

一文解析向量数据库的大模型之路
人工智能
描述
作者:黄楠
向量数据库可实现 80% 非结构化数据能力的覆盖。
在保险行业这个海量数据的“聚居地”上,数据库应用已久。
近年来,保司数据化转型提速,各类文本、音视频的凭证票证核保及跑批需求不断增加,许多机构便将数据库引入至业务流程中。
但是,随着数据库深入保司业务,一个真实的情况是:传统数据库只能处理机器容易处理的、如字符串等结构化数据,以点查和范围查找的形式进行匹配,但面对许多长尾场景下格式繁复、无法统一处理的非结构化数据时,则无能为力,只能继续投入大量人力,进行手动的数据录入和人工检验。
一位从业人员告诉 AI 科技评论,目前在保险公司内人为处理的事情居多,其业务内容中人为比例可达到 90% ,AI 只支持 10% 的信息存取、数据流转。
受技术瓶颈的掣肘,没有一套通用的方法论得以解决传统数据库的存储、检索和分析难题。数据局限的桎梏不仅发生在保险公司里,各行各业均受其困扰已久。直至大模型+向量数据库的出现。
数月来,大模型风口正盛,向量数据库可以为大模型解决数据更新、知识图谱构建、消除幻觉等问题,使其在短短时间内,一跃成为最受关注的领域之一。向量数据库类产品数量激增,当中既有创业公司,大厂更是战局中主要的竞争对手。
今年 7 月,腾讯云发布了 AI 原生向量数据库 Tencent Cloud VectorDB,该产品在 11 月 1 日正式全量开放公测,同时在性能上也实现了大幅提升。
向量数据库之于大模型,是实现降本增效重要的基础设施。数据显示,企业在使用向量数据库后,可实现 80% 非结构化数据能力的覆盖。
大模型的角斗场上,一个行业共识是,谁能够更好地利用数据,把数据沉淀到工程化中里,更快让数据接入到大模型和整个 AI 体系之中,谁就有可能走在最前列。而选择一个对的服务伙伴,至关重要。
1大模型的“数据”局限
众所周知,数据在 MaaS 时代很重要,市场的火热映射到具体的企业行为上,表现为大批量垂直模型的推出、数据库企业融资数量增加、数据库使用量陡然增长等。
但在企业落地的过程中,大模型所面临的难题依旧没有解决。
经过近半年的观察,数据局限对企业做大模型带来的影响,可归结为以下三点:
首先是对数据的管理和运维。如上所述,随着文本、图片、视频等多模态的、非结构化数据的使用需求增加,许多企业所产出的非结构化数据量级可高达 80%,如果选择以预训练的方式将数据“喂”给模型,与之而来的则是难以承载的高成本。
身为明星创业公司的百川智能,在模型训练和调试时就曾遇见过类似问题。
未使用向量数据库之前,百川智能一直使用的是开源方案,比如以向量索引为内核,相当于在训练时给模型准备一个 library 级别或算法级别的知识库,这些知识库使用简单,采用分布式系统的方式,具有扩展性。但其缺点也很直观,随着数量增长到一定规模时,这种分布式存储的方式会很快遇到瓶颈。
不仅如此,由于市面上缺少成熟的管理工具,数据格式该怎么组织、数据的更新频率如何安排、新旧数据的更迭等等,百川智能都需要额外交给工程师去做,大大增加了人员成本。
第二点,虽然大模型支持的 token 数量在持续增加,具备了“短暂记忆”的能力,但“一本正经地胡说八道”的问题仍无法解决,当中不乏有敏感内容的出现,稍不注意,便可能带来严重的影响。因此,支撑模型训练的数据不仅要数量多,质量也必须足够高。
比如大模型和教育行业的结合,虽然模型可以完成一定的推理和解题,但进入实际应用中,好未来就发现了,大模型在面对数学问题时,其表现仍然不够好。要想解决这个问题,必须基于庞大的、高质量的数据库,像教程题库、数学错题集等,在此之上尝试启发式内容生成。
