

地平线Sparse4D与特斯拉对比分析
汽车电子
描述
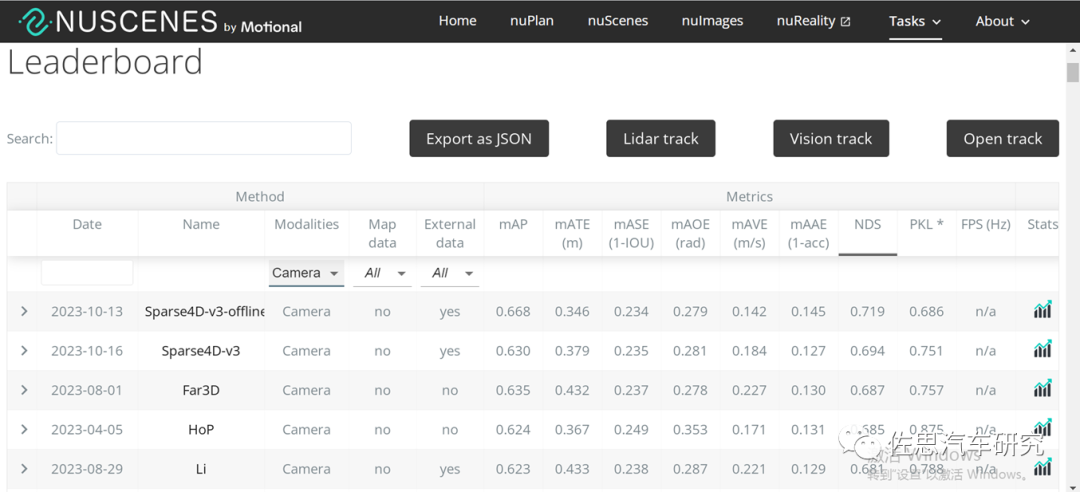
目前学术圈还是用“打榜”来对自动驾驶算法评分,所谓“打榜”是指在某一数据集上利用其训练数据集测试算法的优劣势,目前自动驾驶圈内最常用的打榜数据集是安波福Aptiv旗下的nuScenes。nuScenes数据集的任务包括六大类,分别是3D目标检测(Detection)、目标追踪(Tracking)、目标轨迹预测(Prediction)、激光雷达目标分割(Lidar Segmentation)、全景(Panoptic)、决策(Planning)。
其中,3D目标检测是自动驾驶最基础的任务,全球有近300个团队或企业参加了比试,也是全球自动驾驶数据集参赛者最多的,足见其权威性。华为的TransFusion出自2021年10月,当时也曾在nuScenes数据集上打榜,并夺得第一名的位置,不过最近华为没有打榜。
3D目标检测(Detection)又可分为融合算法和单一传感器算法,其中纯视觉算法第一名就是地平线Sparse4D,NDS得分高达0.719;纯激光雷达算法第一名是浪潮信息和中科院的Real-Aug++,NDS得分是0.744;而激光雷达和视觉融合的第一名是零跑汽车的EA-LSS,NDS得分0.776。不难看出传感器融合性能提升非常有限。很多人会说,特斯拉才是纯视觉第一名,不过根据特斯拉AI Day的资料,特斯拉目标感知算法骨干是META开发的Regnet,脖颈是谷歌的BiFPN,感测头是Transformer,但特斯拉描述的比较模糊,Transformer似乎只是2D到BEV变换。特斯拉的纯视觉基础似乎是来自Facebook的论文《End-to-End Object Detection with Transformers》(发表于2020年5月),稀疏化之后就是DETR3D,2021年10月打榜(实际DETR3D在2020年初就有了),DETR3D曾经打榜,NDS得分0.479,在当年确实是第一,不过第一的位置只保持了近大半年。
再就是什么是所谓端到端。传统的自动驾驶系统通常会采用级联式的架构,在模块与模块之间通常传递的是结构化信息,同时在系统内存在着海量人工设计的复杂规则。这使得整体的自动驾驶系统复杂性高、难以联合优化以及迭代周期比较长。而端到端的设计思路则带来了全新的可能性。在端到端架构中,首先各个主要的模块都是基于神经网络的形式设计;其次模块间也不再只是传递结构化信息,而是同时传递稀疏实例特征表示,这使得从感知到规控的整体系统可以进行联合优化;最终的决策规划模块也能从更加靠前的阶段获得更丰富的信息。BEV就是端到端的典型代表。
