

用LLM生成反驳:首先洞察审稿人的心理,再巧妙回应!
描述
在科研领域,同行评审(review-rebuttal)是保证学术质量的关键环节。这一过程中的辩论和反驳非常具有挑战性。传统的同行评审生成任务通常集中在表面层面的推理。研究人员发现,考虑论点背后的态度根源和主题可以提高反驳的有效性。
今天介绍的这篇研究将心理学理论与辩论技术相结合,为计算辩论领域带来了新的视角。具体来说,文章主要做了以下工作:
- 提出了一种全新的同行评审反驳生成任务——柔道辩论(Jiu-Jitsu Argumentation),结合态度根源和主题进行辩论。
- 开发了JITSUPEER数据集,包含丰富的态度根源、主题和典型反驳案例。
- 为同行评审反驳生成提供了强大的基准线。

Paper: Exploring Jiu-Jitsu Argumentation for Writing Peer Review Rebuttals
Link: https://arxiv.org/pdf/2311.03998.pdf
做一个专门面向年轻NLPer的每周在线论文分享平台
Jiu-Jitsu Argumentation
同行评审对于确保科学的高质量至关重要:作者提交研究成果,而审稿人则辩论应不应该接受其发表。通常评审后还会有一个反驳阶段。在这里,作者有机会通过反驳论点来说服审稿人提高他们的评估分数。
这篇文章探索了同行评审领域中态度根源的概念,即在审查科学论文的标准时,识别审稿人的潜在信仰和观点。
作者首先定义典型的rebuttal为:一种与潜在态度根源相一致并解决它们的反驳论点。它足够通用,可以作为模板用于许多相同(态度根源-主题)审稿元组的实例,同时表达特定的反驳行动。
根据这个定义,作者提出了态度根源和主题引导的反驳生成任务:给定一个同行评审论点rev和一个反驳行动a,任务是根据rev的态度根源和主题生成典型反驳c。
下图展示了如何通过一系列中间步骤,将审稿内容映射到标准的反驳上。这个审稿的主要观点是关于清晰度和整体性。
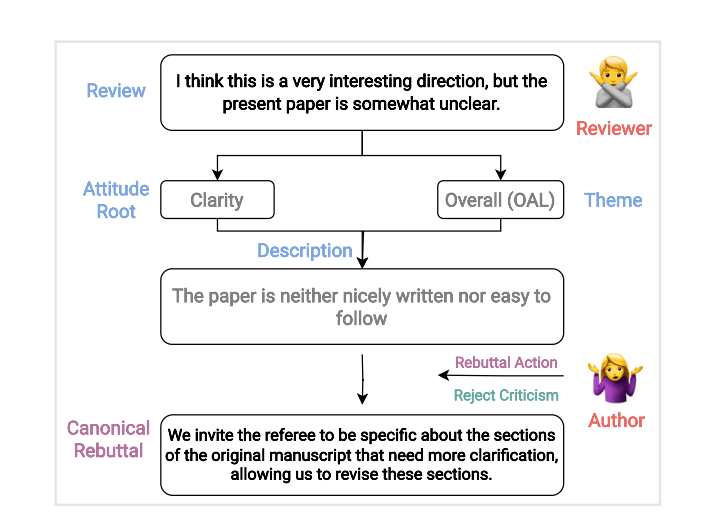
JITSUPEER 数据集
为了评估反驳生成任务,作者构建了JITSUPEER数据集。该数据集专注于同行评审过程中的态度根源和主题,通过连接这些元素与基于特定反驳行动的典型反驳,实现了一种态度和主题引导的反驳生成方法。
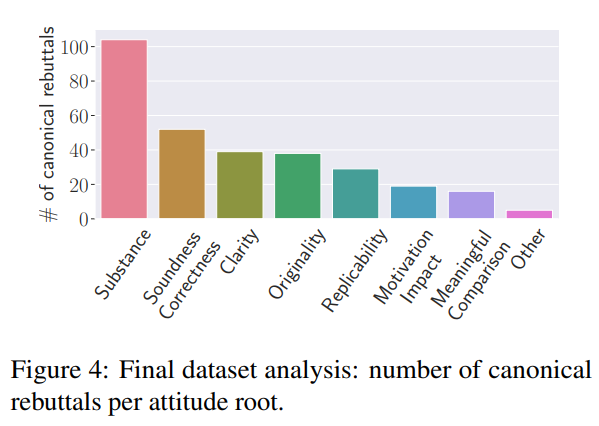
