

什么是检索增强生成?
描述
检索增强生成是一种使用从外部来源获取的事实,来提高生成式 AI 模型准确性和可靠性的技术。
为了理解这一生成式 AI 领域的最新进展,让我们以法庭为例。
法官通常根据对法律的一般理解来审理和判决案件。但有些案件需要用到特殊的专业知识,如医疗事故诉讼或劳资纠纷等,因此法官会派法庭书记员去图书馆寻找可以引用的先例和具体案例。
与优秀的法官一样,大语言模型(LLM)能够响应人类的各种查询。但为了能够提供引经据典的权威答案,模型需要一个助手来做一些研究。
AI 的“法庭书记员”就是一个被称为检索增强生成(RAG)的过程。
名称的由来
这个名称来自 2020 年的一篇论文(https://arxiv.org/pdf/2005.11401.pdf),论文的第一作者 Patrick Lewis 对 RAG 这个“不讨喜”的缩写词表示了歉意,如今,这个词被用来描述在数百篇论文和数十种商业服务中不断发展壮大的某种方法,而在他看来,这些都代表着生成式 AI 的未来。
在一场于新加坡举办的数据库开发者区域会议中,Lewis 接受了采访,他提到:“如果我们当时知道研究成果会被如此广泛地使用,肯定会在起名时多花些心思。”

图 1:Partick Lewis
Lewis 现在是 AI 初创企业 Cohere 的 RAG 团队负责人。他表示:“我们当时一直想取一个好听的名字,但到了写论文的时候,大家都想不出更好的了。”
什么是检索增强生成?
检索增强生成是一种使用从外部来源获取的事实,来提高生成式 AI 模型准确性和可靠性的技术。
换言之,它填补了 LLM 工作方式的缺口。LLM 其实是一种神经网络,以其所含参数数量来衡量,参数本质上等同于人类一般的遣词造句方式。
这种深度理解有时被称为参数化知识,使 LLM 能够在瞬间对一般的指令作出响应。但如果用户希望深入了解当前或更加具体的主题,它就不够用了。
结合内部与外部资源
Lewis 与其同事所开发的检索增强生成技术能够连接生成式 AI 服务与外部资源,尤其是那些具有最新技术细节的资源。
这篇论文的共同作者们来自前 Facebook AI Research(现 Meta AI)、伦敦大学学院和纽约大学。由于 RAG 几乎可以被任何 LLM 用于连接任意外部资源,因此他们把 RAG 称为“通用的微调秘方”。
建立用户信任
检索增强生成为模型提供了可以引用的来源,就像研究论文中的脚注一样。这样用户就可以对任何说法进行核实,从而建立起信任。
另外,这种技术还能帮助模型消除用户查询中的歧义,降低模型做出错误猜测的可能性,该现象有时被称为“幻觉”。
RAG 的另一大优势就是相对简单。Lewis 与该论文的其他三位共同作者在博客中表示,开发者只需五行代码就能实现这一流程。
这使得该方法比使用额外的数据集来重新训练模型更快、成本更低,而且还能让用户随时更新新的来源。
如何使用检索增强生成
借助检索增强生成技术,用户基本上可以实现与数据存储库对话,从而获得全新的体验。这意味着用于 RAG 的应用可能是可用数据集数量的数倍。
例如,一个带有医疗数据索引的生成式 AI 模型可以成为医生或护士的得力助手;金融分析师将受益于一个与市场数据连接的“助手”。
实际上,几乎所有企业都可以将其技术或政策手册、视频或日志转化为“知识库”资源,以此增强 LLM。这些资源可以启用客户或现场技术支持、员工培训、开发者生产力等用例。
AWS、IBM、Glean、谷歌、微软、NVIDIA、Oracle 和 Pinecone 等公司正是因为这一巨大的潜力而采用 RAG。
开始使用检索增强生成
为了帮助用户入门,NVIDIA 开发了检索增强生成参考架构(https://docs.nvidia.com/ai-enterprise/workflows-generative-ai/0.1.0/technical-brief.html)。该架构包含一个聊天机器人示例和用户使用这种新方法创建个人应用所需的元素。
该工作流使用了专用于开发和自定义生成式 AI 模型的框架 NVIDIA NeMo,以及用于在生产中运行生成式 AI 模型的软件,例如 NVIDIA Triton 推理服务器和 NVIDIA TensorRT-LLM 等。
这些软件组件均包含在 NVIDIA AI Enterprise 软件平台中,其可加速生产就绪型 AI 的开发和部署,并提供企业所需的安全性、支持和稳定性。
为了让 RAG 工作流获得最佳性能,需要大量内存和算力来移动和处理数据。NVIDIA GH200 Grace Hopper 超级芯片配备 288 GB 高速 HBM3e 内存和每秒 8 千万亿次的算力,堪称最佳的选择,其速度相比使用 CPU 提升了 150 倍。
一旦企业熟悉了 RAG,就可以将各种现成或自定义的 LLM 与内部或外部知识库相结合,创造出各种能够帮助其员工和客户的助手。
RAG 不需要数据中心。在 Windows PC 上已可直接使用 LLM,其实这都要归功于 NVIDIA 软件所提供的支持,使用户可以在笔记本电脑上轻松访问各种应用。