还有一种彻底的端到端,就是英伟达在2016年的论文《End to End Learning forSelf-Driving Cars》,不产生中间结果,可以直接通过图像输入,直接输出控制信号的彻底端到端技术路线。貌似很高大上,不过神经网络或者说AI本身就是黑盒,加上这个彻底黑盒的流程,完全不具备任何可解释性,成败完全取决于运气,无法迭代,因此2020年以后再也无人提及。从自动驾驶产品安全性的角度来看,把每个模块都网络化并串联在一起的技术路线,会更加可靠可行,感知的结果必须有显式的。
与科研机构不同,地平线是要考虑产品落地商业化的,从名字就可看出,地平线是要“稀疏”,从图像空间到BEV空间的转换,是稠密特征到稠密特征的重新排列组合,计算量比较大,与图像尺寸以及BEV特征图尺寸成正相关。在大家常用的nuScenes 数据中,感知范围通常是长宽 [-50m, +50m] 的方形区域,然而在实际场景中,我们通常需要达到单向100m,甚至200m的感知距离。若要保持BEV Grid 的分辨率不变,则需要大大增加BEV 特征图的尺寸,从而使得端上计算负担和带宽负担都过重;若保持BEV特征图的尺寸不变,则需要使用更粗的BEV Grid,感知精度就会下降。因此,在车端有限的算力条件下,BEV 方案通常难以实现远距离感知和高分辨率特征的平衡。此外,BEV 空间可以看作是压缩了高度信息的3D空间,这使得BEV范式的方法难以直接完成2D相关的任务,如标志牌和红绿灯检测等,感知系统中仍然要保留图像域的感知模型;这也正是马斯克展示特斯拉的v12版时,红绿灯检测出现明显的错误,Occupancy Network忽略了部分2D相关任务。
特斯拉的OccupancyNetwork在找寻自由空间方面优势明显,策略是避障而非减速刹车,但也有缺点,大量的无意义的静态目标如路两边的建筑物浪费了不少运算资源,按照特斯拉2022 AI Day上的资料,特斯拉的帧率大概是12fps,通常智能驾驶是30fps以上,显然是运算资源不足导致的。
地平线追求一个高性能、高效率的长时序纯稀疏BEV感知算法,既能提高效率也不降低性能。基础还是首个稀疏的BEV感知模型,即DETR3D。《DETR3D:3D Object Detection from Multi-view Images via 3D-to-2D Queries》,作者来自五湖四海,包括麻省理工学院(MIT)、清华大学、卡梅隆大学、理想汽车(不过作者留的邮箱是斯坦福大学,应该还是学生)丰田北美研究院和斯坦福大学。
