

目标检测算法YOLO的发展史和原理
电子说
描述
01YOLO发展史
大家或许知道,首字母缩写YOLO在英文语境下较为流行的含义,即You Only Live Once,你只能活一次。我们今天要介绍的YOLO却有着与前者不一样的含义。在算法的世界中,YOLO寓意You Only Look Once,你只需要看一眼——这不失为一种来自开发者的罗曼蒂克。
在讲解YOLO的算法原理之前,先简要介绍YOLO的发展史。YOLO开创了一阶段检测算法的先河。它将目标分类和定位用一个神经网络统一起来,实现了端到端的目标检测。
YOLO检测系统
YOLO最初于2016年由华盛顿大学的博士研究生Joseph Redmon提出。Joseph Redmon的这篇提出YOLO的论文You Only Look Once: Unified, Real-Time Object Detection也发表在了CVPR 2016上,并获得了CVPR 2016的最佳人气奖。自此,Joseph Redmon开始不断推出YOLO的新版本,YOLO也在不断的迭代中越来越强。
2017年,Joseph Redmon与导师合著发表了论文YOLO9000: Better, Faster, Stronger,这篇论文也标志着YOLO v2的诞生。该论文获得了CVPR 2017最佳论文荣誉提名奖。YOLO v2能够检测9000中不同的对象,因此也被称为YOLO9000。
2018年,Joseph Redmon又提出了YOLO新版本YOLO v3,这一版本的YOLO在保持原有算法的速度优势的同时,提升了模型的精度,补齐了小目标检测以及重叠遮挡目标识别的短板。虽然,Joseph Redmon在2020年出于个人对职业伦理恪守的原因终止了CV研究,但之后便出现新的YOLO维护者继续接手YOLO的进一步研发项目。
02YOLO算法原理
YOLO的核心理念是:把目标检测问题转换为直接从图像中提取边界框和类别概率的单回归问题,即一次就可检测出目标的类别和位置。正因如此,YOLO模型的运行速度非常快 ,从而可以满足实时性应用要求。
YOLO模型做统一检测(unified detection)的流程为:
YOLO模型
首先,把输入图像分成S×S个小格子。每个格子预测N个边界框,每个边界框用五个预测值表示:x,y,w,h和confidence(置信度)。其中,(x,y)是边界框的中心坐标,w和h是边界框的宽度和高度,这四个值都被归一化到[0,1]区间以便于训练。
置信度会对当前边界框中存在目标的可能性Pr(Object)以及预测框与真实框的交并比进行综合考虑,即

