

HBM的未来
电子说
描述
01. HBM
高带宽内存(HBM)正在成为超大规模厂商的首选内存,但其在主流市场的最终命运仍然存在疑问。虽然它在数据中心中已经很成熟,并且由于人工智能/机器学习的需求导致使用量不断增加,但其基本设计固有的缺陷阻碍了更广泛的采用。另一方面,HBM 提供结构紧凑的 2.5D 结构尺寸,可大幅减少延迟。
Rambus产品营销高级总监 Frank Ferro 在 Rambus 设计展会上发表演讲时表示:“HBM 的优点在于,可以在可变的范围内获得所有这些带宽,并且表示获得了非常好的功耗。”
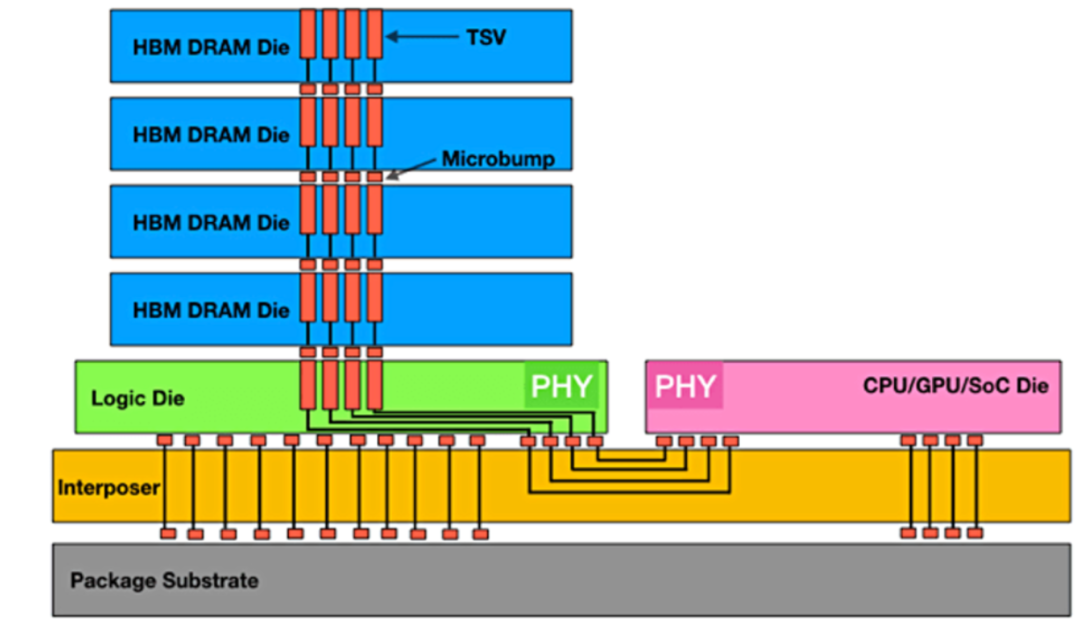
图1:实现最大数据吞吐量的HBM堆栈
“目前困扰高带宽内存的问题之一是成本,”Cadence IP 团队产品营销总监 Marc Greenberg 说道。“3D 成本相当高,相当于有一个逻辑芯片位于芯片的底部,这是你必须支付的额外硅片。然后是硅层,它位于CPU或GPU以及HBM内存的下面。然后,你需要一个更大的封装,等等。目前现存的HBM切割了消费者领域,并更早放置在服务器机房或数据中心,存在许多系统成本。相比之下,GDDR6等图形内存虽然无法提供与HBM一样多的性能,但成本却显着降低。GDDR6的单位成本性能实际上比 HBM 好,但 GDDR6 器件的最大带宽与 HBM 的最大带宽不匹配。”
Greenberg表示,这些差异为公司选择 HBM 提供了令人信服的理由,即使它可能不是他们的第一选择。“HBM 提供充足的带宽,并且每比特传输的能量极低。使用 HBM 是因为你必须这样做,因为没有其他解决方案可以为你提供所需的带宽或所需的功率。”
而且 HBM 只会变得越来越快。“我们预计 HBM3 Gen2 的带宽将提高 50%,”美光计算产品事业部副总裁兼总经理 Praveen Vaidyanathan 说道。“从美光的角度来看,我们预计 HBM3 Gen2产品将在2024财年实现量产。在2024日历年初,我们预计随着时间的流逝,它将开始为收入做出贡献。此外,我们预测美光的HBM3将贡献比DRAM更高利润。”
尽管如此,成本因素可能会像许多设计团队一样考虑更有性价比的替代方案。
Greenberg指出:“如果有任何方法可以将大问题解析为更小的部分,你可能会发现它提高了成本效益。例如,面对一个巨大的问题并且必须在一个硬件上执行所有这些操作,而且我必须在那里使用 HBM,也许我可以将其中断两个部分。让两个进程任务运行,另外一部分可能连接到 DDR6。如果我能够将问题阐释为更小的部分,那么我可能会以更小成本完成相同数量的计算。但如果你需要那么大的带宽,那么 HBM 就是你唯一的选择。”
另一个主要缺点是HBM 的 2.5D 结构会积聚热量,而其放置在接近 CPU 和 GPU 的位置会加剧这种情况。事实上,在尝试给出不良设计的理论样本时,很难想出比当前样本更糟糕的东西,当前布局将 HBM及其热敏 DRAM 堆栈放置在计算密集型热源附近,导致散热很难处理。
“最大的挑战是数据,”Greenberg说。“你有一个CPU,根据定义它会生成大量数据。你通过这个接口每秒T bits,即使每次消耗只有皮焦耳热,但每秒都会执行十亿次计算,因此你的CPU会非常热。它不仅仅是移动周围的数据。它也必须进行计算。最重要的是最不喜欢热的半导体组件,即DRAM。85 ℃左右它开始忘记东西,125℃左右则心不在焉。这是两个完全不同的事情。”
还有一个可取之处。“拥有2.5D堆栈的优势在于,CPU很热,但可以间隔一定物理距离把HBM位于CPU旁边,这样会牺牲延时性能。”他说。
但是Synopsys 内存接口 IP 解决方案产品线总监 Brett Murdock说道,“在延迟和热量之间的权衡中,延迟是不能变的。我没有看到任何人牺牲延迟,我希望他们推动物理团队寻找更多好的冷却方式,或者更好的放置方式,以保持较低的延迟。”
02.HBM和AI
虽然很容易想象计算是 AI/ML 最密集的部分,但如果没有良好的内存架构,这一切都不会发生。需要内存来存储和检索数万亿次计算。事实上,在某种程度上添加更多 CPU 并不会提高系统性能,因为内存带宽无法支持它们。这就是臭名昭着的“内存墙”瓶颈。