图 2:一个在 PC 上的 RAG 示例应用程序。
配备 NVIDIA RTX GPU 的 PC 如今可以在本地运行一些 AI 模型。通过在 PC 上使用 RAG,用户可以连接私人知识来源(无论是电子邮件、笔记还是文章),以改善响应。这样,用户可以对其数据来源、指令和回答的私密性和安全性放心。
在最近的一篇博客(https://blogs.nvidia.com/blog/tensorrt-llm-windows-stable-diffusion-rtx/)中,就提供了一个在 Windows 上使用 TensorRT-LLM 加速的 RAG 以快速获得更好结果的例子。
检索增强生成的发展史
这项技术的起源至少可以追溯到 20 世纪 70 年代初。当时,信息检索领域的研究人员推出了所谓的问答系统原型,即使用自然语言处理(NLP)访问文本的应用程序,最初涵盖的是棒球等狭隘的主题。
多年以来,这种文本挖掘背后的概念其实一直没有改变。但驱动它们的机器学习引擎却有了显著的发展,从而提高了实用性和受欢迎程度。
20 世纪 90 年代中期,Ask Jeeves 服务(即现在的 Ask.com)以一个穿着考究的男仆作为吉祥物,普及了问答系统。2011 年,IBM 的 Watson 在《危险边缘》(Jeopardy!)节目中轻松击败两位人类冠军,成为电视名人。
如今,LLM 正在将问答系统提升至全新的水平。
在一家伦敦实验室中迸发的灵感
在 2020 年发表这篇开创性的论文时,Lewis 正在伦敦大学学院攻读自然语言处理(NLP)博士学位,并在伦敦一家新成立的 AI 实验室中为 Meta 工作。当时,该团队正在寻找将更多知识加入到 LLM 参数中的方法,并使用模型自己开发的基准来衡量进展。
Lewis 回忆道,团队在早期方法的基础上,受谷歌研究人员一篇论文的启发,“产生了这一绝妙的想法——在一个经过训练的系统中嵌入检索索引,这样它就能学习并生成你想要的任何文本输出。”

