

怎样让PPO训练更稳定?早期人类征服RLHF的驯化经验
描述
做一个专门面向年轻NLPer的每周在线论文分享平台
写在前面
今天给大家带来一篇“如何稳定且有效地训练 PPO”的论文解读,来自知乎@何枝(已授权)。在这篇文章中我们将学习:哪些技巧能够稳定训练过程、哪些指标能够代表着训练的顺利进行等内容。
作为 Reinforcement Learning 中的顶流算法,PPO 已经统领这个领域多年。直到InstructGPT的爆火,PPO 开始进军 LLM 领域,凭借其 label-free 的特性不断拔高基座的性能,在 Llama2 、 Baichuan 的工作中都能看到 RLHF 的身影。
于是你开始摩拳擦掌,跃跃欲试,准备利用这项强大的技术来进化自己的基座。但当你信心满满地跑通训练任务时,你看到的情况很有可能是这样的:
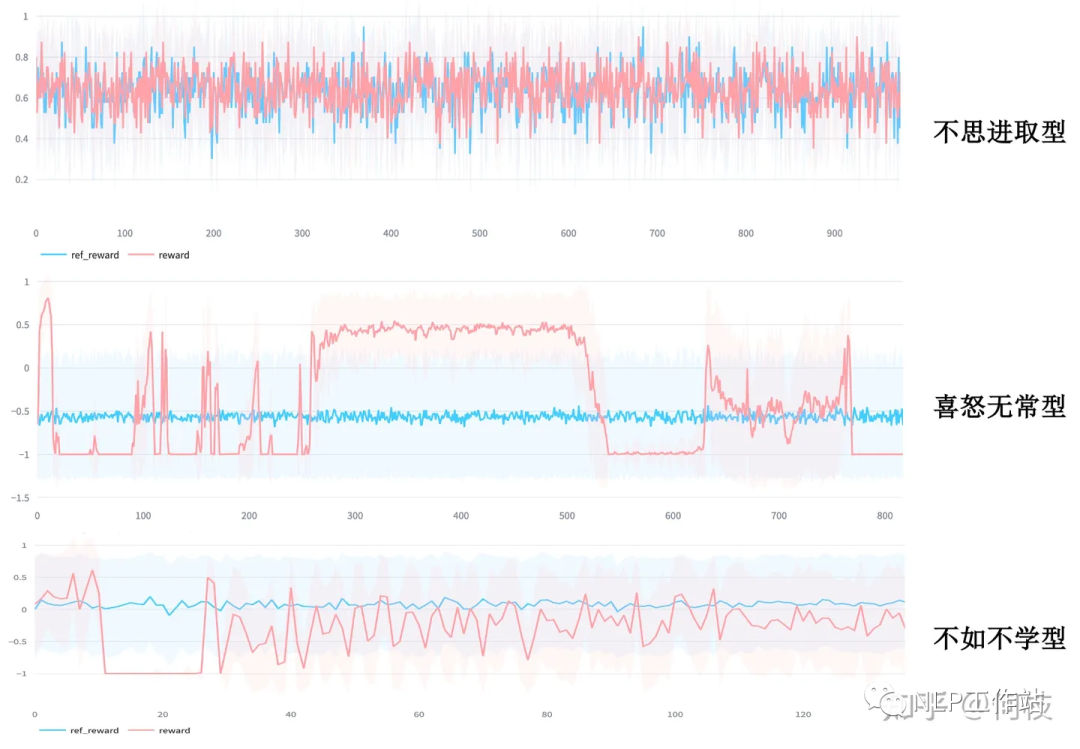 各种形形色色的失败案例
各种形形色色的失败案例尽管鲁迅先生曾言:真的强化敢于直面惨淡的结果,敢于正视崩坏的曲线。但日复一复地开盲盒难免会让人心脏承受不了,好在前人们留下了宝贵的驯化经验,今天让我们一起看看“如何稳定且有效地训练PPO”。
知乎:https://zhuanlan.zhihu.com/p/666455333
Paper:https://arxiv.org/pdf/2307.04964.pdf
Code:https://github.com/OpenLMLab/MOSS-RLHF/tree/main
1. Reward Model 训练
RL 的整个训练目标都是围绕着 reward 来进行,传统 RM 的训练公式为拉开好/坏样本之间的得分差:
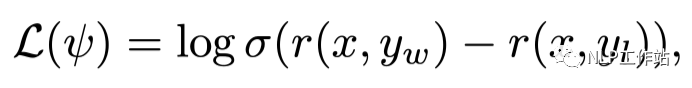 y_w 为 selected 样本,y_l 为 rejecte 样本
y_w 为 selected 样本,y_l 为 rejecte 样本但是,仅仅是「拉开得分差」这一个目标很有可能让 RM 陷入到「钻牛角尖」的困境中。
为了保持住 RM 的本质还是一个「语言模型」,文章在原本的 loss 中加入了对「好样本」的 LM loss:
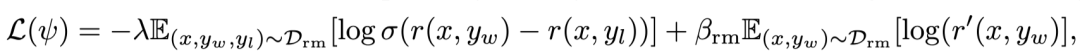 在原来的 loss 基础上顺便学习写出「优秀样本」,保持住模型能写句子的能力
在原来的 loss 基础上顺便学习写出「优秀样本」,保持住模型能写句子的能力值得一提的是:文章中的 r' 是用了另外一个 RM' 来算 loss 的,RM' 的结构和 RM 一样,只不过输出的维度不是 1,而是 vocab_size。但其实我认为也可以使用一个带有 ValueHead 的模型来既训练打分又训练写句子,毕竟这 2 个任务都需要模型知道什么的句子是「好句子」—— 还能省显存。
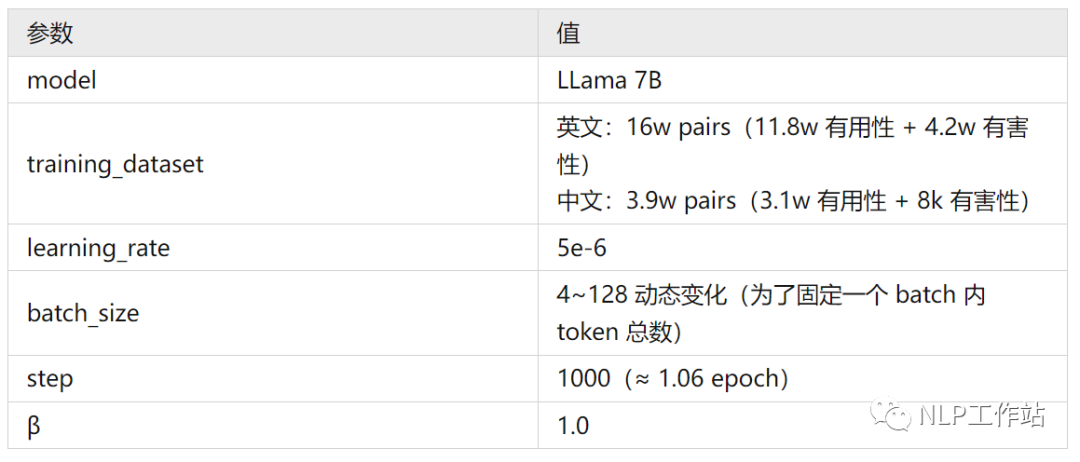
以下是论文训练 RM 的详细参数:
一般的,我们会使用 prefered sample - disprefered sample 的分差来衡量 RM 的效果:
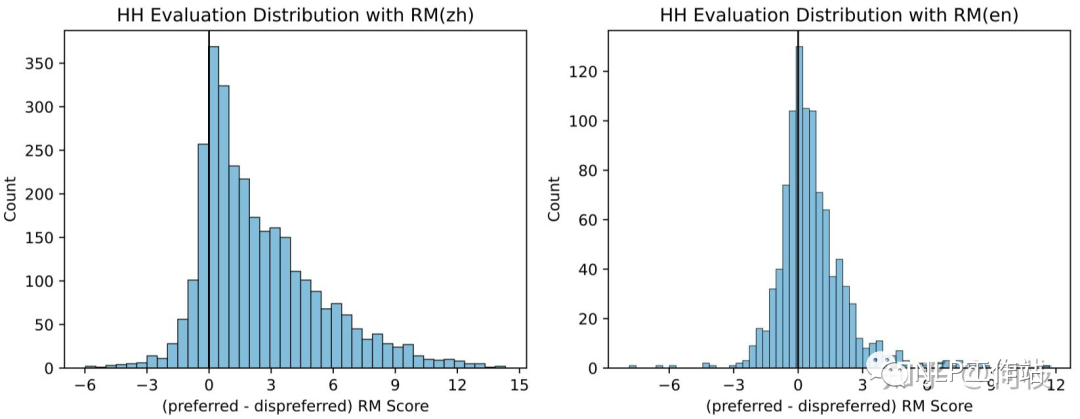 图左为在中文标注数据集上的分差分布,图右为在英文数据集上的分差分布(区分度不如中文)
图左为在中文标注数据集上的分差分布,图右为在英文数据集上的分差分布(区分度不如中文)完全理想的状况下,prefered - disprefered 应该都在 0 的右边(好样本的分数更高),但考虑到标注中的噪声、模型的拟合能力等,存在少小部分 0 左边的样本是合理的,拉出来人工评估下即可。
此外,文中还提到:只看 Acc 并不能够很好的衡量 RM 的性能,但尚未给出其他可以衡量的指标。
2. PPO 的稳定训练方法
2.1 及时发现训练过程中的异常
PPO 训练中很常见的一个问题是「模式崩溃」,其典型特征为:长度很长且无意义的文字。
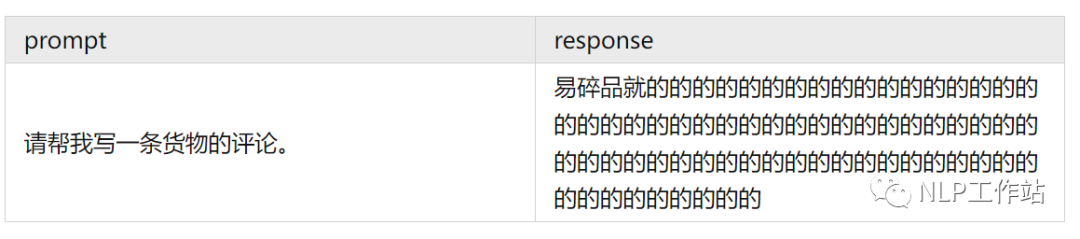
而对于这种「崩溃的输出」Reward Model 往往还容易打出一个很高的分数,这将导致我们无法在训练过程中及时的发现问题,等训完对着一个满意分数的 checkpoint 看生成结果的时候才发现空欢喜一场。
对于上述这种问题,我们可以通过 3 个指标来监控:KL、Response Length、Perplexity。