Quadric首席营销官 Steve Roddy 表示,从最广泛的定义来看,学习机器只是曲线函数。“在训练运行的每次迭代中,你都在努力越来越接近曲线的最佳函数。这是一个XY图,就像高中几何课一样。大型语言模型基本上是同一件事,但是是100亿维,而不是2维。”
因此,计算相对简单,但内存架构可能非常惊人。
Roddy 解释说:“其中一些模型拥有 1000 亿字节的数据,对于每次重新训练迭代,你都必须通过数据中心的背板从磁盘上取出 1000 亿字节的数据并放入计算箱中。” “在两个月的训练过程中,你必须将这组巨大的内存值来回移动数百万次。限制因素是数据的移入和移出,这就是为什么人们对 HBM 或光学互连从内存传输到计算结构的东西感兴趣。所有这些都是人们投入数亿美元风险投资的地方,因为如果你能进行每周距离或时间,你就可以最大程度地简化每周训练过程,无论是切断电源还是加快速度。”
由于所有这些原因,高带宽内存被认为是 AI/ML 的首选内存。“它提供了一些训练算法所需的最大带宽,”Rambus 的 Ferro 说。“从可以拥有多个内存堆栈从角度来看,它是可配置的,这提供了非常高的带宽。”
这就是人们对 HBM 如此感兴趣的原因。Synopsys的大多数客户都是人工智能客户,所以他们正在 LPDDR5X 接口和 HBM 接口之间进行一项重大的基本权衡。他们忽略了成本。他们真的很渴望 HBM。这是他们对技术的渴望,因为通过HBM能够在一个 SoC 周围创建可以足够大的带宽量。现在,他们可以在SoC 周围放置了 6 个 HBM 堆栈。
然而,人工智能的需求如此之高,以至于HBM减少延迟的前沿特征又推动了下一代HBM的发展。
“延迟正在成为一个真正的问题,”Ferro说。“在 HBM 的前两代中,我没有听到任何人抱怨延迟。现在我们一直收到有关延迟的问题。”
Ferro 建议,抓住当前的限制,了解数据结构极其重要。“它可能是连续的数据,例如视频或语音识别。也可能是事务性的,就像财务数据一样,可能非常随机。如果你知道数据是随机的,那么设置内存接口的方式将与流式传输视频不同。这些是基本问题,但也有层次的问题。我要在内存中使用的字长是多少?内存的块大小是多少?这个了解得越多,你设计系统的效率就越大。如果你了解了,那么你可以定制处理器,从而最大限度地提高计算能力和内存带宽。我们看到越来越多的 ASIC 式 SoC 正在瞄准特定的目标市场剖析市场,以实现更高效的处理。”
降低 HBM 成本将是一项挑战。由于将 TSV 放置在晶圆上的成本很高,因此加工成本已经明显高于标准 DRAM。这使得它无法拥有像标准 DRAM 一样大的市场。由于市场较小,规模经济导致成本在一个自给自足的过程中更高。体积越小,成本越高,但成本越高,使用的体积就越少。没有简单的方法可以解决这个问题。尽管如此,HBM 已经是一个成熟的 JEDEC 标准产品,这是一种独特的 DRAM 技术形式,能够以比 SRAM 低得多的成本提供极高的带宽。它还可以通过封装提供比 SRAM 更高的密度。它会随着时间的推移而改进,就像 DRAM 一样。随着接口的成熟,预计会看到更多巧妙的技巧来提高其速度。
-
HBM3E量产后,第六代HBM4要来了!2024-07-28 7578
-
追求性能提升 使用8GB HBM2显存2016-12-07 4397
-
HBM传感器的安装2020-06-19 3189
-
HBM产品在电机测试中的使用情况2021-01-22 1575
-
DDR内存将死,未来需要高带宽的产品将转向HBM内存2018-03-22 5585
-
ChatGPT带旺HBM存储2023-02-15 6625
-
预计未来两年HBM供应仍将紧张2023-07-07 790
-
HBM出现缺货涨价,又一半导体巨头加入扩产2023-07-08 1967
-
如何加速HBM仿真迭代优化?2023-11-29 2135
-
HBM4为何备受存储行业关注?2023-12-02 1229
-
HBM、HBM2、HBM3和HBM3e技术对比2024-03-01 7551
-
英伟达CEO赞誉三星HBM内存,计划采购2024-03-20 1698
-
台积电准备生产HBM4基础芯片2024-05-21 1756
-
中国AI芯片和HBM市场的未来2024-05-28 2152
-
美光发布HBM4与HBM4E项目新进展2024-12-23 1826
全部0条评论

快来发表一下你的评论吧 !
