

13B模型全方位碾压GPT-4?这背后有什么猫腻
描述
你的测试集信息在训练集中泄漏了吗?


论文地址:https://arxiv.org/pdf/2311.04850.pdf
项目地址:https://github.com/lm-sys/llm-decontaminator#detect




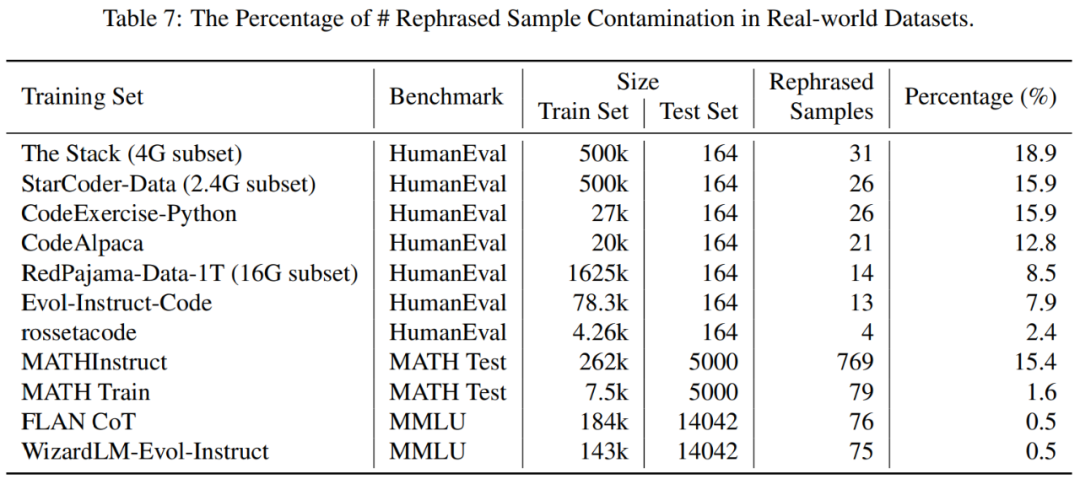

原文标题:13B模型全方位碾压GPT-4?这背后有什么猫腻
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 物联网
-
OpenAI推出新模型CriticGPT,用GPT-4自我纠错2024-06-29 1283
-
微软Copilot全面更新为OpenAI的GPT-4 Turbo模型2024-03-13 1551
-
新火种AI|秒杀GPT-4,狙杀GPT-5,横空出世的Claude 3振奋人心!2024-03-06 1489
-
ChatGPT plus有什么功能?OpenAI 发布 GPT-4 Turbo 目前我们所知道的功能2023-12-13 2234
-
OpenAI最新大模型曝光!剑指多模态,GPT-4之后最大升级!2023-09-20 2011
-
GPT-4没有推理能力吗?2023-08-11 1863
-
OpenAI宣布GPT-4 API全面开放使用!2023-07-12 2043
-
GPT-4创造力竟全面碾压人类!最新创造力测试GPT4排名前1%2023-06-26 1102
-
GPT-4已经会自己设计芯片了吗?2023-06-20 2134
-
最新、最强大的模型GPT-4将向美国政府机构开放2023-06-08 2200
-
GPT-4 的模型结构和训练方法2023-05-22 3722
-
GPT-4是这样搞电机的2023-04-17 1860
-
GPT-4多模态模型发布,对ChatGPT的升级和断崖式领先2023-03-17 4634
-
ChatGPT升级 OpenAI史上最强大模型GPT-4发布2023-03-15 3652
全部0条评论

快来发表一下你的评论吧 !