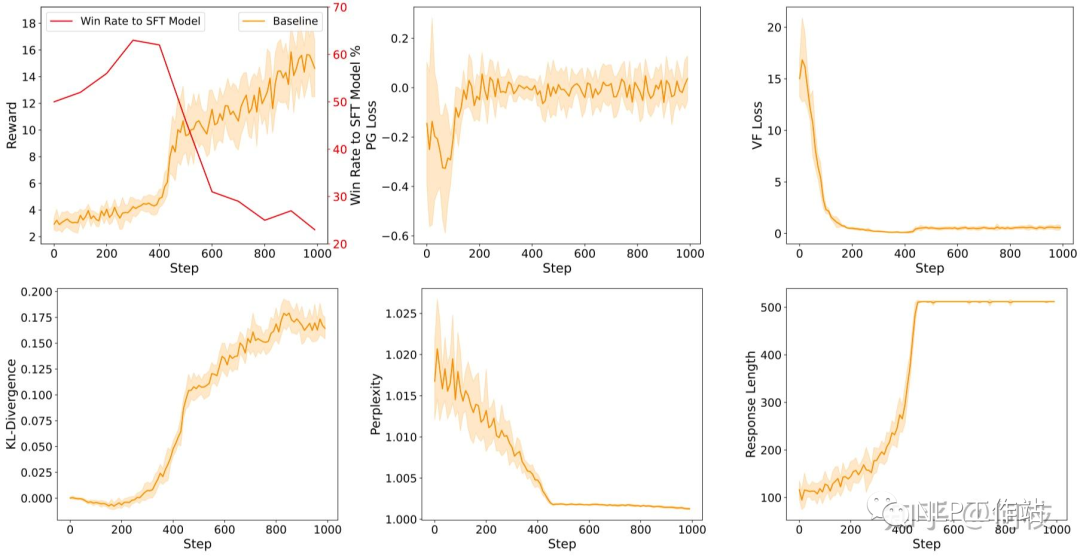 训练过程中的各种指标,从约第 420 step 开始: 1. reward 出现骤增。2. KL 出现骤增。3. Perplexity 出现骤降。4. Response Length 出现骤增。5. 训练效果出现骤降(图左上红线)
训练过程中的各种指标,从约第 420 step 开始: 1. reward 出现骤增。2. KL 出现骤增。3. Perplexity 出现骤降。4. Response Length 出现骤增。5. 训练效果出现骤降(图左上红线)因此我们可以总结出几种指标异常的情况:
- Reward 出现骤增:很可能 Policy Model 找到了某条 shortcut,比如通过模式崩溃来获得更高的分数。
- KL 出现骤增:同上,很可能此时的输出模式已经完全崩溃。
- Perplexity 骤降:由于 PPL 是指代模式对当前生成结果的「确定性」,一般来讲,句子的生成都会带有一定的不确定性,当 Policy Model 对某一个生成结果突然「非常确定」的时候(无论是什么样的上文都很确定接下来应该输出什么),那么它大概率是已经拟合到了一个确定的「崩坏模式」上了。
- Response Length 骤增:这个对应我们之前给的 bad case,回复长度的骤增也可能代表当前输出已经崩溃。
2.2 Score Normalization & Clipping
PPO 的整个训练都是围绕优化 Score 作为目标来进行的,和 Score 相关的变量有 2 个:
- Reward:由 RM(≈ Human) 直接给出的反馈。
- Advantages:由 Reward 和 Critic Model 共同决定的优势值,最终用于 loss 计算。
对于这 2 个值,我们都可以对其进行「归一化」和「裁剪」。
Reward 的处理公式如下:
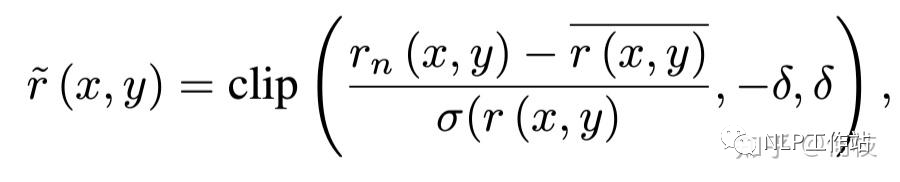 Reward Normalization & Clipping