DETR3D是第一个端到端的目标检测模型,不需要众多手工设计组件,如anchor、固定规则的标签分配策略、NMS后处理等),也是首先将tranformer引入目标检测的。DETR3D模型包含3个关键组件。第一,遵循 2D 视觉中的常见做法,使用共享的 ResNet主干从相机图像中提取特征,视需要使用特征金字塔FPN加强这些特征。第二,一个以几何感知方式将计算的2D特征和3D包络框预测集合进行连接的检测头,检测头的每一层都从一组稀疏的目标查询开始,这些查询是从数据中学习的。每个目标查询编码一个3D位置,该位置投影到相机平面并通过双线性插值用于收集图像特征。DERT类似,然后我们使用多头注意力通过合并目标交互来优化目标查询。这一层会重复多次,在特征采样和目标查询优化之间交替。最后,我们使用set-to-set损失来训练网络。
DETR3D架构
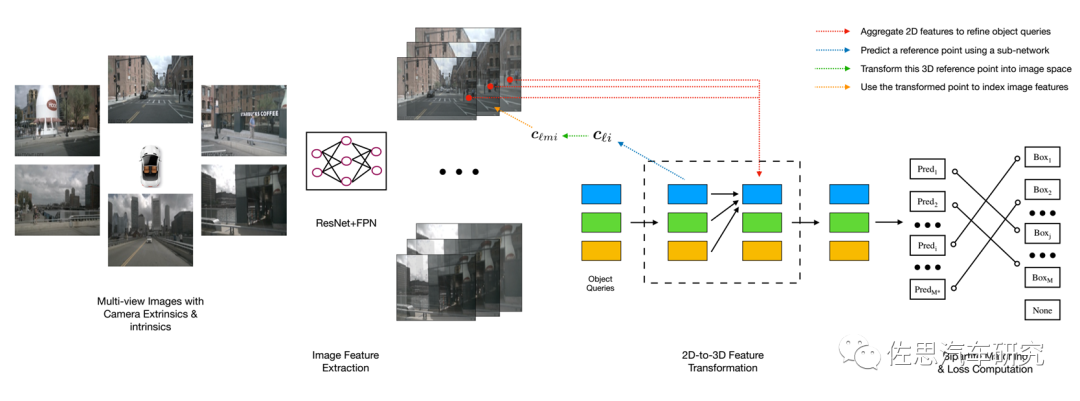
图片来源:网络
与Transformer那种全局(global)&密集(dense)的注意力机制相比,DETR3D提出了新思路:每个参考点仅关注邻域的一组采样点,这些采样点的位置并非固定,而是可学习的(与可变形卷积一样),从而实现了一种局部(local)&稀疏(sparse)的高效注意力机制。Transformer在计算注意力权重时,伴随着高计算量与空间复杂度。特别是在编码器部分,与特征像素点的数量成平方级关系,因此难以处理高分辨率的特征(这点也是DETR检测小目标效果差的原因),说白了就是计算量太大,高分辨率摄像头没法用。DETR的第一波改进就是Deformable DETR。它提出可变形注意力模块,相比于Transformer那种方式,在这里,每个特征像素不必与所有特征像素交互计算,只需要与部分基于采样获得的其它像素交互即可,这就大大加速了模型收敛,同时也降低了计算复杂度与所需的空间资源。另外,该模块能够很方便地应用到多尺度特征上,连FPN都不需要。
地平线做了二次改进,就是Sparse 4D。
Sparse4D概览
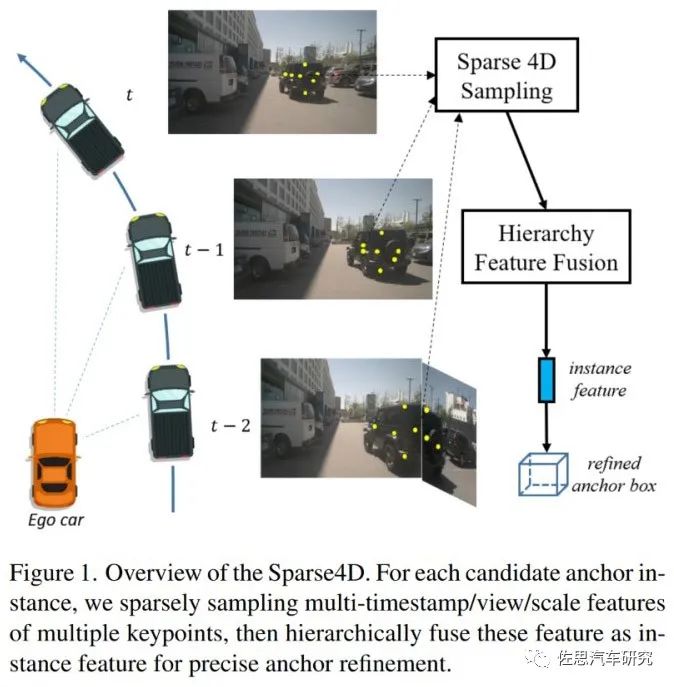
图片来源:地平线
Sparse4D提出instance特征,即实例特征,应该是车的实例,然后重新定义anchor盒尺寸。
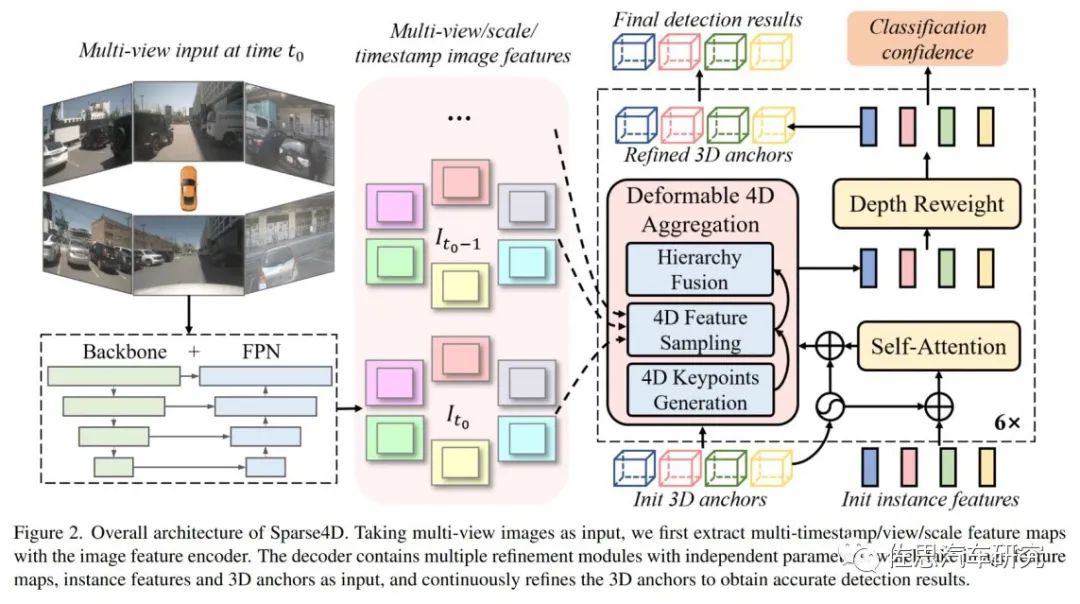