第三,如何保障企业数据的安全性,数据在空间和时间上会有很大的限制。
一方面,企业很难把自己具有核心竞争力的数据放到大模型中去训练;有行业人士就曾向 AI 科技评论指出,许多应用型公司并不愿意将自身微调的模型贡献到公有版本里、与其他人分享,而是倾向于训练自己的大模型,而后进行本地私有化部署。这个过程中,企业要解决的主要难点是,如何将私有化业务数据跟大模型结合。
销售易是很早就在智能 CRM 业务中引入了大模型,例如提供相似客户推荐、做问答机器人等服务。但客户在使用过程时却发现,大模型所推荐的客户类型经常会出现匹配度不高的情况,向它提问与企业相关的的系统功能问题时,大模型也回答不出来。
另一方面,企业的业务数据变化速度快,且实时性强,因此私有化部署后的大模型、在数据层上也很难做到秒、天级别的更新。
当上述诸多问题横亘于企业和大模型落地之间,学术界和工业界也提出了两种解决方案。
一是采用 Fine-tuning 的方式迭代演进,让大模型学到更多的知识;二是通过 Vector search 的方法,把最新的私域知识存在向量数据库中,需要时在向量数据库中做基于语义的向量检索,这两种方法都可以为大模型提供更加精准的答案。
但是从成本方面来看,行业人士指出,向量数据库的成本仅为 Fine-tuning 的千分之一。向量数据库通过把数据向量化,进行存储和查询可以有效解决大模型预训练成本高、没有“长期记忆”、幻觉、知识更新不及时等问题。
因此,凭借其优势,向量数据库也被视为了加速大模型落地行业场景的关键突破口。
2向量数据库的大模型之路
自大模型火爆以来,原已沉寂多年的向量数据库再次受到企业和资本市场的高度关注,据公开数据显示,2023 年 4 月以来,以向量数据库为代表的 AI 投资领域呈增长趋势,包括 Pinecone、Chroma 和 Weviate 等多家向量数据库初创企业均拿到了上亿级美元融资。
为了最大程度上帮助企业应对数据局限问题,更好地将大模型能力释放到行业和产业中,腾讯云走在国内云厂商前列,于今年 7 月便正式上线了向量数据库 Tencent Cloud VectorDB,并在 11 月 1 日全量开放公测。
这也体现了腾讯云在大模型时代下的视角:大模型技术的创新只是第一步,如向量数据库这类数据存储、检索、分析等基础设施的搭建也同等重要,腾讯不仅提供直接的大模型服务,更重要的是向企业递“铲子”、提供有效趁手的平台工具。
市面上不缺乏好用的向量数据库,那么,腾讯云相比于其他厂商的产品有什么不一样的地方呢?
首先在架构上,腾讯云就采用了 AI 原生的开发架构,从接入层、计算层、存储层提供给全面 AI 化的解决方案,形成一套完整的端到端、一站式服务技术栈,让不同阶段、不同需求的用户,都能在腾讯云向量数据库里找到对应可用的 AI 能力。

腾讯云全面 AI 化解决方案
比如在接入层上,腾讯云向量数据库支持自然语言文本的数据,采用“标量+向量”的查询方式,可支持全内存索引;计算层,AI 原生的开发范式能实现全量数据 AI 计算,一站解决企业搭建私域知识库时数据切分等难题。
这些能力不仅可以让交互更自然,同时在计算结果、效率、成本等方面,也能得到进一步的优化。
在百川智能的工程师们看来,向量数据库带来最直观的改变是,数据分片、导入导出等工作效率得到了极大的提升。面对每天约 2 亿的数据量,以往使用的单线程序处理速度有限,但加入了向量数据库后,加上百川智能所使用的RAG 框架,可以有效解决私有数据、实时数据,同时在数据齐备的情况下,还能消除部分由数据带来的幻觉问题。