Reward Normalization & Clipping上述式子将 reward 化成了一个均值为 0 的标准分布,均值为 0 是为了保证在训练过程中得到的正负奖励能够尽可能的均匀,如果一段时间内全为负或全为正从直觉上来讲不太利于模型学习。
文中提到,使用 clipping 可以限制模型进化的「最终分数」没有那么高,鉴于之前「分数越高,并不一定有更好的效果」的结论,作者认为使用 clipping 对最终的效果是有益的。
至于 Advantages,在 PPO 的标准流程里已经会对其进行 Normalization,而 advantage clipping 和 reward clipping 在本质上其实很相似,则只用在 reward 阶段进行截断即可,所以对于 Advantage 来讲不需要做太多其他额外的操作。
2.3 Policy Loss 设计
在传统的 PPO 流程中,我们通常会对 Policy Molde 的 Loss 上做以下 2 种操作:
- Importance Sampling:这是 PPO 中加快 On-Policy 算法训练速度的关键步骤,即一次采样的数据可以进行多次更新(通过系数补偿)。这种方法通常和 KL 惩罚一起使用,实验表明这样能够更加稳定 PPO 的训练,但对最终的效果会存在一定折损(所以最好的还是 1 轮 sample 只做一次 update,退化为原始的 PG 流程)。
- Entropy Loss:一般为了鼓励 Policy 在进化的同时保留「探索」的能力,我们会在 loss 中加入 entropy(确定性)loss,但在 RLHF 中这项设置对超参非常敏感,很容易就崩掉。鉴于 KL 和 Entropy 有着相似的效果,因此作者更推荐使用 KL 来代替 Entropy Loss。
除了上述 2 个传统设置外,RLHF 中加入一个新的指标:Token Level KL-Penalty。
在传统的 RL 流程中,agent 每采取一个 action 后都会得到一个 action reward,对比到文本生成任务中,每新生成一个 token 就等于做出了一次 action,但实际上我们无法每生成一个 token 就打出一个分数,我们只能在一个完整句子(Trajectory)生成完成之后打出一个 Total Reward。