图片来源:地平线
Sparse4D也采用了Encoder-Decoder 结构,其中Encoder包括imagebackbone和neck,用于对多视角图像进行特征提取,得到多视角多尺度特征图。同时,cache 多张历史帧的图像特征用于在decoder 中提取时序特征;Decoder为多层级联形式,输入时序多尺度图像特征图和初始化instance,输出精细化后的instance,每层decoder包含self-attention、deformable aggregation和refine module三个主要部分。
学习2D检测领域DETR改进的经验,重新引入了Anchor的使用,并将待感知的目标定义为instance,每个instance主要由两个部分构成:目标的高维特征,在decoder 中不断由来自于图像特征的采样特征所更新;目标结构化的状态信息,比如3D检测中的目标3D框(x, y, z, w, l, h, yaw, vx, vy);通过kmeans 算法来对anchor 的中心点分布进行初始化;同时,在网络中会基于一个MLP网络来对anchor的结构化状态进行高维空间映射得到 Anchor Embed 并与instance feature 相融合。
Anchor源自RPN,在深度学习时代,大名鼎鼎的RCNN和Fast RCNN依旧依赖滑窗来产生候选框,也就是Selective Search算法,该算法优化了候选框的生成策略,但仍会产生大量的候选框,导致即使是Fast RCNN算法,在GPU上的速度也只有三、四帧每秒。直到Faster RCNN的出现,提出了RPN网络,使用RPN直接预测出候选框的位置。RPN网络一个最重要的概念就是anchor,启发了后面的SSD和YOLOv2等算法,虽然SSD算法称之为default box,也有算法叫做prior box,其实都是同一个概念,他们都是anchor的别称。anchor就是在图像上预设好的不同大小,不同长宽比的参照框。(其实非常类似于上面的滑窗法所设置的窗口大小)。
anchor有点定制的意味,首先你要知道你检测的最重要的目标类型是什么,是车还是小猫,再根据这个确定anchor,大大提高计算效率,也提高准确度,而缺点就是可能出现漏检。对智能驾驶来说,最重要的目标是车和行人,这个anchor很好确定,也可以让网络自己确定。
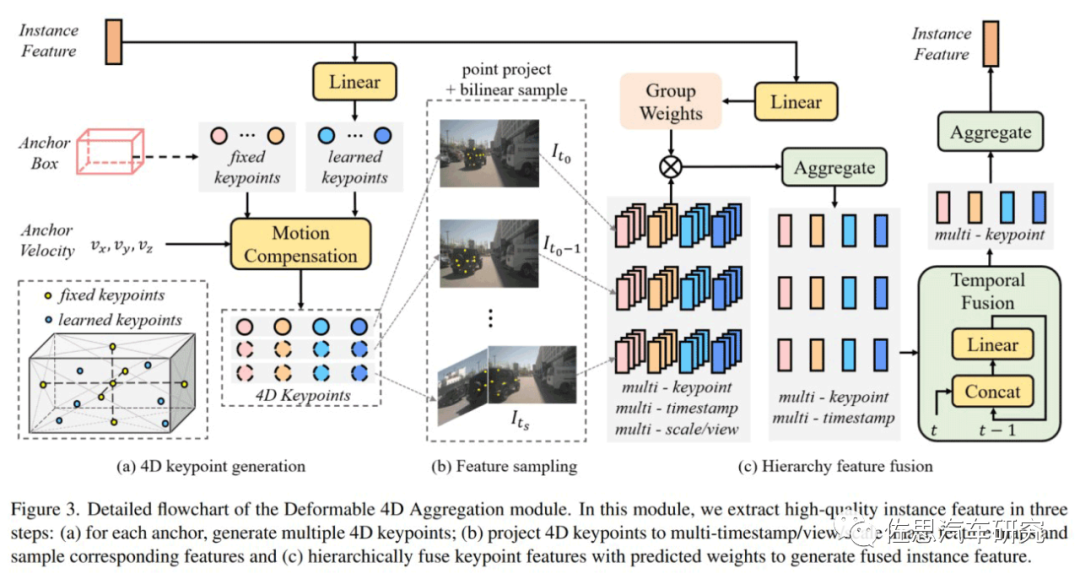
图片来源:地平线