数据显示,将腾讯云向量数据库用于大模型预训练数据的分类、去重和清洗,相比传统方式可以实现 10 倍效率的提升,如果将向量数据库作为外部知识库用于模型推理,则可以将成本降低 2 - 4 个数量级。
以前企业将现有数据接入一个大模型需要花 1 个月左右时间,使用腾讯云向量数据库后,最短 3 天时间即可完成,极大降低了企业的接入成本。
第二是集成了 Embedding 功能,企业用户无需关注向量生成过程,使用起来更简单。
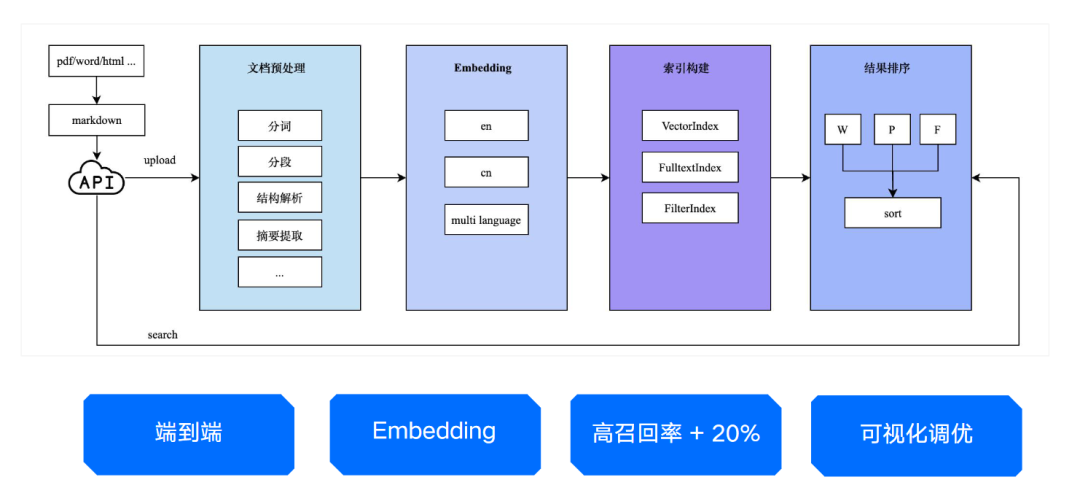
腾讯云向量数据库 AI 套件
与腾讯云合作以前,好未来曾使用过一些小型的基于内存的向量数据库,虽然也具备了语义结合的能力,但无论是产品的性能还是维护等方面,使用效果不佳。
而在腾讯云向量数据库上,通过语音召回加语义 Embedding 功能,这种采用语义结合进行检索的方式,让模型能力得到了提升,召回内容更多、内容更精准、召回速度更快等等,从而提供更好的用户体验。
例如同样是搜索题库中的“第一单元”,文本召回必须准确地提供“第一单元”这一提示词,但借助向量数据库的相似性检索,语义检索就可以将“Unit1”等近似语义的内容也进行召回。
第三,自研分布式向量数据库核心引擎,服务更稳定可靠、高可用。
AI 科技评论了解到,腾讯云向量数据库所用的核心引擎,是其 2019 年于内部上线使用的 Olama,经过 4 年的探索和迭代,Olama 实现了大规模升级,包括集成了腾讯在内的业界优秀的向量算法、降低 Olama 成本、提升稳定性等等,从而更好地适配大语言模型应用。
截至今年 7 月份,Olama 已覆盖腾讯 30 多个业务、100 多个场景,日均调用量超过 1200 亿,调用成功率为 100%,搜索成功率为 99.995%。
可以看到,面对企业在大模型落地中的普遍难题,腾讯云向量数据库力图在每个环节提供便捷、有效的解决方案,突破数据的局限,加速大模型+向量数据库的使用,以解决企业实实在在的痛点和难题。
3应用是风口
受限于研发成本和开发难度,过去十年,全球仅有 1% 开发者专注于 AI 领域的研发工作。而到了今天,以大模型为能力基座,一个 AI 应用开发的难度缩短至只需两三个工程师、一个周末时间变成完成。
其中,向量数据库也从以搜索、广告、推荐为主要服务领域,随着 AI 的大规模发展,开始深入千行百业中去,与 C 端用户链接也更加紧密。
举一个销售易与腾讯云的合作案例。
作为一家企业级 CRM 服务商,每天有数万次用户问答在智能客户场景中发生。在以前,传统的 NLP 客服机器人智能做一问一答,这种基于分词语法关键字的检索方式,容易出现搜索答案不精准的情况,用户使用感不佳,慢慢地也失去了提问的积极性。
比如客户希望在业务分析中检索调用出多个数据报表,想要在成千上万个报表中找到指定数据,对模型的信息抽取能力有很高的需求,直接关系到业务的分析效率。
但在同腾讯云合作后,销售易可以先将报表以 Embedding 的形式存入自有向量数据库中,当用户端发生自然语言问询时,这个客服机器人就可以智能化分析问询者的意图,并在向量数据库内去检索相关的知识文档,从而得出一个更接近于人的思考方式的回答。
这样的客服机器人不仅可以支持多轮对话,更关键的是,它还支持了检索模糊的相关性,不需要维护大量同义词、词典或是相似的问法,类似相关性的语言可以交给大模型+向量数据库来解决。