这就比较痛苦了,当我们只有一个长序列的最后得分时,前面的每一个 step 的得分估计就变得非常困难。因此,为了避免「sparse reward」的同时限制 Policy Model 朝着「相对合理的方向」进化,我们会通过计算每个生成 token 与参考模型之间的 KL 来作为单个 token 的 reward 分数。
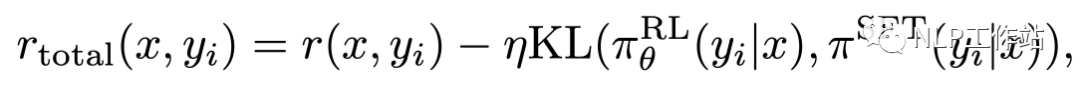 式子的前半部分为 reward(discounted)后半部分为 KL 惩罚分数
式子的前半部分为 reward(discounted)后半部分为 KL 惩罚分数2.4 模型初始化
PPO 继承自 Actor-Critic 框架,因此算法中一共包含 2 个模型:Actor 和 Critic。
- Actor Model(Policy Model)
Policy Model 是指我们最终训练后使用的生成模型,Policy Model 需要具备一定基本的能力才能保证训练的稳定性,通常会选用 SFT 之后的模型。这个比较好理解,如果我们选用 Pretrained Model 为起点的话,探索空间会非常大,同时也更加的不稳定(对 Reward Model 要求更高)。
- Critic Model
一种很直觉的想法是:同样是「评判任务」,我们直接使用 Reward Model 来当作 Critic Model 就好了。
但其实这种想法不完全正确,从本质上来讲 Critic 需要对每一个 token 的状态进行打分,而 RM 是对整个句子进行综合得分评估,这两个任务还是存在一定的区别。
因此,一种更好的方式是:先训练 Critic Model一段时间,直到 Critic Loss 降的相对较低为止。预先训练能够帮助在正式训练的初期 Critic 能够进行较为正确的 value 预估,从而稳定训练过程,至于使用 SFT 还是 RM 作为 Critic 的结构,实验结果显示并没有非常明显的区别。
2.5 最优策略集合(PPO-max)
文章的末尾给出了作者汇聚了各种实验结果给出的一套推荐的策略:
- reward normalize:使用历史获得过的所有 reward 的均值和方差进行标准化。
- token KL penalty:限制模型更新方向。