在Sparse4D的decoder 中,最重要的是Deformable 4D Aggreagation模块。这个模块主要负责instance与时序图像特征之间的交互,如上图所示,主要包括三个步骤:
4D关键点生成:首先,基于每个instance的3D anchor信息,生成一系列3D关键点,分为固定关键点和可学习关键点。将固定关键点设置为anchor box的各面中心点及其立体中心点,可学习关键点坐标通过instancefeature接一层全连接网络得到。在Sparse4D 中,采用了7个固定关键点 + 6个可学习关键点的配置。然后结合instance自身的速度信息以及自车的速度信息,对这些3D关键点进行运动补偿,获得其在历史时刻中的位置。结合当前帧和历史帧的3D关键点,我们获得了每个instance的4D关键点。
4D 特征采样:在获得每个instance在当前帧和历史帧的3D关键点后,根据相机的内外参将其投影到对应的多视角多尺度特征图上进行双线性插值采样。从而得到Multi-Keypoint,Multi-Timestamp, Multi-Scale, Multi-View的特征表示。
然后是层级融合,Fuse Multi-Scale/View:对于一个关键点在不同特征尺度和视角上的投影,采用了加权求和的方式,权重系数通过将instance feature和anchor embed输入至全连接网络中得到;Fuse Multi-Timestamp:对于时序特征,采用了简单的recurrent策略(concat + linear)来融合;Fuse Multi-Keypoint:最后,采用求和的方式融合同一个instance不同keypoint的特征。
即便是已经稀疏化、轻量化,由于时间T的导入,依然导致计算量偏大,第一代Sparse 4D使用ResNet50做骨干网,输入图像尺寸704*256,使用英伟达RTX3090显卡,RTX3090拥有10496个CUDA核心,328个Tensor张量核心,FP32算力是35.58TOPS,FP16张量算力是285TOPS,INT8是570TOPS,论FP32算力比A100还高,价格不到A100的1/5。
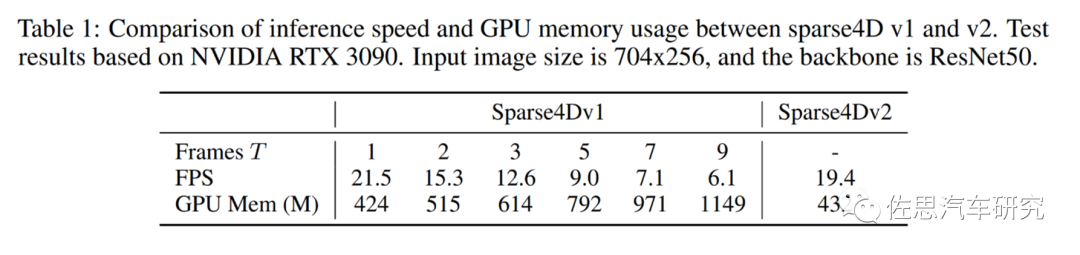
帧率偏低,消耗内存也太多,地平线提出第二代Sparse4D。
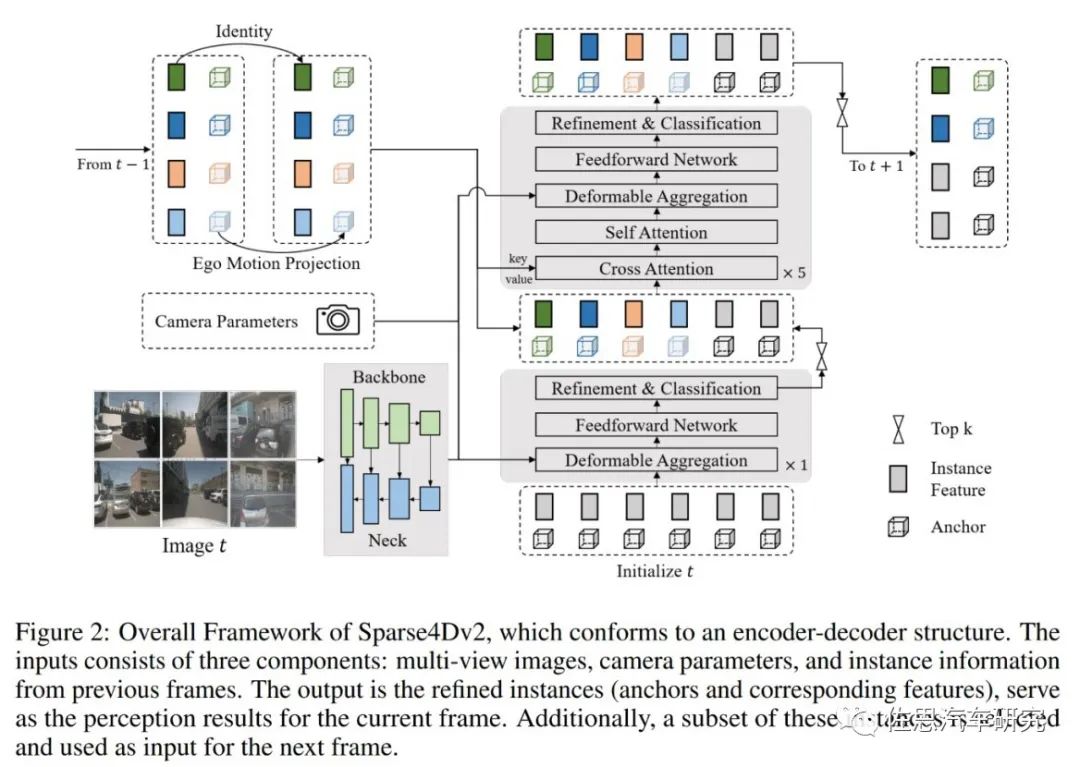
图片来源:地平线