而在潜在客户推荐的场景中,腾讯云向量数据库带来的影响也十分明显。
过去,销售易主要是依据客户的特征字段,在结构化信息里检索有相关特征的企业信息,这种检索对于内部的销售人员要求很高,必须准确地检索近上百个字段,如企业介绍等描述性内容很难被检测,久而久之,员工经常会出现关键字匹配度不高等问题。
而使用了向量数据库后,基于相关性的特征来检索是从文本进行描述,当销售人员想要检索某个行业、某种产品或是某种业务需求的客户时,可以借助文本进行自然语言模糊的相关性检索,使用简单,检索的结果也更真实、准确,智能化效果明显,大幅提升了员工从事客户推荐业务的难度。

腾讯云超级底座
可以看到,向量数据库之于大模型应用落地、之于 AI 技术发展的意义已经逐渐显现。
腾讯云数据库副总经理罗云就曾指出,数据、向量数据库、大模型三者怎么能更好地服务全行业是首要问题,“只有向量数据库变得更 AI 化,数据、向量数据库、大模型三者才能形成一个飞轮效应,彼此之间相互拉动,相互促进,这是我们对向量数据库未来发展的判断。”
这也是腾讯云在当下推出向量数据库 Tencent Cloud VectorDB 的原因所在。
数据显示,自 7 月份正式发布以来,腾讯云向量数据库的日请求量达 1600 亿次,服务腾讯集团内部 40 多个业务,外部客户数更多达数百家,其中就包括了上述提到的百川智能、好未来、销售易,帮助教育、SaaS、工具、游戏等多行业客户快速进行 AI 方向的探索。
大模型进一步推动了对向量数据库的需求。业界共识是,所有产品应用都值得用 AI 重做一次,在这个背景下,企业将会越来越重视如何将其跟 AI、大模型的能力结合起来。而腾讯云向量数据库在提出之时,就已经看到了企业在应用落地中的痛点,用向量数据库在技术“大脑”中构建起一个健康、且旺盛的“海马体”,为企业迈进大模型时代提供坚实的基座。
这次 Techo Day 技术开放日将资料和课件都整合成了一份《腾讯云工具指南》,这份资料技术含量很高,可以帮助学习了解向量数据库的技术优势和价值应用。
编辑:黄飞
-
腾讯云把向量数据库“卷”到哪一步了?2024-01-15 2689
-
大模型卷价格,向量数据库“卷”什么?2024-05-23 3106
-
图模型和图数据库2021-09-02 1151
-
一文看懂数据库原理与应用2018-03-06 125896
-
如何使用SSD数据库负载实现SQL能耗感知模型2020-07-22 1246
-
Oracle基础教程--数据库模型2021-09-23 931
-
数据库是什么,一文带你入门数据库2022-01-20 1582
-
向量数据库是如何工作的?2023-06-18 1676
-
北美有的,中国也有了!Zilliz Cloud向量数据库云服务重磅登场2023-07-12 2309
-
向量数据库:AI时代的下一个热点2023-08-08 1060
-
什么是向量数据库?关系数据库和向量数据库之间的区别是什么?2023-08-16 4396
-
探寻向量数据库爆火的真相,Zilliz 技术合伙人带你解惑2023-09-28 1186
-
搭载英伟达GPU,全球领先的向量数据库公司Zilliz发布Milvus2.4向量数据库2024-04-01 1938
-
科技云报到:大模型时代下,向量数据库的野望2024-10-14 1035
-
milvus向量数据库的主要特性和应用场景2025-07-04 1366
全部0条评论

快来发表一下你的评论吧 !