- 态度根源与主题分布: 大多数审稿句子的态度根源是“实质性”(Substance),这也是拥有最多主题(29个)的根源。最常见的主题是方法论(Methodology)、实验(Experiments)和相关工作(Related Work)。这一发现符合直觉,因为机器学习领域的审稿者通常非常关注方法论的稳健性和实用性。
- 典型反驳识别: 研究团队为不同的态度根源和反驳行动识别了302个典型反驳。这些典型反驳可以映射到2,219个审稿句子(总共2,332个)。与“完成任务”(Task Done)这一反驳行动和“实质性”态度根源相关的典型反驳句子数量最多。
- 典型反驳示例: 在报告的表格中,研究团队展示了一些典型反驳的例子。显然,不同的态度根源-主题描述与不同的典型反驳相关联。
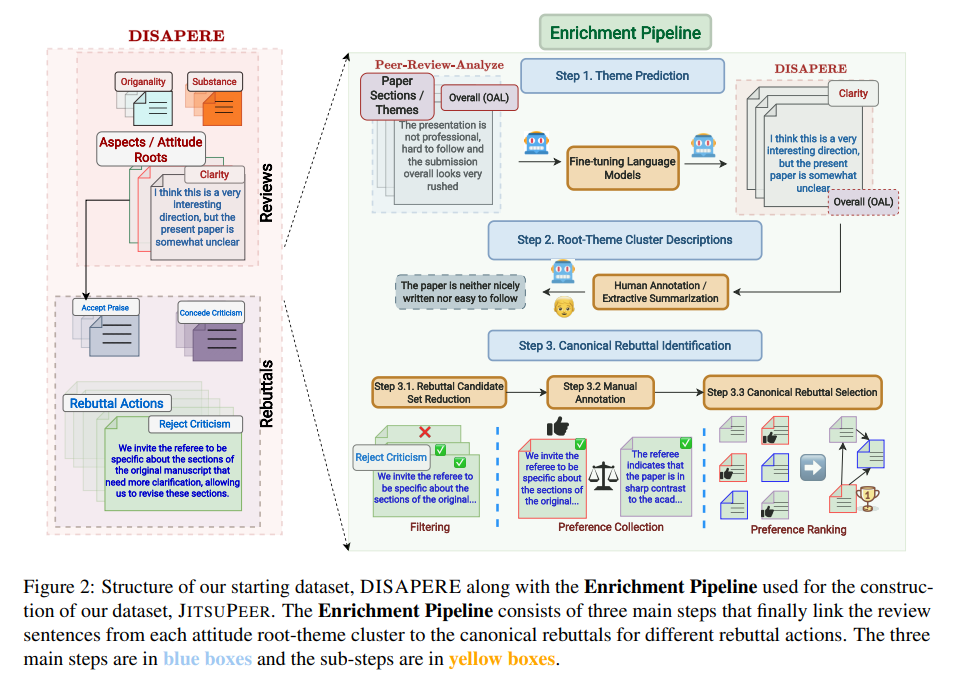
起始数据集
作为JITSUPEER的基础,研究团队采用了名为DISAPERE的数据集,该数据集包含了2019年和2020年ICLR会议的审稿和相应反驳。这些审稿和反驳被细致地分解成单个句子,并被三层注释标记,包括审稿方面和极性、审稿与反驳之间的链接,以及反驳行动的直接注释。特别地,研究团队关注于需要反驳的负面审稿句子,探索了审稿方面的使用,以此来体现社区共享的科学价值观。
此外,研究者还使用了另一数据集PEER-REVIEW-ANALYZE,该数据集是一个基准资源,包含2018年ICLR的审稿,同样配备了多层注释。这些注释包括了审稿句子所指目标论文的特定部分,如方法、问题陈述等,这些信息被视为态度主题的关键元素。这一研究提供了一个独特的视角,通过关注论文的特定部分,进一步丰富了对工作的潜在信仰和主题信息的理解。
数据集丰富化
在这项研究中,研究团队的目标是创建一个详尽的语料库,其中审稿句子不仅被标注为态度根源和主题,而且还与特定反驳行动的典型反驳句子相连接。为了实现这一目标,研究团队采用了一系列方法来丰富DISAPERE数据集。
主题预测
首先,他们使用了PEER-REVIEW-ANALYZE数据集来预测态度主题,即审稿句子中所涉及的论文部分。研究团队测试了不同的模型,包括通用模型和针对同行评审领域的专门模型,如BERT、RoBERTa和SciBERT。他们通过中间层的遮蔽语言模型(MLM)对这些模型进行了领域专门化处理,并在多个配置下进行了训练和优化。研究团队在变压器的顶部添加了sigmoid分类头,以进行微调,并对不同的学习率进行了网格搜索。他们基于验证性能采用早期停止策略,并在PEER-REVIEW-ANALYZE数据集上评估了模型的性能。结果显示,所有变压器模型的性能都显著优于基线模型,其中经过领域专门化处理的SciBERTds_neg模型表现最佳。
根源–主题集群描述