在Sparse4D-V2中,将decoder分为单帧层和时序层。单帧层以新初始化的instance作为输入,输出一部分高置信度的instance至时序层;时序层的instance除了来自于单帧层的输出以外,还来自于历史帧(上一帧)。将历史帧的instance投影至当前帧,其中,instance feature保持不变,anchor box通过自车运动和目标速度投影至当前帧,anchor embed通过对投影后的anchor进行编码得到。这样避免消耗内存的多帧采样,改为历史帧重复利用,用递归recurrent的方式取代了多帧采样。
最新的Sparse4D -V3也已经出现,对骨干网和训练策略都进行了升级,最终达到了纯视觉第一名。
最后要说的是人人都说大模型,实际略大一点的模型无法在车端使用,存储带宽和算力最终变为成本限制,骨干网几乎没有例外都还是2015年微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的ResNet,何恺明后来去了Facebook (Meta),最近又回MIT教书,基本上何凯明引领了计算机目标检测视觉的发展潮流,真正的大神。
自动驾驶需要走的路还很长,感知的问题还未完全解决。不过欣慰的是,中国在感知方面是稳居第一的,如果中国都无法完成自动驾驶,那么其他国家更不可能。
编辑:黄飞
-
地平线RDK系列再升级,NodeHub惊喜发布2023-07-26 2146
-
地平线2020年发生了哪些大事2021-01-27 2804
-
地平线逐渐与上海深度绑定,上海为何看中地平线?2021-02-25 3760
-
比亚迪与地平线宣布达成定点合作2022-04-22 3213
-
比亚迪与地平线正式宣布达成定点合作2022-05-07 3794
-
地平线GitLab使用指导2022-11-04 1987
-
旭日,从地平线升起——地平线旭日X3派开箱试用2022-11-08 3322
-
地平线正式开源Sparse4D算法2024-01-23 2268
-
地平线提交香港IPO申请2024-03-27 1465
-
地平线Journey 3的电源设计2024-09-04 843
-
智驾科技企业地平线登陆港交所2024-10-28 1859
-
地平线SuperDrive首发三大黑科技2025-01-14 1195
-
地平线SuperDrive相关问答2025-01-21 1410
-
博泰车联网与地平线达成战略合作2026-04-27 780
-
地平线亮相2026重庆国际车展2026-06-14 341
全部0条评论

快来发表一下你的评论吧 !