- Critic Model:使用 RM 初始化 Critic,并在 PPO 正式训练之前先进行 Critic 预训练。
- Global Gradient Clipping
- 使用相对较小的 Experience Buffer。
- Pretrain Loss:在 PPO 训练 loss 中加入 Pretrain Language Model Loss,和 [InstructGPT] 中保持一致。
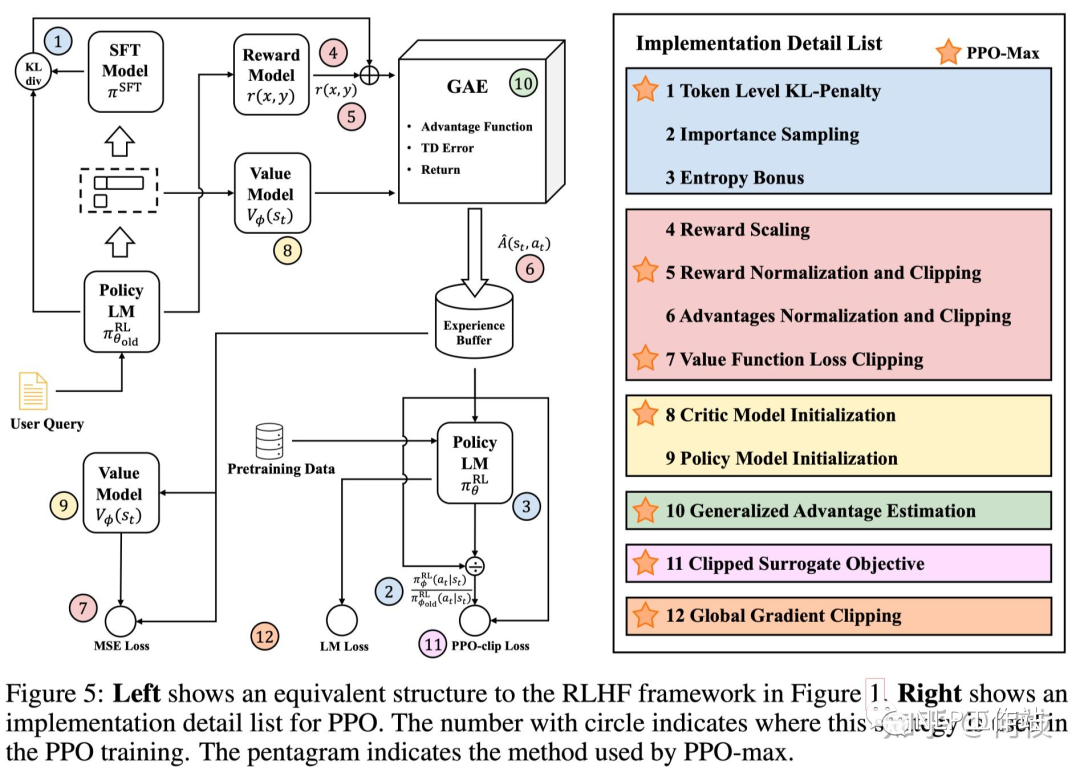 PPO-max 所使用的方法合集(标星的方法)
PPO-max 所使用的方法合集(标星的方法)
-
拆解大语言模型RLHF中的PPO算法2023-12-11 4238
-
tas5711 DRC Time Constants怎样配置出合理的时间使功率压出更稳定?2024-10-21 491
-
altium designer 哪个版本更稳定好用?2013-05-09 28931
-
C-Load TM运算放大器征服不稳定性2019-06-24 1520
-
请问怎么让组件更稳定?2019-08-30 1106
-
STM32与PIC对比分析?哪个更稳定?2023-10-19 704
-
如何让AGP显卡工作得更稳定2010-01-12 843
-
了解如何让您的汽车电池更稳定、运行时间更长2022-11-01 711
-
微软开源“傻瓜式”类ChatGPT模型训练工具2023-04-14 1837
-
怎么让直流调速更稳?2022-03-10 2106
-
RLHF实践中的框架使用与一些坑 (TRL, LMFlow)2023-06-20 4079
-
大语言模型(LLM)预训练数据集调研分析2023-09-19 2465
-
插卡路由器设置教程,让家庭网络更稳定高速!2023-11-29 4169
-
一种基于表征工程的生成式语言大模型人类偏好对齐策略2024-01-03 1596
-
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读2024-01-14 5711
全部0条评论

快来发表一下你的评论吧 !