接下来,研究团队对每个态度根源–主题集群添加额外的自然语言描述,旨在提供比单纯标签元组更丰富的人类可解释性。他们通过比较自动和手动生成的摘要来完成这一步骤。
摘要生成:在自动摘要方面,研究团队采用了领域特定的SciBERTds_neg模型对句子进行嵌入,并根据余弦相似度选择最具代表性的审稿句子。
评估: 研究团队通过展示摘要和相应的集群句子给注释者,让他们选择更好地描述集群的摘要。他们使用INCEpTION开发了注释界面,并雇用了额外的计算机科学博士生进行标注。通过测量注释者间的一致性,研究团队确保了摘要的质量和准确性。
确定典型反驳
研究团队为每个态度根源-主题集群确定典型的反驳,这是通过考虑特定的反驳行动来完成的。这一过程分为三个步骤:首先,减少候选典型反驳的数量;其次,手动比较缩减后候选集中的反驳句子对;最后,基于成对比较的分数计算排名,并选择排名最高的候选作为典型反驳。
候选集减少:为了缩减典型反驳的候选集,研究团队采用了两种适用性分类器得出的分数。首先是一个二元分类器,基于自行训练,用于预测一个反驳句子作为典型反驳的整体适用性。其次,考虑到典型反驳的原型性质,他们还使用了SPECIFICITELLER模型来获得特定性分数。该模型是一个预训练的基于特征的模型,用来评估句子是通用的还是具体的。通过这两个步骤,研究团队最终将候选集缩减至1,845个候选。
手动标注:在手动决定典型反驳方面,研究团队设计了一套方法:展示来自特定态度根源和主题集群的≤5个审稿句子,并将这些信息与特定的反驳行动配对。然后,他们随机选择两个反驳句子,这些句子与集群中的任一审稿句子相关,并对应于所选的反驳行动。标注者需要从这对反驳句子中选择更好的一个。对于每个(态度根源、态度主题、反驳行动)三元组的n个反驳句子,成对标注设置需要对n(n − 1)/2对句子进行评判。研究团队雇佣了两名计算机科学博士生进行这项任务。
典型反驳选择:研究团队基于收集的偏好通过注释图排名得出最佳反驳。具体来说,他们为每个根源-主题-行动集群创建了一个有向图,图中的节点是反驳句子。边的方向基于偏好:如果A优于B,则创建A → B的边。然后,他们使用PageRank算法对节点进行排名,每条边的权重为0.5。排名最低的节点,即很少或没有入边的节点,被选为典型反驳。这种方法不仅提高了数据集的质量和实用性,也为未来在类似领域的研究提供了一个有力的方法论参考。
实验分析
研究团队提出了三项新颖的任务,以在其数据集上进行测试。分别是典型反驳评分,审稿意见生成,典型反驳生成。
典型反驳评分
