GPU带来4.8 TB/s的总带宽。原有的H100配备80GB的HBM3,对应的总带宽为3.35 TB/s,这是一个巨大的进步。相比于H100的SXM版本,H200的SXM版本将内存容量和总带宽分别提高了76%和43%。
英伟达表示,基于与H100相同的Hopper架构,H200将具有H100的一切功能,例如可以用来加速基于Transformer架构搭建的深度学习模型的Transformer Engine功能。
根据其官网信息,H200在大模型Llama 2、GPT-3.5的输出速度上分别是H100的1.9倍和1.6倍,在高性能计算HPC方面的速度更是达到了双核x86 CPU的110倍。
在TF32 Tensor Core(张量核心)中,H200可达到989万亿次浮点运算;INT8张量核心下提供3,958 TFLOPS(每秒3958万亿次的浮点运算)。
不仅如此,基于H200芯片构建的HGX H200加速服务器平台,拥有 NVLink 和 NVSwitch的高速互连支持。8个HGX H200则提供超过32 petaflops(每秒1000万亿次的浮点运算)的FP8深度学习计算和 1.1TB 聚合高带宽内存,可为科学研究和 AI 等应用的工作负载提供更高的性能支持,包括超1750亿参数的大模型训练和推理。
英伟达副总裁Ian Buck表示,为了训练生成式AI和高性能计算应用,必须使用高性能GPU。有了H200,行业领先的AI超级计算平台可以更快地解决一些世界上最重要的挑战。
目前,英伟达的全球合作伙伴服务器制造商生态系统包括华擎 Rack、华硕、戴尔科技、Eviden、技嘉、慧与、英格拉科技、联想、QCT、Supermicro、纬创资通和纬颖科技等,可以直接使用H200更新其现有系统。除了英伟达自己投资的CoreWeave、Lambda和 Vultr之外,亚马逊网络服务、谷歌云、微软 Azure 和甲骨文云等云服务提供商将从明年开始首批部署H200。
如果没有获得出口许可,新H200不会销往中国
这款H200能否对华出口也是大家关心的问题。对此,英伟达表示,如果没有出口许可,新的H200将不会销往中国。去年9月,英伟达高端GPU对中国出口就受到限制,当时英伟达表示,美国通过公司向中国出口A100和H100芯片将需要新的许可证要求,同时DGX或任何其他包含A100或H100芯片的产品,以及未来性能高于A100的芯片都将受到新规管制。
根据美国商务部的法规,其主要限制的是算力和带宽,算力上线是4800 TOPS,带宽上线是600 GB/s。为了应对这个问题,英伟达后来向中国企业提供了替代版本A800和H800。A800的带宽为400GB/s,低于A100的600GB/s,H800据透露约为H100的一半。这意味着A800、H800在进行AI模型训练的时候,需要耗费更长的时间。
然而美国政府认为,H800在某些情况下算力仍然不亚于H100。为了进一步加强对AI芯片的出口管制,美国计划用多项新的标准来替换掉之前针对“带宽参数”。今年10月,美国商务部工业与安全局(BIS)发布更新针对AI芯片的出口管制规定,根据新规定,美国商务部计划引入一项被称为“性能密度”的参数,来防止企业寻找到变通的方案,修订后的出口管制措施将禁止美国企业向中国出售运行速度达到300 teraflops(即每秒可计算 3亿次运算)及以上的数据中心芯片。根据这样的规定,在没有获得许可的情况下,英伟达新发布的H200必然是没有办法向中国企业出售。
事实上,在美国政府今年10月发布的新规下,英伟达不少产品都在限制范围内,包括但并不限于A100、A800、H100、H800、L40、L40 以及RTX 4090。任何集成了一个或多个以上芯片的系统,包括但不限于英伟达DGX、HGX系统,也在新规涵盖范围之内。
针对此情况,有消息称,本月初英伟达已经向经销商公布“中国特供版”HGX H20、L20 PCle、L2 PCle产品信息,分别针对训练、推理和边缘场景,最快将于11月16日公布,量产时间为2023年12月至2024年1月。其中,HGX H20在带宽、计算速度等方面均有所限制,理论综合算力要比英伟达H100降80%左右。
此外,据英特尔供应链透露,英特尔也已经针对最新发布的Gaudi2推出降规版出货,预计将不受新禁令影响。不过无论是英伟达,还是英特尔针对中国市场推出的特供版,可想而知性能必然是会大打折扣的,而且从美国政府的举措来看,特供版是否能够长久供应也是未知数。
总结
可以看到,英伟达此次发布的H100,是全球首款搭载HBM3e的GPU,拥有141GB的内存、4.8TB/秒的带宽,推理速度几乎达到H100的两倍。可想而知,有了H200,当前备受关注的AI大模型的训练和部署应用将会得到更快速地发展。
-
英伟达H200和H100的比较2024-03-07 10331
-
美光新款高频宽记忆体HBM3E将被用于英伟达H2002024-02-28 1520
-
英伟达斥资预购HBM3内存,为H200及超级芯片储备产能2024-01-02 1626
-
英伟达新一代人工智能(AI)芯片HGX H2002023-11-15 2317
-
世界最强AI芯H200发布,英伟达:性能提升90%2023-11-14 2121
-
英伟达h800和h100的区别2023-08-08 57718
-
NVIDIA发布新一代产品—NVIDIA H1002022-03-23 3705
全部0条评论

快来发表一下你的评论吧 !