图 3:IBM Watson 问答系统在电视节目《危险边缘》(Jeopardy!)中大获全胜,一举成名
Lewis 将这项正在开发的工作与另一个 Meta 团队的优秀检索系统连接,所产生的第一批结果令人大吃一惊。
“我把结果拿给主管看,他惊叹道:‘哇,你们做到了。这可不是常有的事情’。因为这些工作流很难在第一次就被设置正确。”
Lewis 还赞扬了团队成员 Ethan Perez 和 Douwe Kiela 的重要贡献,两人分别来自纽约大学和当时的 Facebook AI 研究院。
这项在 NVIDIA GPU 集群上运行并已完成的工作,展示了如何让生成式 AI 模型更具权威性和可信度。此后,数百篇论文引用了这一研究成果,并在这一活跃的研究领域对相关概念进行了扩展和延伸。
检索增强生成如何工作
NVIDIA 技术简介(https://docs.nvidia.com/ai-enterprise/workflows-generative-ai/0.1.0/technical-brief.html)高度概括了 RAG 流程:
当用户向 LLM 提问时,AI 模型会将查询发送给另一个模型,后者会将查询转换成数字格式以便机器读取。数字版本的查询有时被称为嵌入或向量。
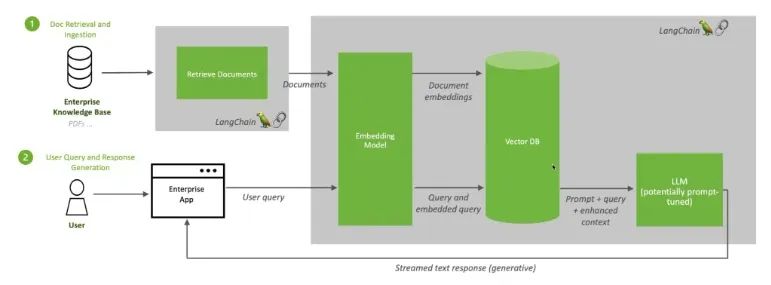
图 4:检索增强生成将 LLM 与嵌入模型和向量数据库相结合。
随后,嵌入模型会将这些数值与可用知识库的机器可读索引中的向量进行比较。当发现存在一个或多个匹配项时,它会检索相关数据,将其转换为人类可读的单词并发送回 LLM。
最后,LLM 会将检索到的单词和它自己对查询的响应相结合,形成最终的答案并提交给用户,其中可能会引用嵌入模型找到的来源。
始终使用最新的资源
在后台,嵌入模型会不断创建并更新机器可读索引(有时被称为向量数据库),以获得经过更新的最新知识库。
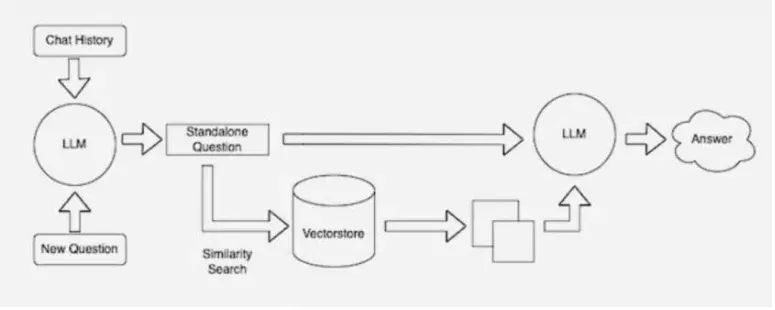
图 5:LangChain 的示意图从另一个角度描述了使用检索流程的 LLM。
许多开发者也发现,LangChain 这个开源程序库特别适合将 LLM、嵌入模型和知识库串联到一起。NVIDIA 在其检索增强生成参考架构中就是使用了 LangChain。
而在 LangChain 社群里,他们也提供了自己的 RAG 流程描述。(https://blog.langchain.dev/tutorial-chatgpt-over-your-data/)
展望未来,生成式 AI 的未来在于其创造性地串联起各种 LLM 和知识库,创造出各种新型助手,并将可以验证的权威结果提供给用户。
也欢迎您访问 NVIDIA LaunchPad (https://www.nvidia.com/en-us/launchpad/ai/generative-ai-knowledge-base-chatbot/)中的实验室,您可以通过 AI 聊天机器人亲身体验检索增强生成。
GTC 2024 将于 2024 年 3 月 18 至 21 日在美国加州圣何塞会议中心举行,线上大会也将同期开放。点击 “阅读原文” 或扫描下方海报二维码,立即注册 GTC 大会。
原文标题:什么是检索增强生成?
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 英伟达
-
用于培训,测试或增强生物识别技术的照片2021-02-18 1317
-
检索增强的语言模型方法的详细剖析2023-08-21 1365
-
检索增强LLM的方案全面的介绍2023-09-08 905
-
NVIDIA 通过企业级生成式 AI 微服务 为聊天机器人、AI 助手和摘要工具带来商业智能2023-11-29 134
-
NVIDIA 通过企业级生成式 AI 微服务为聊天机器人、AI 助手和摘要工具带来商业智能2023-11-29 400
-
高级检索增强生成技术(RAG)全面指南2023-12-25 2407
-
检索增强生成(RAG)如何助力企业为各种企业用例创建高质量的内容?2024-03-29 316
全部0条评论

快来发表一下你的评论吧 !