这个任务的目标是给定一个自然语言描述d和一个反驳行动a,对所有反驳r(与特定态度根源-主题集群相关)进行评分,以表明r作为该集群的典型反驳的适用性。
这个任务被视为一个回归问题。只考虑有典型反驳的反驳行动和态度根源-主题集群的组合(50个态度根源-主题集群描述,3,986个反驳句子,其中302个是典型反驳)。使用之前的PageRank分数作为模型训练的预测目标。
结果
-
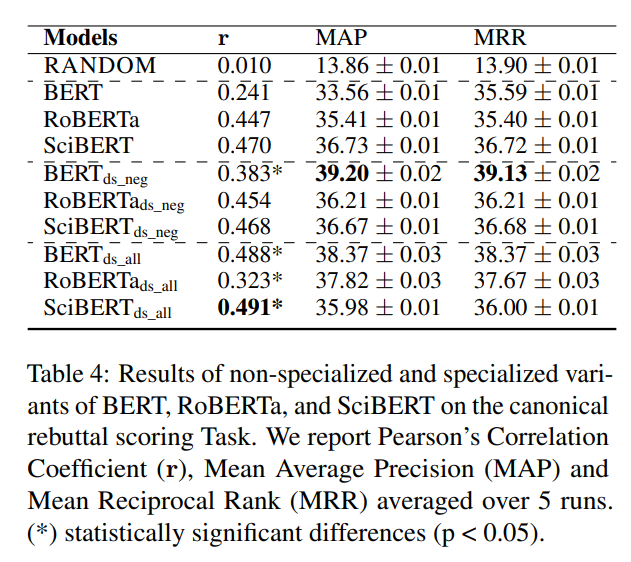
从下表可以看出,大多数领域专门化模型的表现优于它们的非专门化对应模型。
-
SciBERTds_all 在所有方面都有最高的皮尔逊相关系数,然而,BERTds_neg 在排名分数方面表现最佳。
-
使用其他与集群相关的信息,如代表性审稿句子,以及对描述进行释义,可能会带来进一步的收益,这将留待未来研究探究。
审稿描述生成
给定一条同行评审句子rev,任务是生成该句子所属集群的抽象描述d 。
实验设置
- 数据集由2,332个审稿句子组成,每个句子都属于144个集群之一,并且每个集群都有相关的描述。
- 采用70/10/20的训练-验证-测试分割。
- 使用以下序列到序列(seq2seq)模型:BART (bart-large)、Pegasus (pegasus-large) 和 T5 (t5-large)。
- 对训练周期数e∈{1, 2, 3, 4, 5}和学习率λ∈{1 * 10^-4, 5 * 10^-4, 1 * 10^-5}进行网格搜索,批量大小b = 32。
- 使用带有5个束的束搜索作为解码策略。
- 在完全微调设置以及零次和少次(few-shot)场景中进行实验(随机选择次数)。
- 根据词汇重叠和语义相似性(ROUGE-1 (R-1), ROUGE-2 (R-2), ROUGE-L (R-L) 和 BERTscore)报告性能。
结果
- R-1分数展示在下图中,完整结果在表中。
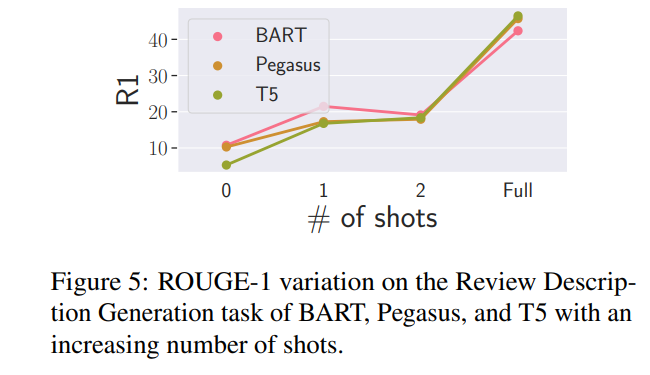
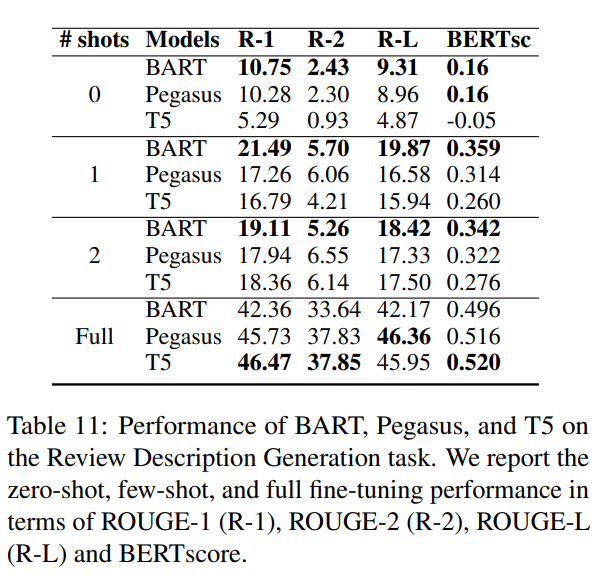
- 有趣的是,所有模型都表现出非常陡峭的学习曲线,在仅看到一个例子时,根据大多数指标,性能大致翻了一番。
- 在zero shot和one shot设置中,BART在所有方面表现出色。
- 但在完全微调模型时,T5的表现最佳。研究团队推测这可能与T5更大的容量有关(BART有406M参数,而T5有770M参数)。
典型反驳生成
给定一条审稿句子rev 和一个反驳a,任务是生成典型反驳c。
实验设置
- 从2,219个有至少一个行动的典型反驳的审稿句子开始。