其中

根据以上定义,若一个框内没有物体,则confidence = 0,反之则confidence等于交并比。我们在训练时可以计算出每一个框的置信度。
其次,我们要预测每个格子分别属于每种目标类别的条件概率(|),其中 = 0,1,…,C,其中C是数据集中目标类别的数量。
在测试时,属于某个格子的N个边界框共享C个类别的条件概率,则每个边界框属于某个目标类别的置信度(类别置信度)为
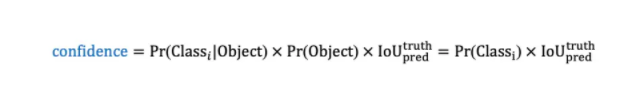
最后,我们会输出一个维度为S×S×(N×5+C) 的张量(tensor)。在此需要提示的是,5代表的是在第一步中对应的五个预测值,且因为每个格子的N个边界框是共享C个类别的条件概率的,因此在张量维度大小的计算公式中,我们在N×5与C之间采用的运算是加法而非乘法。
YOLO使用PASCAL VOC检测数据集。YOLO将图像分为7×7=49个小格子,其中,每个格子里有两个边界框,即S=7,N=2。因为VOC数据集中有20种类别,因此C=20。最终的预测结果是一个7×7×30的张量。
YOLO借鉴了GoogLeNet的设计思想,其网络结构中包括24个卷积层和2个全连接层。YOLO没有使用Inception模块,而是直接用1×1卷积层及随后的3×3卷积层。YOLO的最终输出是7×7×30的张量。
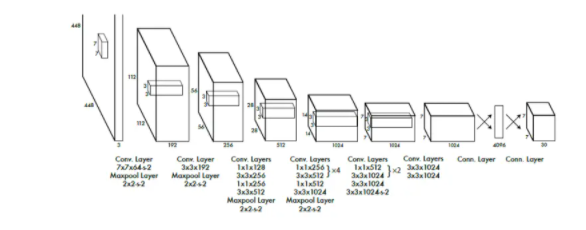
YOLO网络结构
需要强调的是,上图中出现在数字右下角的“-s-2”的下标代表该卷积层或池化层的stride(步距)为2。
此外,YOLO使用Leaky ReLU作为激活函数,即
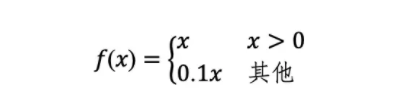
总言之,YOLO算法通过把“统一检测候选框与类别概率”的思想和 “用一个卷积神经网络来实现”的操作结合,从而开创了一阶段目标检测算法。
03YOLO算法的闪光点与局限性
相对于传统目标检测算法而言, 使用统一检测模型的YOLO的闪光点在于:
其一,检测速度非常快。YOLO将目标检测重建为单一回归问题从而对输入图像直接处理。此外,还同时输出边界框坐标和分类概率,而且每张图像只预测98个边界框。因此,YOLO的检测速度非常快。其中,YOLO在Titan X GPU上的检测速度能达到45帧/秒,Fast YOLO的检测速度则可以达到155帧/秒。
其二,背景误判少。以往基于滑动窗口或候选区域提取的目标检测算法只能看到图像的局部信息,因此会把图像背景误认为检测目标。而YOLO在训练和测试时每个格子都可以看到全局信息,因此不容易把图像背景预测为目标。
其三,泛化性更好。YOLO能够学习到目标的泛化表示,从而能够迁移到其他领域。在泛化能力上,YOLO的性能远优于DPM、R-CNN等。
但除了以上闪光点外,YOLO也存在着局限性。虽然YOLO的目标检测速度很快,但其预测精度不是很高。究其原因,主要是由于——
其一,YOLO的每个格子只能预测两个边界框和一种目标的分类。YOLO将一张图像均分为49个格子,若在同一单元格内存在多个物体的中心,那么该单元格内只能预测出一个类别的物体,并丢掉其他的物体,从而降低了预测精度。
其二,损失函数的设计过于简单。虽然边界框的坐标和分类表征的内容不同,但YOLO都用其均方误差作为损失函数。
其三,YOLO直接预测边界框的坐标位置,这会导致模型不易训练。
不过,以上在YOLO原版中出现的问题在后来的YOLO v2、YOLO v3等版本中都逐步得到了改进。
来源: 新机器视觉
审核编辑:汤梓红
-
恒压变压器的发展史2008-07-29 4922
-
PowerPC小目标检测算法怎么实现?2019-08-09 2743
-
Linux系统发展史及版本更迭2020-04-29 3046
-
【大联大世平Intel®神经计算棒NCS2试用申请】基于RK3399+Intel NCS2加速YOLO4目标检测算法加速方案2020-06-30 1712
-
5G的发展史2020-12-24 3560
-
基于YOLOX目标检测算法的改进2023-03-06 1629
-
声卡的发展史2009-12-26 1718
-
基于码本模型的运动目标检测算法2011-05-19 916
-
改进的ViBe运动目标检测算法_刘春2017-03-19 1486
-
基于yolo算法进行改进的高效卫星图像目标检测算法2018-06-01 13404
-
基于深度学习的目标检测算法2021-04-30 11873
-
目标检测—YOLO的重要性!2021-06-10 5053
-
基于Transformer的目标检测算法2023-08-16 1240
-
电阻柜的发展史2024-03-08 1667
-
轩辕智驾红外目标检测算法在汽车领域的应用2025-03-27 1209
全部0条评论

快来发表一下你的评论吧 !