- 输入为将rev和a与分隔符连接在一起,产生17,873个独特的审稿-反驳行动实例。
- 使用与前面实验相同的超参数、模型和度量标准,并进行完全微调以及零次和少次预测实验。
- 对这些实验,应用70/10/20的训练-验证-测试分割,以获取训练-验证-测试部分,以典型反驳(302个反驳与17,873个独特实例相连)为层次。
结果
- 模型间的差异与之前的发现一致:BART在零次和少次设置中表现出色,T5虽然起点最低,但很快赶上其他模型。
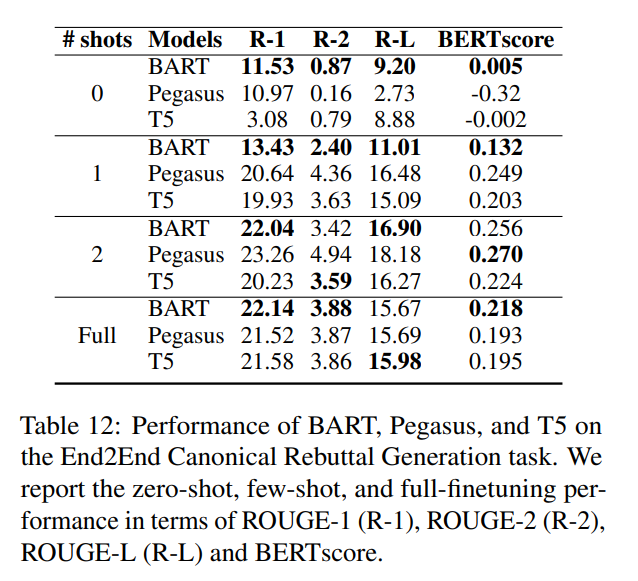
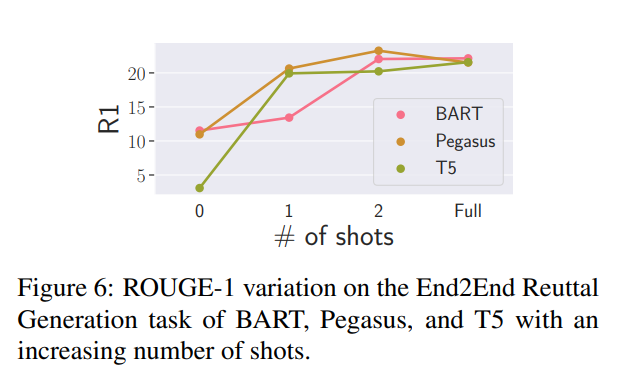
- 模型的表现比以前更加陡峭,并在两次尝试后就似乎达到了一个平台。研究团队认为这与典型反驳的有限多样性有关,以及他们决定在典型反驳层次上进行的训练-测试分割——任务是生成模板,并对这些模板进行概括。看到其中只有几个模板后,模型很快就能抓住一般的要点,但无法超越它们所展示的内容。
结语
在这项工作中,研究团队探索了基于审稿者潜在态度驱动的同行评审中的柔术式论证,为此他们创建了JITSUPEER数据集。这个新颖的数据集包含与典型反驳相连的审稿句子,这些典型反驳可以作为撰写有效同行评审反驳的模板。团队在这个数据集上提出了不同的自然语言处理任务,并对多种基线策略进行了基准测试。JITSUPEER的注释将公开提供,研究团队相信这个数据集将成为促进计算论证领域中有效同行评审反驳写作研究的宝贵资源。
-
LLM模型的应用领域2024-07-09 1878
-
什么是LLM?LLM的工作原理和结构2024-07-02 17964
-
清理华为审稿人事件之后,华为又有人入选IEEE Fellow2020-12-07 3382
-
一封邮件打破了学术界的清净:IEEE禁止华为的同事担任审稿人或编辑!2019-06-07 5354
-
峰回路转 IEEE解除对华为编辑和审稿人限制2019-06-06 3943
-
IEEE“清理华为审稿人”影响几何?2019-06-04 3192
-
NIPS 2018又出事了:审稿信息泄露,双盲评审失效!2018-08-13 9633
-
2016年ei检索源期刊收录出版,加急审稿ja包检索ei论文写发2016-01-29 2330
-
ei源刊检索发表,ei收录论文检索审稿见刊,加急录用ei期刊目录2016-01-21 2415
-
求助论文审稿专家2014-04-16 2061
-
品牌的一个重要基础是人的心理2013-08-02 2314
全部0条评论

快来发表一下你的评论吧 !
